正则(RE)能干什么
RE 由两部分组成,分工合作
- 正则表达式:表达具备指定结构的任意字符串,可以将这些字符串看作正则表达式的目标字符串
- 正则引擎:可以在字符串中解析正则表达式,提供诸如查找,替换,验证,分割字符串等操作
正则表达式语法



正则引擎基础工作机制
正则引擎内部会生成正则表达式对应的有穷状态自动机(DFA 或 NFA),这两种状态机特性不同导致所能提供的功能也不相同,需要开发者自行取舍。
NFA: 分支匹配左侧优先,对于 ab|abc,如果 ab 匹配,不会尝试更长的 abc
NFA(非确定性有穷状态自动机):状态变化存在不确定性,如 s2 可能转为 s3 或 s1,因为该状态的转变无需输入
NFA 引擎的工作方式是,先看正则,再看文本,而且以正则为主导。它内部使用贪心匹配回溯算法实现。NFA 通过构造特定扩展,支持子组和反向引用。
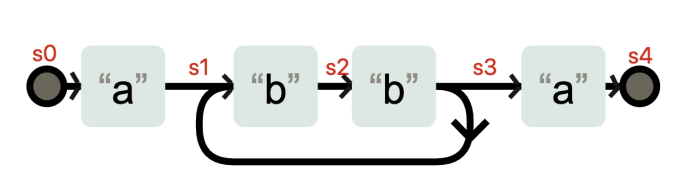
DFA(确定性有穷状态自动机):任何状态变化都需要输入,所以具备确定性
DFA 引擎的工作方式是,先看文本,再看正则表达式,是以文本为主导的。字符串只看一遍,不会发生回溯,相同的字符不会被测试两次。但由于 DFA 引擎只包含有限的状态,所以它没有反向引用功能;并且因为它不构造显示扩展,它也不支持捕获子组
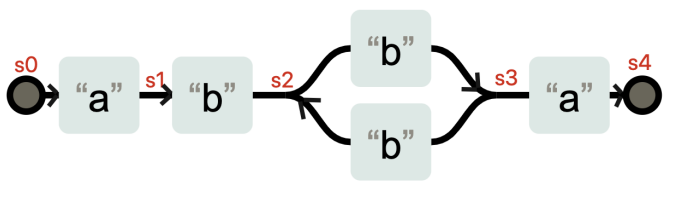
POSIX NFA,因为传统的 NFA 引擎“急于”报告匹配结果,找到第一个匹配上的就返回了,所以可能会导致还有更长的匹配未被发现。比如使用正则 pos|posix 在文本 posix 中进行匹配,传统的 NFA 从文本中找到的是 pos,而不是 posix,而 POSIX NFA 找到的是 posix。但是POSIX NFA 更慢!

回溯
回溯是 NFA 引擎才有的,并且只有在正则中出现量词或多选分支结构时,才可能会发生回溯。



其他
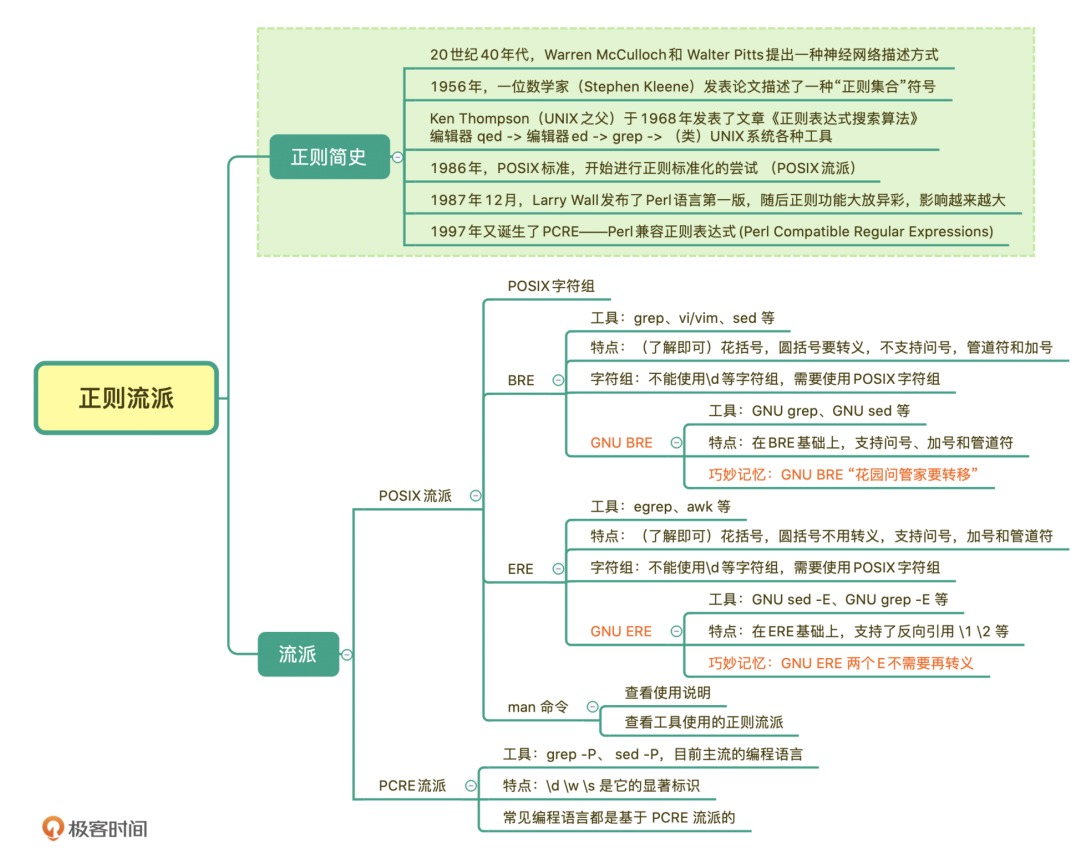
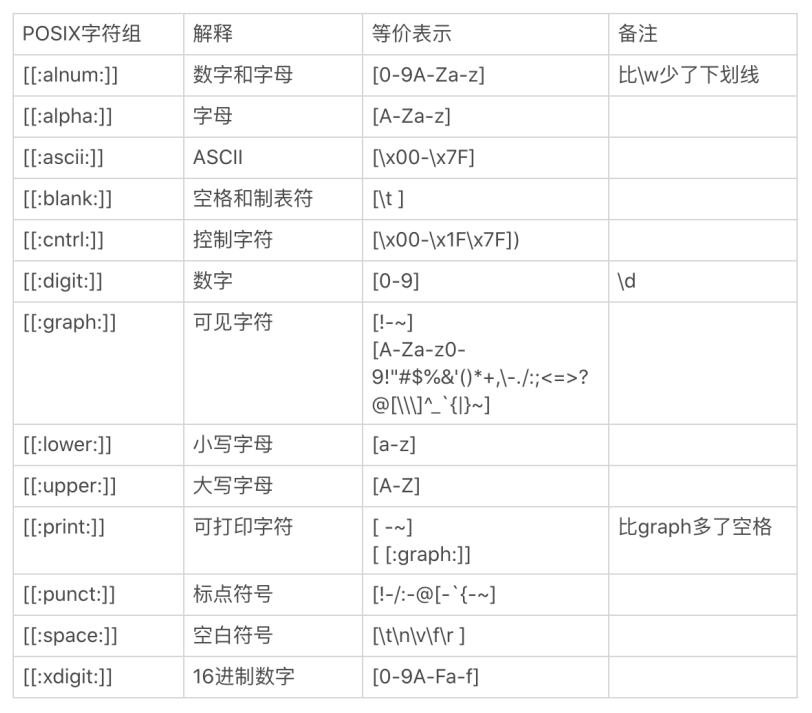
正则流派
Unicode
优化
