前言 近十年,深度学习获得长足发展,大量的研究论文和想法铺天盖地。本文回顾历年来突出的深度学习理念,总结了若干个经得起时间考验的方法,它们已经被反复使用,被广泛证明是有效的。
本文转载自幻方AI
作者 | Denny
仅用于学术分享,若侵权请联系删除
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
深度学习有个特点,就是其应用领域(如:视觉、自然语言、语音、RL 等)可以共享大多数基础技术。例如,一个在 CV 领域工作的人可以很快在 NLP 研究中取得成绩。虽然到具体的网络架构上可能会有所不同,但其理念和方法是基本相同的。因此按照历史顺序学习这些经典的深度学习理论,可以了解当前技术的来源以及它们最初被发明的原因,帮助我们更深入的理解所从事的项目。
本文中我们将尝试介绍来自各个领域的经典理念。在此之前有一些注意事项:
- 我们的目标是简要概述每种技术和它的历史背景,给出论文和复现的地址。如果你想了解更多,我们建议你尝试在 PyTorch 中从头开始复现论文,而不使用现有的代码库或高级库;
- 这些经典理念的整理偏向于我们自己熟悉的知识领域。还有很多令人兴奋的子领域我们没有接触过。我们囊括的主流领域包括:视觉、自然语言、语音、强化学习、游戏;
- 我们只讨论官方或半官方的开源实现。有些研究不容易复现,因为它涉及巨大的工程挑战,例如 DeepMind 的 AlphaGo 或 OpenAI 的 Dota2 AI,所以我们不会在这里强调它。
- 案例模型的选择是随机的。有些类似的技术大约在同一时间发布,例如,可能有数百种 GAN 变体,但要理解 GAN 的一般理念,你研究哪一种并不重要。本文的目标不是全面的回顾,而是探寻深度学习技术背后的理念。
2012
使用 AlexNet 和 Dropout 处理 ImageNet
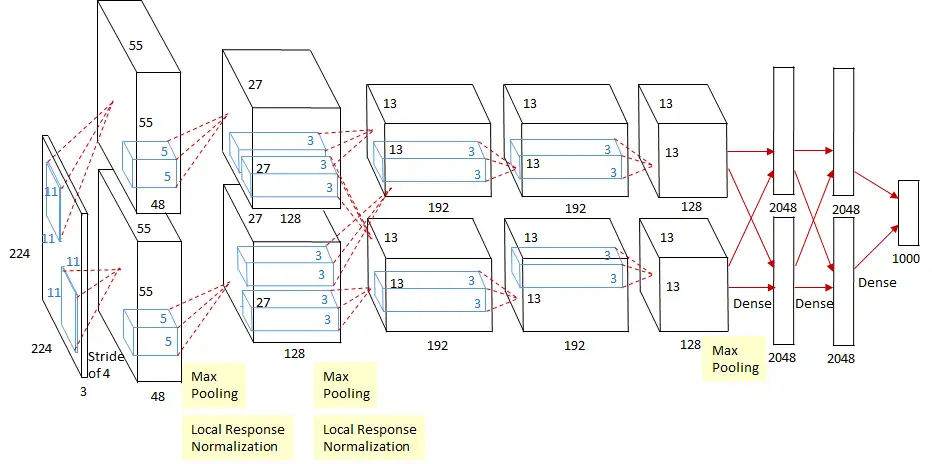
AlexNet 被广泛认为是推动深度学习和人工智能研究热潮的算法,它是基于 Yann LeCun 早期研发的 LeNet 而优化的深度卷积神经网络。AlexNet 可以结合 GPU 的能力,在 ImageNet 数据集中图像分类任务上以显著优势击败了以前的方法。它证明了深度神经网络确实有效!AlexNet 也是第一次使用 Dropout,通过防止特征检测器的协同自适应来改进神经网络,这已成为提高各种深度学习模型泛化能力的关键组成部分。
AlexNet 的体系结构,包含一系列卷积层、ReLU 非线性层和最大池化层,成为未来 CV 体系结构的公认标准。
论文:
- ImageNet Classification with Deep Convolutional Neural Networks
- Improving neural networks by preventing co-adaptation of feature detectors
- One weird trick for parallelizing convolutional neural networks
代码:
2013
使用深度强化学习玩 Atari
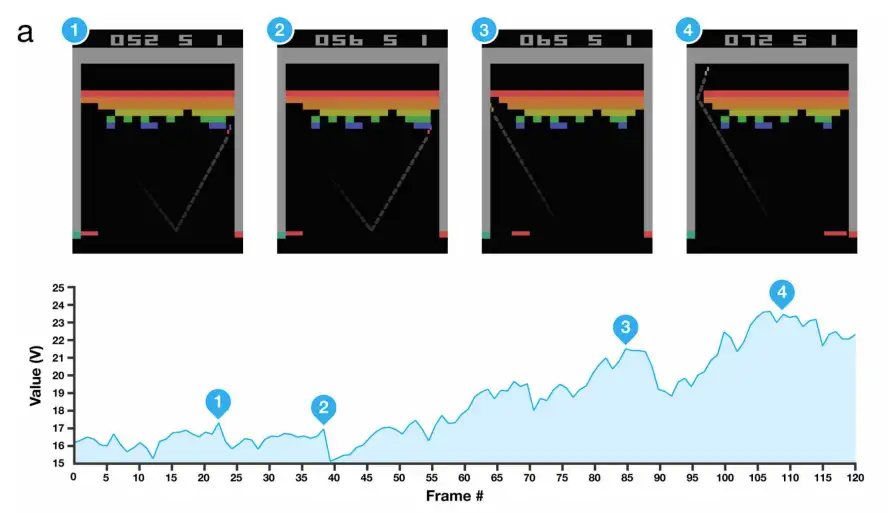
在图像识别和 GPU 突破的基础上,DeepMind 的一个团队成功地训练了一个网络,用原始像素输入玩 Atari 游戏。相同的神经网络架构在没有被告知任何特定游戏规则的情况下学会了玩七种不同的游戏,这证明了该方法的通用性。
强化学习与监督学习(如图像分类)的不同之处在于,模型必须在多个时间步长内最大化奖励的总和,如赢得游戏,而不是预测标签。由于模型直接与环境交互,并且每个动作都会影响下一个动作,因此训练数据不是独立且同分布的,这可能会使机器学习模型的训练变得不稳定。深度强化学习提出通过经验回放等技术来解决这个问题。
虽然没有明显的理念创新,但这项研究巧妙地将现有技术、在 GPU 上训练的卷积神经网络和经验回放与一些数据处理技巧相结合,取得了令人印象深刻的结果。这让人们有信心扩展深度强化学习技术,以处理更复杂的任务,如围棋、Dota 2、星际争霸等。
Atari 游戏自此成为强化学习研究的标准基准。最初的方法只在七款游戏上击败了人类的标准,但在后来几年,基于这些理念的进步开始在越来越多的游戏中击败人类。
论文:
- Playing Atari with Deep Reinforcement Learning
代码:
2014
基于注意力机制的“编码-解码”网络
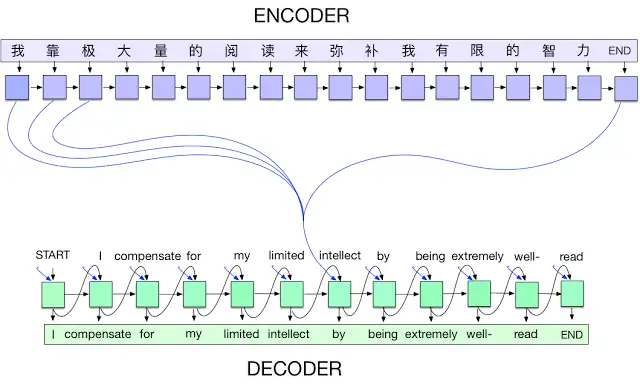
最开始,深度学习令人印象深刻的成果主要集中在 CV 相关的任务上,并由卷积神经网络驱动。虽然 NLP 社区在使用 LSTM 网络和“编码-解码”架构进行语言建模和翻译方面取得了成功,但直到注意力机制的发明,相关技术的发展才开始变得异常顺利。
在处理语言时,每个 token(可以是字符、单词或介于两者之间的东西)都被输入到一个递归网络中,例如 LSTM,它维护了一种内存以记忆以前处理过的输入。换句话说,一个句子非常类似于一个时间序列,每个记号都是一个时间步长。这样的递归模型往往很难处理长时间范围内的依赖关系。当他们处理一个序列时,他们很容易“忘记”以前的输入,因为梯度需要通过许多时间步长传播。用梯度下降来优化这些模型是很困难的。
注意力机制有助于缓解这个问题。它为网络提供了一个选项,通过引入快捷连接,自适应地“回顾”早期的时间步骤。这些连接允许网络在产生特定输出时决定哪些输入是重要的。典型的场景是翻译:当产生一个输出单词时,它通常能映射到一个或多个特定的输入单词。
论文:
- Sequence to Sequence Learning with Neural Networks
- Neural Machine Translation by Jointly Learning to Align and Translate
代码:
2014
Adam 优化器
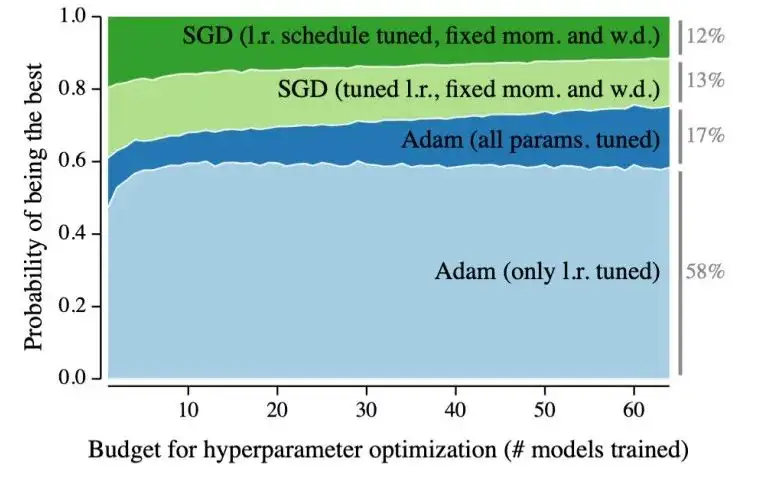
神经网络的训练是通过使用优化器最小化损失函数来进行的。优化器负责弄清楚如何调整网络的参数,使模型更接近目标。大多数优化器都是基于随机梯度下降(SGD)。然而,这些优化器中包含了很多可调参数,例如学习率本身。为特定问题找到合适的参数非常关键,因为这不仅减少了训练时间,而且可以帮助模型找到更好的局部最小值,从而获得更好的结果。
过去深度学习研究通常使用复杂的学习率计划进行昂贵的超参数搜索,以充分利用简单但对超参数敏感的优化器,如 SGD。当它们超过现有的基准时,有时是花费大量成本来调整优化器的结果。这些细节通常不会在已发表的研究论文中提及。
Adam 优化器提出使用梯度的第一和第二矩来自动调整学习速率,其结果相当稳健,并且对超参数选择不那么敏感。换句话说,Adam 不需要像其他优化器那样进行广泛的调优。虽然一个调整得非常好的 SGD 仍然可以得到稍微好一点的结果,但 Adam 让深度学习研究变得更加容易。它的出现可以帮助研究者,如果设计的模型不起作用,这大概率不太可能是一个调优不好的优化器的错。
论文:
- Adam: A Method for Stochastic Optimization
代码:
- https://d2l.ai/chapter_optimization/adam.html
- https://pytorch.org/docs/master/_modules/torch/optim/adam.html
2014 / 2015
生成对抗式网络

生成模型(如变分自动编码器)的目标是创建看起来逼真的数据样本,比如你可能在某个地方看到的人脸图像。因为他们必须对完整的数据分布进行建模,而不仅仅是像判别模型那样对猫或狗进行分类,所以这样的模型很难训练。生成对抗性网络(GANs)就是这样一种模型。
GANs 背后的基本思想是串联训练两个网络:一个生成器网络和一个鉴别器网络。生成器的目标是生成欺骗鉴别器的样本,鉴别器被训练来区分真实图像和生成的图像。随着时间的推移,鉴别器将变得更善于识别赝品,但生成器也将变得更擅长欺骗鉴别器,从而产生看起来越来越逼真的样本。GANs 的第一次迭代产生了模糊的低分辨率图像,并且训练起来非常不稳定。随着时间的推移,变化和改进,如 DCGAN、Wasserstein GAN、CycleGAN、StyleGAN,以及许多其他人已经建立在这个想法的基础上,以产生高分辨率的真实感图像和视频的模型。
论文:
- Generative Adversarial Networks
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
代码:
2015
残差网络
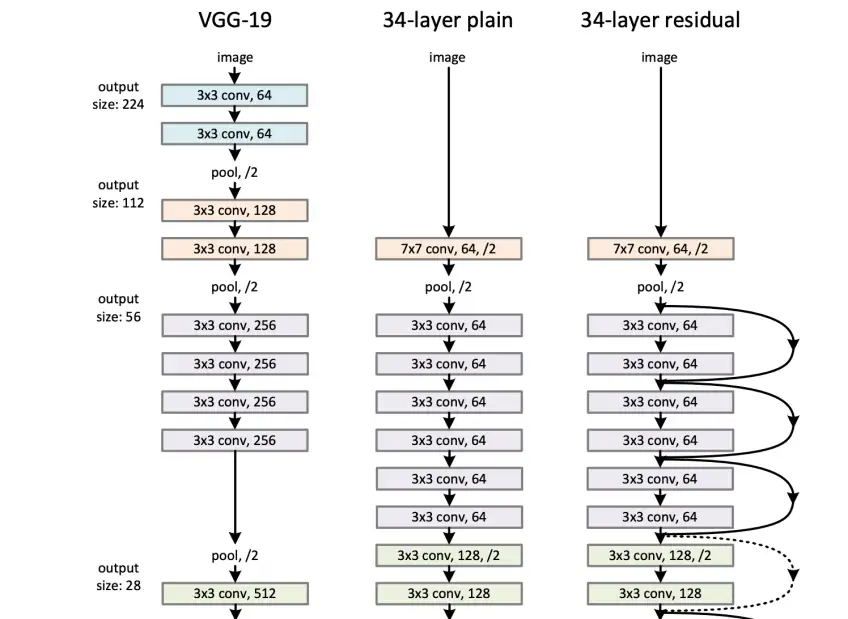
研究者在 AlexNet 突破的基础上,发明了基于卷积神经网络的性能更好的架构,如 VGGNet、Inception 等。ResNet 是这一系列快速进步中的下一个迭代。时至今日,ResNet 变体通常被用作各种任务的基线模型架构,以及更复杂架构中的子模块。
除了在 2015年 ILSVRC 分类挑战赛中获得第一名外,ResNet 的特殊之处在于其与其他网络架构相比的深度。论文中提出的最深网络有 1000 层,尽管在基准任务中比 101 层和 152 层的网络稍差,但整体仍然表现优异。训练这样的深度网络是一个很有挑战的优化问题,因为很容易发生梯度消失。没有多少研究人员相信训练这种极为深的网络可以带来稳定的结果。
ResNet 的出现改变了这种认知,其使用了标识快捷连接帮助梯度传播。解释这种连接的一种方式是,ResNet 只需要学习从一层到另一层的“delta”,这通常比学习完整的层与层之间的流转更容易。这种标识连接是高速深度网络系统中的一个特殊案例,其受 LSTM 门控机制所启发。
论文:
- Deep Residual Learning for Image Recognition
代码:
2017
Transformers
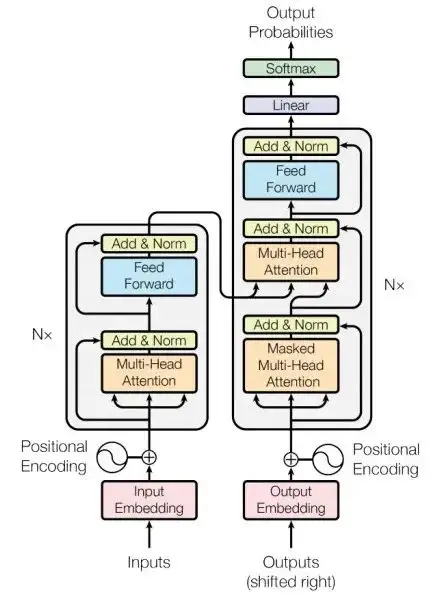
如前所述,注意力机制下的 Seq-to-Seq 模型在 NLP 场景下表现良好,但其基于 RNN 这种基础模型,因此有一些不可避免缺点。比如它们很难并行化,因为它们一步一步地处理输入,每个时间步骤都取决于前一个时间步骤。这使得很难将它们扩展到很长的序列。即使有了注意力机制,他们仍在为复杂的长期依赖关系建模。
Transformers 解决了上述问题,它完全消除循环重复,并用多个前馈自注意层代替循环层进行建模,这种方式可以并行处理所有输入,并在输入和输出之间产生相对较短的,易于梯度优化的路径。Transformers 训练速度很快,易于扩展,并且可以处理大规模的数据。而对于输入的顺序,Transformers 使用了位置编码。
要说 Transformers 的效果比任何人预期的都好,那就太轻描淡写了。在接下来的几年里,Transformers 成为绝大多数 NLP 和其他序列任务的标准架构,同时也改写了 CV 领域的架构。
论文:
- Attention Is All You Need
代码:
2018
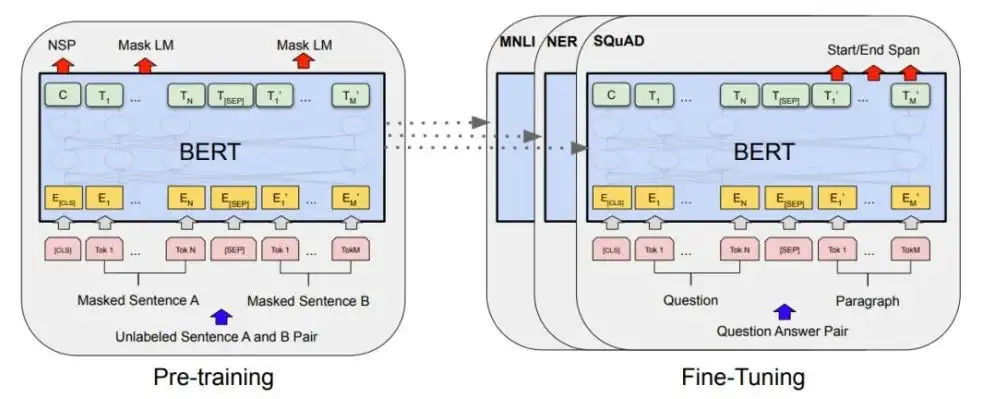
BERT 与预训练 NLP 模型
预训练是指训练一个模型来执行某些任务,然后使用学习到的参数作为初始化来学习其他相关的任务。直观的理解是,一个学会将图像分类为猫或狗的模型应该已经学习了一些关于图像和毛茸茸动物的一般知识。当这个模型被微调以对狐狸进行分类时,我们希望它比从头开始学习的模型做得更好。同样,一个学会预测句子中下一个单词的模型应该已经学习了一些关于人类语言模式的一般知识。我们希望它能作为翻译或情感分析等相关任务的良好初始化。
预训练和微调已经在 CV 和 NLP 中成功运用,虽然它长期以来在 CV 领域下被成熟运用,但使其在 NLP 领域中运行良好仍然具有一些挑战性。过去大多数最先进的 NLP 模型基本来自完全监督的模型。随着 Transformers 的出现,研究人员终于可以开始进行 NLP 预训练的研究工作,进而产生了诸如 ELMo(深度上下文化单词表示),ULMFiT(文本分类的通用语言模型微调)和 OpenAI 的 GPT 等方法。
BERT 是此类发展中的最新一项,许多人认为它开启了 NLP 研究的新时代。它不像大多数其他模型那样预先训练预测下一个单词,而是预先训练预测句子中任何地方的被屏蔽的单词(完形填空),以及两个句子是否可能相互上下文。请注意,这些任务不需要标记的数据。它可以在任何文本上进行训练。这个预训练的模型可能已经学习了一些关于语言的一般属性,然后可以进行微调以解决监督任务,例如问答或情绪预测。BERT 在各种任务中的表现非常出色。
论文:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
代码:
2019 ~ 2022
大语言模型与自监督学习
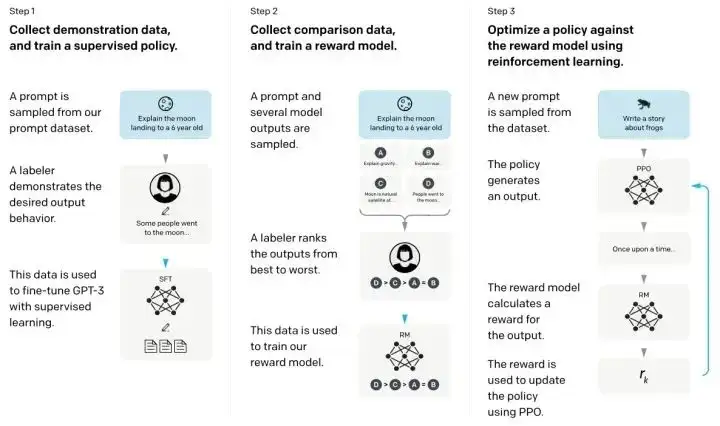
纵观深度学习历史,最明显的趋势也许是惨痛的教训。算法的进步,更好的并行化和更多的模型参数通常会胜过更智能的技术。这种趋势一直持续到 2020 年,其中 OpenAI 研发的 GPT-3 是一个拥有庞大的 1750 亿参数的语言模型,尽管其训练目标和架构比较简单,但它表现出出乎意料的良好泛化能力。2022 年末基于 GPT-3 和 RLHF 技术而成的 ChatGPT,凭借其优异的表现,大举推动深度学习走向通用人工智能(AGI)的进程。
同样趋势的是对比自监督学习等方法,例如 SimCLR,它们更好地利用了未标记的数据。随着模型变得越来越大,训练速度越来越快,能够有效利用网络上大量未标记数据并学习可以转移到其他任务的通用知识技术正变得越来越有价值并被广泛采用。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
拯救脂肪肝第一步!自主诊断脂肪肝:3D医疗影像分割方案MedicalSeg
AI最全资料汇总 | 基础入门、技术前沿、工业应用、部署框架、实战教程学习