高斯混合模型(后面本文中将使用他的缩写 GMM)听起来很复杂,其实他的工作原理和 KMeans 非常相似,你甚至可以认为它是 KMeans 的概率版本。 这种概率特征使 GMM 可以应用于 KMeans 无法解决的许多复杂问题。
因为KMeans的限制很多,比如: 它假设簇是球形的并且大小相同,这在大多数现实世界的场景中是无效的。并且它是硬聚类方法,这意味着每个数据点都分配给一个集群,这也是不现实的。
在本文中,我们将根据上面的内容来介绍 KMeans 的一个替代方案之一,高斯混合模型。
从概念上解释:高斯混合模型就是用高斯概率密度函数(正态分布曲线)精确地量化事物,它是一个将事物分解为若干的基于高斯概率密度函数(正态分布曲线)形成的模型。
高斯混合模型 (GMM) 算法的工作原理
正如前面提到的,可以将 GMM 称为 概率的KMeans,这是因为 KMeans 和 GMM 的起点和训练过程是相同的。 但是,KMeans 使用基于距离的方法,而 GMM 使用概率方法。 GMM 中有一个主要假设:数据集由多个高斯分布组成,换句话说,GMM 模型可以看作是由 K 个单高斯模型组合而成的模型,这 K 个子模型是混合模型的隐变量(Hidden variable)
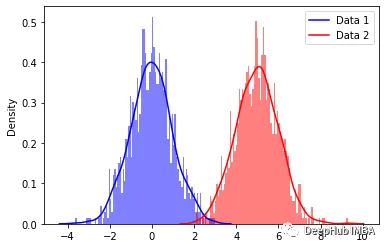
上述分布通常称为多模型分布。 每个峰代表我们数据集中不同的高斯分布或聚类。 我们肉眼可以看到这些分布,但是使用公式如何估计这些分布呢?
在解释这个问题之前,我们先创建一些高斯分布。这里我们生成的是多元正态分布; 它是单变量正态分布的更高维扩展。
让我们定义数据点的均值和协方差。 使用均值和协方差,我们可以生成如下分布。
完整文章:
https://avoid.overfit.cn/post/c9ca4de6d42d4d67b80cc789e921c636