一、任务详情
自学教材第4章,提交学习笔记(10分),评分标准如下
- 知识点归纳以及自己最有收获的内容,选择至少2个知识点利用chatgpt等工具进行苏格拉底挑战,并提交过程截图,提示过程参考下面内容 (4分)
- 问题与解决思路,遇到问题最先使用chatgpt等AI工具解决,并提供过程截图(3分)
- 实践过程截图,代码链接(2分)
- 其他(知识的结构化,知识的完整性等,提交markdown文档,使用openeuler系统等)(1分)
二、知识点归纳
1.第四章 并发编程
4.1 并行计算导论
在早期,大多数计算机只有一个处理组件,称为处理器或中央处理器(CPU)。受这种硬件条件的限制,计算机程序通常是为串行计算编写的。要求解某个问题,先要设计一种算法,描述如何一步步地解决问题,然后用计算机程序以串行指令流的形式实现该算法。在只有一个CPU的情况下,每次只能按顺序执行某算法的一个指令和步骤。但是,基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性,可通过使用并行或并发执行来提高计算速度。并行计算是一种计算方案,它尝试使用多个执行并行算法的处理器更快速地解决问题。过去,由于并行计算对计算资源的大量需求,普通程序员很少能进行并行计算。近年来,随着多核处理器的出现,大多数操作系统(如Linux)都支持对称多处理(SMP)。甚至对于普通程序员来说,并行计算也已经成为现实。显然,计算的未来发展方向是并行计算。
4.1.1顺序算法与并行算法
begin-end代码块中的顺序算法可能包含多个步骤。所有步骤都是通过单个任务依次执行的,每次执行一个步骤。当所有步骤执行完成时,算法结束。相反,右侧为并行算法的描述,它使用cobegin-coend代码块来指定并行算法的独立任务。在cobegin-coend块中.所有任务都是并行执行的,紧接着cobegin-coend代码块的下一个步骤将只在所有这些任务完成之后执行。
4.1.2并行性与并发性
通常,并行算法只识别可并行执行的任务,但是它没有规定如何将任务映射到处理组件。在理想情况下,并行算法中的所有任务都应该同时实时执行。然而,真正的并行执行只能在有多个处理组件的系统中实现,比如多处理器或多核系统。在单 CPU 系统中—次只能执行一个任务。在这种情况下,不同的任务只能并发执行,即在逻辑上并行执行。在单CPU 系统中,并发性是通过多任务处理来实现的。
4.2 线程
4.2.1线程的原理
一个操作系统(OS)包含许多并发进程。在进程模型中,进程是独立的执行单元。所有进程均在内核模式或用户模式下执行。在内核模式下,各进程在唯一地址空间上执行,与其他进程是分开的。虽然每个进程都是一个独立的单元,但是它只有一个执行路径。当某进程必须等待某事件时,例如I/O完成事件,它就会暂停,整个进程会停止执行。线程是某进程同一地址空间上的独立执行单元。创建某个进程就是在一个唯一地址空间创建一个主线程。当某进程开始时,就会执行该进程的主线程。如果只有一个主线程,那么进程和线程实际上并没有区别。但是,主线程可能会创建其他线程。每个线程又可以创建更多的线程等。某进程的所有线程都在该进程的相同地址空间中执行,但每个线程都是一个独立的执行单元。在线程模型中,如果一个线程被挂起,其他线程可以继续执行。除了共享共同的地址空间之外,线程还共享进程的许多其他资源,如用户id、打开的文件描述符和信号等。打个简单的比方,进程是一个有房屋管理员(主线程)的房子,线程是住在进程房子里的人。房子里的每个人都可以独立做自己的事情,但是他们会共用一些公用设施,比如同一个信箱、厨房和浴室等。过去,大多数计算机供应商都是在自己的专有操作系统中支持线程。不同系统之间的实现有极大的区别。目前,几乎所有的操作系统都支持Pthread,它是IEEE POSIX 1003.1c的线程标准(POSIX 1995)。
4.2.2线程的优点
- 线程创建和切换速度更快。
若要在某个进程中创建线程,操作系统不必为新的线程分配内存和创建页表,因为线程与进程共用同一个地址空间。所以,创建线程比创建进程更快。 - 线程的响应速度更快
一个进程只有一个执行路径。当某个进程被挂起时,帮个进程都将停止执行。相反,当某个线程被挂起时,同一进程中的其他线程可以继续执行。 - 线程更适合井行计算。
并行计算的目标是使用多个执行路径更快地解决间题。基于分治原则(如二叉树查找和快速排序等)的算法经常表现出高度的并行性,可通过使用并行或并发执行来提高计算速度。
4.2.3线程的缺点
- 由于地址空间共享,线程需要来自用户的明确同步.
- 许多库函数可能对线程不安全,例如传统的strtok()函数将一个字符串分成一连串令牌。通常,任何使用全局变量或依赖于静态内存内容的函数都是线程不安全的。为了使库函数适应线程环境,还需要做大量的工作。
- 在单CPU系统上,使用线程解决间题实际上要比使用顺序程序慢,这是由在运行时创建线程和切换上下文的系统开销造成的。
4.3 线程操作
线程的执行轨迹与进程类似。线程可在内核模式或用户模式下执行。用户模式下,线程在进程的相同地址空间中执行,但每个线程都有自己的执行堆栈。线程是独立的执行单元,可根据操作系统内核的调度策略,对内核进行系统调用,变为挂起、激活以继续执行等。
4.4 线程管理函数
4.4.1 创建线程
使用pthread_create()函数创建线程:
int pthread_create(pthread_t *pthread_id, pthread_attr_t *attr, void *(*func)(void *), void *arg);
如果成功则返回0,如果失败则返回错误代码。pthread_create()函数的参数为:
- pthread_id是指向pthread_t类型变量的指针,用于存储线程的ID。
- attr是指向线程属性的指针,可以为NULL表示使用默认属性。
- func是要执行的新线程函数的入口地址。
- arg是指向线程函数参数的指针。
线程属性参数attr最复杂,可以使用pthread_attr_init()函数进行初始化,并设置属性,最后通过pthread_attr_destroy()函数释放资源。通常情况下,可以使用NULL作为属性参数,以使用默认属性。
4.4.2 线程ID
线程ID是一种不透明的数据类型,取决于实现情况。因此,不应该直接比较线程ID。 如果需要,可以使用pthread_equal()函数对它们进行比较:
int pthread_equal (pthread_t tl, pthread_t t2);
4.4.3 线程终止
线程函数结束后,线程即终止。或者,线程可以调用函数
int pthread_exit (void *status);
进行显式终止,其中状态是线程的退出状态。通常,0退出值表示正常终止,非0值表示异常终止。
4.4.4 线程连接
一个线程可以等待另一个线程的终止,通过pthread_join()函数进行连接,同时终止线程的退出状态以status_ptr返回。
4.5 线程示范程序
计算一个N×N整数矩阵中所有元素的和:
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#defineN 4
int A[N][N],sum[N];
void *func(void *arg)
//threads function
int j,row;
pthread_t tid =pthread_self();//get thread ID number//get row number from argrow =(int)arg;
printf("Thread 8d[&lu]computes sum of row gd\n",row,tid,row);11 compute sum of A[row]in global sum[row]for(j=0;j<N;j++)sum[row]+=A[row][j];
printf("Thread 8d [8lu]done:sum[8d]=sd\n",row,tid,row,sum[row]);pthread_exit((void*)0);//thread exit:0=normal termination
}
int main(int argc,char *argv[])
pthread_t thread[N];
//thread IDs
int i,j,r,total =0;
void *status;
printf("Main:initialize A matrix\n");
for(i=0;i<N;i++){
sum[i]=0;
for(j=0;j<N;j++){
A[i][j]=i*N+j+1;
printf("84d",A[i][j]);
}
printf("\n");
}
printf("Main:create gd threads\n",N);
for(i=0;i<N;i++)[
pthread_create(&thread[i],NULL,func,(voia *)i)
}
printf("Main:try to join with threads\n");
for(i=0;i<N;i++){
pthread_join(thread[i],estatus);
printf("Main:joined with 8d [8lu]:status=gd\n",
i,thread[i],(int)status);
}
printf("Main:compute and print total sum:");
for(i=0;i<N;i++)
total +=sum[i];
printf("tatal =8d\n",total);
pthread_exit(NULL);
}
4.6 线程同步
由于线程在进程的同一地址空间中执行,它们共享同一地址空间中的所有全局变量和数据结构。当多个线程试图修改同一共享变量或数据结构时,如果修改结果取决于线程的执行顺序,则称之为竞态条件。在并发程序中,绝不能有竞态条件,否则结果可能不一致。除了连接操作之外,并发执行的线程通常需要相互协作。为了防止出现竞态条件并且支持线程协作,线程需要同步。通常,同步是一种机制和规则,用于确保共享数据对象的完整性和并发执行实体的协调性。它可以应用于内核模式下的进程,也可以应用于用户模式下的线程。
4.6.1 互斥量
在Pthread中,锁被称为互斥量,意思是相互排斥。
- 静态方式
pthread_mutex_t m = PTHREAD_MUTEX_INITIALIZER - 动态方式
pthread_mutex_init(pthread_mutex_t *m,pthread_mutexattr_t,*attr);
4.6.2 死锁预防
死锁是一种状态,在这种状态下,许多执行实体相互等待,因此都无法继续下去。有多种方法可以解决可能的死锁问题,其中包括死锁预防、死锁规避、死锁检测和恢复等。在实际系统中,唯一可行的方法是死锁预防,试图在设计并行算法时防止死锁的发生。
4.6.3 条件变量
条件变量提供了一种线程协作的方法。在Pthread中,使用类型pthread_cond_t来声明条件变量,必须在使用前进行初始化。条件变量可以通过静态方法或动态方法进行初始化。
4.6.4 生产者—消费者问题
一组生产者进程和一组消费者进程共享一个初始为空、大小为n的缓冲区,只有缓冲区为满时,生产者才把消息放入缓冲区,否则必须等待;只有缓冲区不为空时,消费者从中取出消息,否则必须等待。由于缓冲区是临界资源,它只允许一个生产者放入消息,或一个消费者从中取出消息。
4.6.5 信号量
信号量和条件变量之间的主要区别是,前者包含一个计数器,可操作计数器,测试计数器值以做出决策等,所有这些都是临界区的原子操作或基本操作,而后者需要一个特定的互斥量来执行临界区。在 Pthreads 中,互斥量严格用于封锁。而条件变量可用于线程协作。相反,可以把使用初始值1计算信号量当作锁。带有其他初始值的信号量可用于协作。因此,信号量比条件变量更通用、更灵活。
4.6.6 屏障
创建一个屏障对象
pthread_barrier_t barrier
调用pthread_barrier_init(&barrier NULL,nthreads)
在屏障中同步的线程数字对它进行初始化,然后主线程创建工作线程来执行任务。工作线程使用pthread_barrier_wait(&barrier)
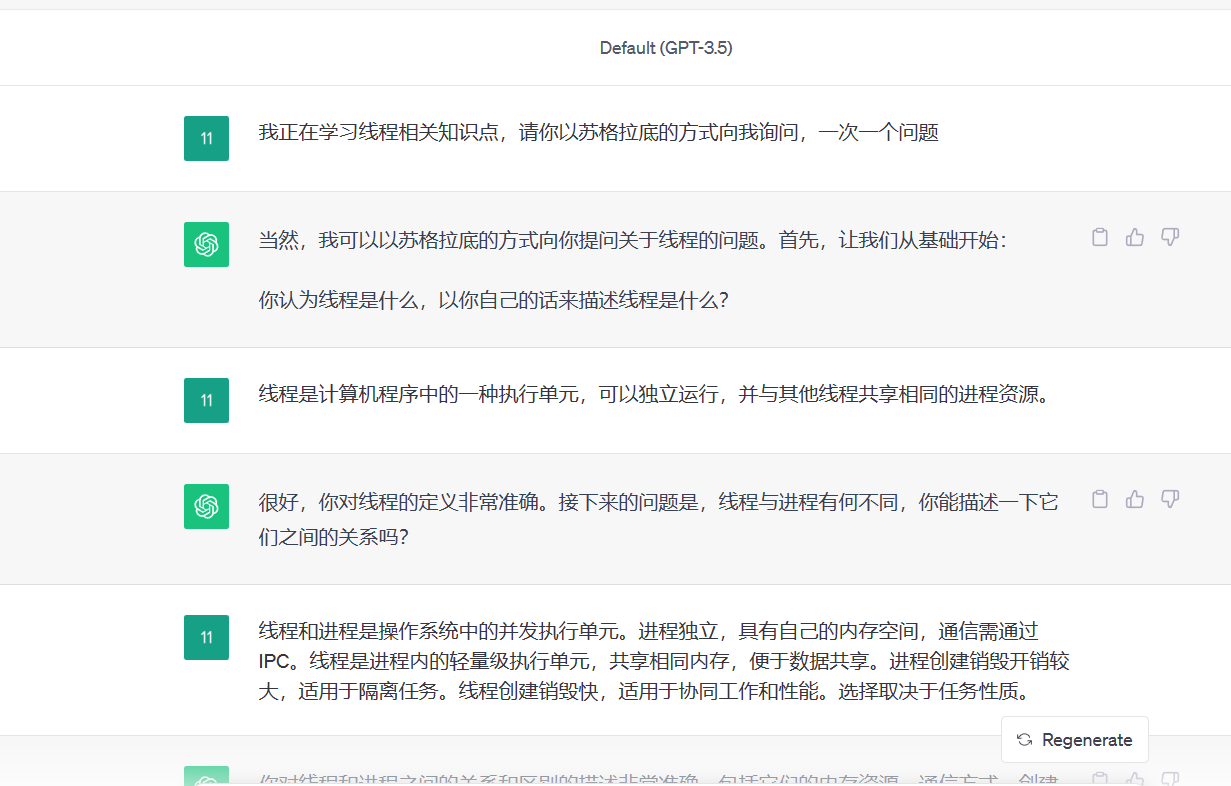
2.苏格拉底挑战
1.
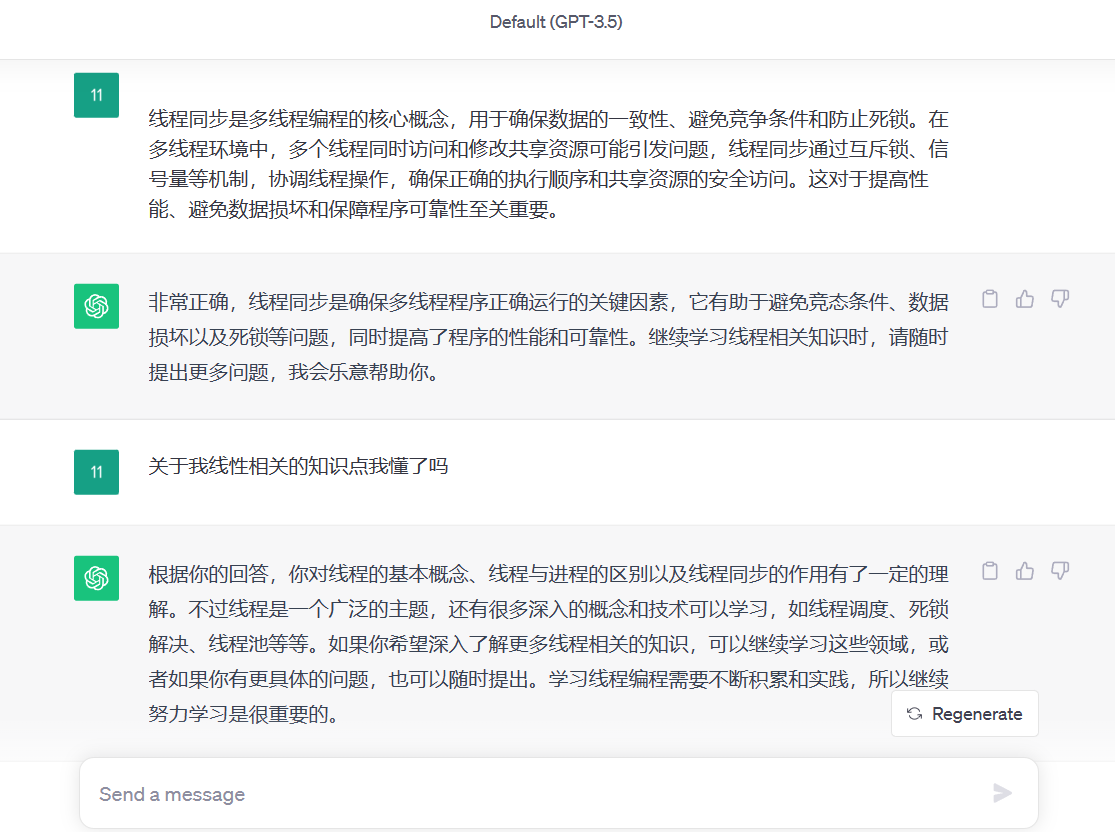
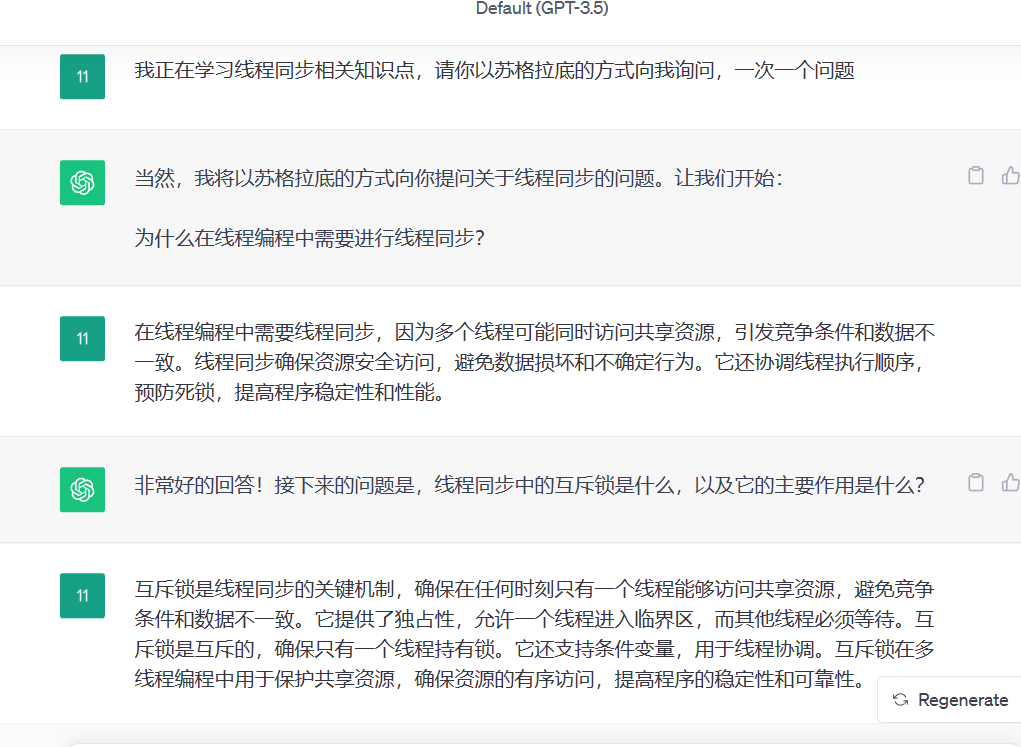
2.

三、问题与解决思路
问题
(1)解决死锁问题的方法
解决思路

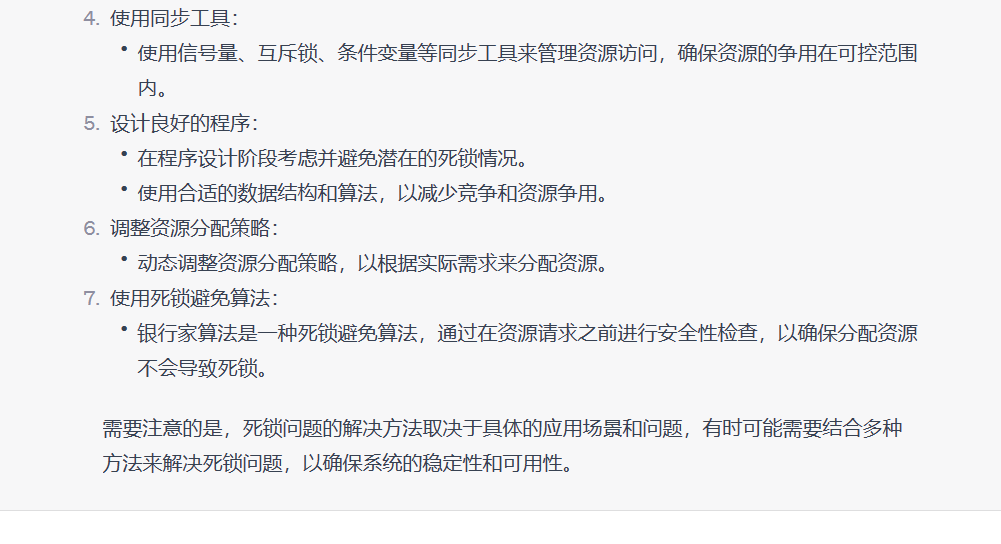
四、实践过程截图
- 首先实践了课上内容
代码如下:
#include <stdio.h>
#include <omp.h>
#define N 5
double A[N][N] = { {2.0, 1.0, 0.0, 0.0, 0.0},
{1.0, 2.0, 1.0, 0.0, 0.0},
{0.0, 1.0, 2.0, 1.0, 0.0},
{0.0, 0.0, 1.0, 2.0, 1.0},
{0.0, 0.0, 0.0, 1.0, 2.0} };
void solve_equations(double x[N], double b[N]) {
#pragma omp parallel do
for (int i = 0; i < N; ++i) {
double sum = 0.0;
#pragma omp critical
for (int j = 0; j < N; ++j) {
if (i != j) {
sum += A[i][j] * x[j];
}
}
x[i] = b[i] / A[i][i] - sum;
}
}
int main() {
double b[N] = {1.0, 2.0, 3.0, 4.0, 5.0};
double x[N];
// Initialize solution vector x with zeros.
for (int i = 0; i < N; ++i) {
x[i] = 0.0;
}
// Solve the linear equations using OpenMP.
solve_equations(x, b);
// Print the solution vector x.
printf("Solution: ");
for (int i = 0; i < N; ++i) {
printf("%.2f ", x[i]);
}
printf("\n");
return 0;
}