Is Attention Better Than Matrix Decomposition?
* Authors: [[Zhengyang Geng]], [[Meng-Hao Guo]], [[Hongxu Chen]], [[Xia Li]], [[Ke Wei]], [[Zhouchen Lin]]
初读印象
comment:: 作者提出了一系列Hamburger,这些汉堡包使用MD的优化算法来分解输入表示并重建低秩嵌入,显示出在视觉任务中对自我注意力的显着改进。
Why
注意力:
(1)基于自我注意开发新的全局语境模块,通常需要手工制作;
(2)解释当前的注意模型为何有效。
如果将全局上下文这样的归纳偏差表述为一个目标函数,那么最小化目标函数的优化算法就可以构建一个计算图,即我们所需要的网络架构。
将这一想法具体化,为最具代表性的全局上下文模块(自注意力)开发了一个对应模块。我们将提取网络中的全局信息视为寻找字典和相应的编码以捕捉内在相关性,将上下文发现建模为输入张量的低秩恢复,并通过矩阵分解来解决。
所谓低秩矩阵:秩可以理解为图像中信息的丰富程度。图像通常由一些类似的基底组成(如线、块和圆等),如果图像中其他特征干扰了这些基底,那么这些特征可以视为噪声;去除了噪声的矩阵则可以看成是低秩的。
What
矩阵分解
给定输入\(\mathbf{X}=[\mathbf{x}_1,\cdots,\mathbf{x}_n]\in\mathbb{R}^{d\times n}.\)存在一个字典矩阵\(D=[\hat{\mathbf{d}}_{1},\cdots,\mathbf{d}_{r}]\in\mathbb{R}^{d\times r}\)和对应的编码矩阵\(C=[\mathbf{c}_1,\cdots,\mathbf{c}_n]\in\mathbb{R}^{r\times n}\text{ 1},使得\)X\(可以被表示为: 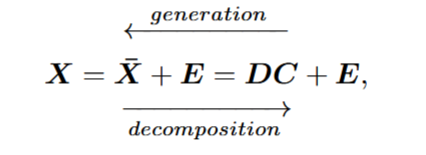其中\)\bar{X}\in\mathbb{R}^{d\times n}\(是输出的低秩矩阵,\)E$是可以被去除的噪声。
HAMBURGER
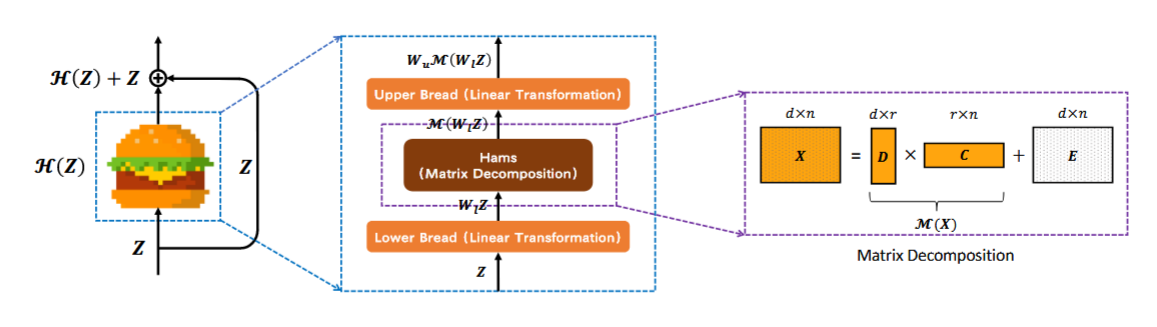
lower bread
一个线性映射,将输入\(Z\in\mathbb{R}^{d_z\times n}\)映射成\(X\in\mathbb{R}^{d\times n}\)
ham
ham层输出一个低秩重建,即
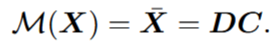 ######Softmax Vector Quantization(软矢量量化)
######Softmax Vector Quantization(软矢量量化)

Non-negative Matrix Factorization(非负矩阵分解)
对\(D,C\)施加非负约束,即先对X做一个ReLU。
 #####upper bread
#####upper bread
另一个线性映射,映射回原来的维度。
How

启发
寻找一个去除噪声的方法,然后初始化一个字典矩阵,就能得到一个编码矩阵。
可以用这种方法得到类中心。