HACK: Learning a Parametric Head and Neck Model for High-fidelity Animation
上科大发布的头和脖子精细建模的参数化模型HACK。
纹理转化
由于HACK没有开源纹理基,我将FLAME开源的纹理基迁移到了HACK上,代码在这里开源:
https://github.com/aoru45/FLAME_TO_HACK/tree/main
论文方法
FLAME也对脖子进行了建模,不过只是用一个joint点来描述相对于脖子的运动,HACK则是在脖子处用了7个joints来描述脖子,以扩充模型对脖子的表达能力。之所以去建模脖子,也是因为在对人脸的数字化应用场景中,人头部的动作表达尚有不足,一些情绪如紧张时吞咽口水等细节没法用现有模型表达,因此对喉咙部分的shape建模,pose中以解剖学为先验增加更多joints,加上头部建模, 弥补其不足。
HACK的参数化模型表示为:
其中Blend shape:
其余的\(J,\theta,W\),遵循和FLAME一样的建模方式。
对于shape基,与FLAME一样直接用PCA得到,喉咙部分不在neutral的mesh里。
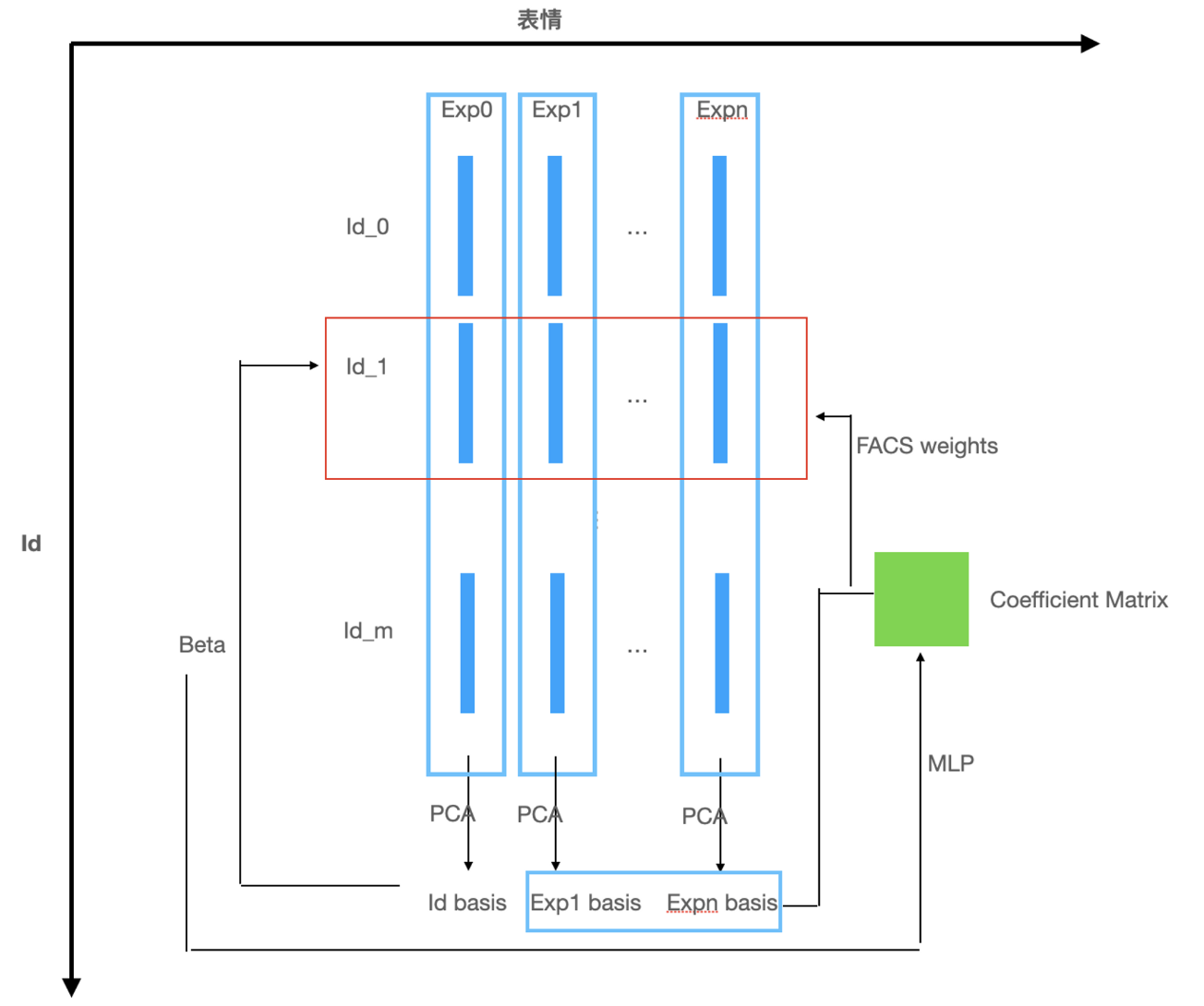
对于expression基,使用FACS先验,由FACS的weights绑定到对应基的区域,同时为了使expression的基更加person-specific,使用一个网络去预测给定person的表情基。这样做的好处是使得表情基在对于特定的人有着更强的细节上的表达能力。直接预测表情基(有表情的数据减去中性数据)是很困难的,因为点特别多,基的维数就是点的数目,于是文章希望预测更低维的对表情基进一步PCA之后的基的系数,这组系数和表情基相乘就是最终的表情基。我大致把该过程画了一下,以最终生成id1的blend shape为例,Beta和id basis相乘得到S,网络由Beta预测表情基的系数,和表情基线形组合成新的基,新的基以FACS weights作为参数,得到E。
同理,person-specific的pose基也会有更强的细节表达。用同样的方式去预测pose基的系数,也就是向量化后的旋转矩阵。与FLAME一样,要先去训练得到基。pose基确定之后再去训练预测基系数的网络。
对于喉咙的blend,需要考虑其shape和位置,\(\eta\)控制的是size,位置决定喉咙上下移动用一个标量tau表示。文章是将喉咙部分建模在uv空间,将所有点投到uv上,再对其做PCA,得到一组静息状态的基。通过在uv空间中y轴上坐标移动,实现喉咙位置的移动。
喉咙部分的建模,应用解刨学先验,用超声波扫描得到脊柱的三维点云,请专家标注joint点的位置,和虚拟的脊柱进行配准,配准时认为脊柱的运动是刚体运动,估计刚体运动的参数,最后和rest pose配准,配准时在表面标注点配准。
参数学习是通过最小化在序列数据上的损失学习的:
之后就能得到一组组deformation的系数序列。
目前并未开源纹理基,已有的开源代码我做了些注释:
import numpy as np
import cv2
import torch
import torch.nn as nn
import torch.nn.functional as F
import json
import roma
import helper
bones = json.load(open("model/bones_neutral.json"))
bone_names = list(bones.keys())
obj_template = helper.read_obj(r"model/000_generic_neutral_mesh_newuv.obj")
for name in bones:
bone = bones[name]
parent = bone["parent"]
L2P_rotation = np.array(bone["matrix"])
head_in_p = (np.array(bone["head"]) + ([0, bones[parent]["length"], 0] if parent is not None else 0))
L2P_transformation = np.identity(4)
L2P_transformation[:3, :3] = L2P_rotation
L2P_transformation[:3, 3] = head_in_p
bone["L2P_transformation"] = torch.tensor(L2P_transformation, dtype=torch.float32)
def update_L2W_transformation(name):
bone = bones[name]
transformation_name = "L2W_transformation"
local_pose_transformation = torch.eye(4)[None]
if transformation_name in bone:
return bone[transformation_name]
parent = bone["parent"]
L2W_transformation = bone["L2P_transformation"] @ local_pose_transformation
if parent is not None:
L2W_transformation = update_L2W_transformation(parent) @ L2W_transformation
bone[transformation_name] = L2W_transformation
return L2W_transformation
def update_L2W_transformation_pose(L2W_transformation_pose, L2P_transformation, ith_bone, pose_matrix):
"""
L2W_transformation_pose: list of N_bones
"""
name = bone_names[ith_bone]
bone = bones[name]
if L2W_transformation_pose[ith_bone] is not None:
return L2W_transformation_pose[ith_bone]
local_pose_transformation = torch.eye(4, device=pose_matrix.device)[None].repeat(pose_matrix.shape[0], 1, 1)
local_pose_transformation[:, :3, :3] = pose_matrix[:, bone_names.index(name)]
L2W_transformation = L2P_transformation[ith_bone] @ local_pose_transformation
parent = bone["parent"]
if parent is not None:
ith_parent = bone_names.index(parent)
print(f"update parent {ith_parent} with {ith_bone}")
# update_L2W_transformation_pose调用顺序是从root到叶子节点的,这里再调用只是为了拿parent的L2W_transformation_pose,进去之后就返回了
L2W_transformation = update_L2W_transformation_pose(L2W_transformation_pose, L2P_transformation, ith_parent, pose_matrix) @ L2W_transformation
L2W_transformation_pose[ith_bone] = L2W_transformation
return L2W_transformation_pose[ith_bone]
N_bones = 8
L2P_transformation = torch.stack([bones[bone_names[i]]["L2P_transformation"] for i in range(len(bone_names))])
L2W_transformation = torch.zeros(1, N_bones, 4, 4) # [1, Nb, 4, 4]
for name in bones:
L2W_transformation[:, bone_names.index(name)] = update_L2W_transformation(name)
W2L_transformation = torch.linalg.inv(L2W_transformation)
"""
^^^ CONSTANT ^^
"""
def uv1d_construct_delta(uv1d, tau):
"""
uv1d: [1, 1, 256, 256]
tau: [B, 1]
return: [B, 14062, 1]
"""
grid = getattr(uv1d_construct_delta, "grid", None)
if grid is None:
obj = obj_template
uv = obj.vts # (14269, 2)
uv[:, 1] = 1 - uv[:, 1]
uv = uv * 2 - 1 # 点 (-1,1) 存的是在uv空间中的坐标
fv = obj.fvs # 平面 (14062,4)
fvt = obj.fvts # 纹理
grid = np.ones((1, 1, 14062, 2)) * 2 # sample 14062个点,默认值2超出边界
for i in range(len(fv)):
for j in range(4):
if grid[0][0][fv[i][j]][0] == 2:
grid[0][0][fv[i][j]] = uv[fvt[i][j]] # 拿到坐标
else:
continue
grid = torch.tensor(grid).to(uv1d)
setattr(uv1d_construct_delta, "grid", grid)
# grid的y坐标加上2*tau
grid = grid + F.pad(tau * 2, [1, 0])[:, None, None, :]
output = torch.nn.functional.grid_sample(uv1d.expand(grid.shape[0], -1, -1, -1), grid, mode='bilinear', padding_mode="border", align_corners=True)
# output range [0,1]
return output[:, 0, 0, :, None]
class PCA(nn.Module):
# 基
def __init__(self, mean, diff):
super().__init__()
self.register_buffer("mean", torch.tensor(mean[None]).to(torch.float32))
self.register_buffer("diff", torch.tensor(diff[None]).to(torch.float32))
def forward(self, a=None, clip=999):
if a is None:
return self.mean
return self.mean + (a.reshape([a.shape[0], a.shape[1]] + [1] * (len(self.diff.shape) - 2)) * self.diff)[:, :clip].sum(dim=1)
def load_pca(path):
pca = np.load(path, allow_pickle=True).item()
mean = pca["mean"]
VT_std = pca["VT_std"]
pca = PCA(mean, VT_std)
return pca
class HACK(nn.Module):
def __init__(self):
super().__init__()
W = torch.tensor(np.load("model/weight_map_smooth.npy"), dtype=torch.float32) # [Nb, 14062]
W = W / W.sum(axis=0, keepdims=True)
self.register_buffer("W", W, persistent=False)
T = torch.tensor(obj_template.vs, dtype=torch.float32) # [14062, 3]
self.register_buffer("T", T)
P = torch.zeros(N_bones, 3, 3, 14062, 3) # [N_bones, 3, 3, 14062, 3]
self.register_buffer("P", P)
L = torch.tensor(cv2.imread("model/Lc_mid.png", cv2.IMREAD_GRAYSCALE) / 255, dtype=torch.float32)[None, None] # [1, 1, 256, 256]
self.register_buffer("L", L, persistent=False)
ts = torch.tensor(np.load("model/ts_larynx.npy"), dtype=torch.float32) # [3]
self.register_buffer("ts", ts, persistent=False)
self.register_buffer("L2P_transformation", L2P_transformation, persistent=False)
self.register_buffer("W2L_transformation", W2L_transformation, persistent=False)
blendshapes = torch.tensor(np.load("model/blendshape.npy"), dtype=torch.float32)
neutral = blendshapes[:1]
blendshapes = blendshapes[1:] - neutral
self.register_buffer("E", blendshapes, persistent=False)
def get_L_tau(self, tau):
"""
tau>0 means upper
"""
dist = uv1d_construct_delta(self.L, tau)
# self.ts tensor([ 0.0000, -0.4534, 0.8913]
# ts控制方向,并非竖直移动
L_tau = dist * self.ts
return L_tau
def forward(self, theta, tau, alpha, bsw, T=None, P=None, E=None):
"""
theta: [B, Nb, 3]
tau: [B, 1]
alpha: [B, 1]
bsw: [B, 55]
return: [B, Nv, 3]
"""
B = theta.shape[0]
theta_matrix = roma.rotvec_to_rotmat(theta) # [B, Nb, 3, 3]
# 减去静默状态(eye)之后pose基的系数
theta_matrix_zero = theta_matrix - torch.cat([theta_matrix[:, :1], (torch.eye(3).to(theta)[None, None]).expand(B, N_bones - 1, 3, 3)], dim=1)
P = self.P if P is None else P
# blend pose
P_theta = (theta_matrix_zero[:, :, :, :, None, None] * P).sum(dim=(1, 2, 3))
L2W_transformation_pose = [None] * N_bones
# 计算前向运动学的累乘旋转矩阵,theta_matrix是相对于joint的变换(local),最终转变为相对根节点parent的变换(world)
# l2p: local to parent
# l2w: local to world
for ith_bone in range(len(bone_names)):
print(f"setting {ith_bone}")
update_L2W_transformation_pose(L2W_transformation_pose, self.L2P_transformation, ith_bone, theta_matrix)
L2W_transformation_pose = torch.stack(L2W_transformation_pose, dim=1) # [B, Nb, 4, 4]
# 世界系的点先转到joint系
W2L2pWs = L2W_transformation_pose @ self.W2L_transformation # [B, Nb, 4, 4]
W2L2pW_weighted = (W2L2pWs[:, :, None, :, :] * self.W[None, :, :, None, None]).sum(axis=1) # [B, 14062, 4, 4]
T = self.T if T is None else T
E = self.E if E is None else E
# blend
# bsw是FACS系数
T_theta = T + P_theta + (E[:, :, :] * bsw[:, :, None, None]).sum(dim=1) + self.get_L_tau(tau) * alpha[:, :, None]
# 齐次系下skinning
T_transformed = (W2L2pW_weighted @ F.pad(T_theta, [0, 1], value=1)[:, :, :, None])[:, :, :3, 0] # [B, 14062, 3]
data = {
"T_transformed": T_transformed,
}
return data