背景
肯定会有人好奇,我们写的Flink任务代码是如何执行的,本着学习的态度,以flink-yarn的方式,在阅读源码的基础上做一个自己的总结。
环境信息
jdk:1.8
scala:2.12
flink:1.13
hadoop:3.0
hadoop相关的环境搭建就不赘述了,参考网上文档即可。
源码导入
- 源码下载后导入idea;
- 修改Maven仓库配置文件;
- 修改flink-parent/pom.xml配置文件;
修改默认的scala版本号等信息,默认用的是2.11版本,我这里切换成了2.12版本;
源码编译
我这里没有全部编码所有Module,只编译了几个常用的Module:
- flink-annotations
- flink-clients
- flink-core
- flink-streaming-java
- flink-yarn
大家根据自己情况选择编译。
流程分析
WordCount.java
//以flink自带的workdcount为学习入口
org.apache.flink.streaming.examples.wordcount.WordCount
//所有的Stream任务都最终调用 StreamExecutionEnvironment.execute() 方法
StreamExecutionEnvironment.java
execute()方法
- 先生成任务的执行流图-->getStreamGraph();
- 然后调用异步执行任务的方法-->executeAsync();
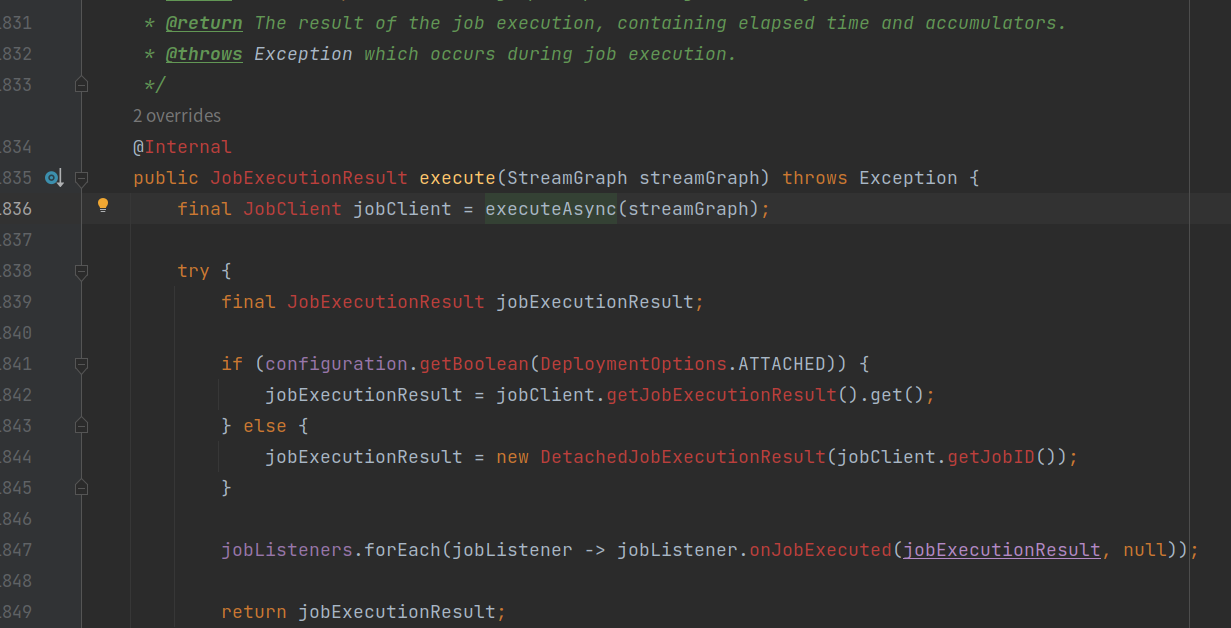
executeAsync()方法
- 通过任务执行器工厂构建一个YarnJobClusterExecutor任务执行器实例;
- 再调用任务执行器实例的YarnJobClusterExecutor.execute(),执行任务代码;
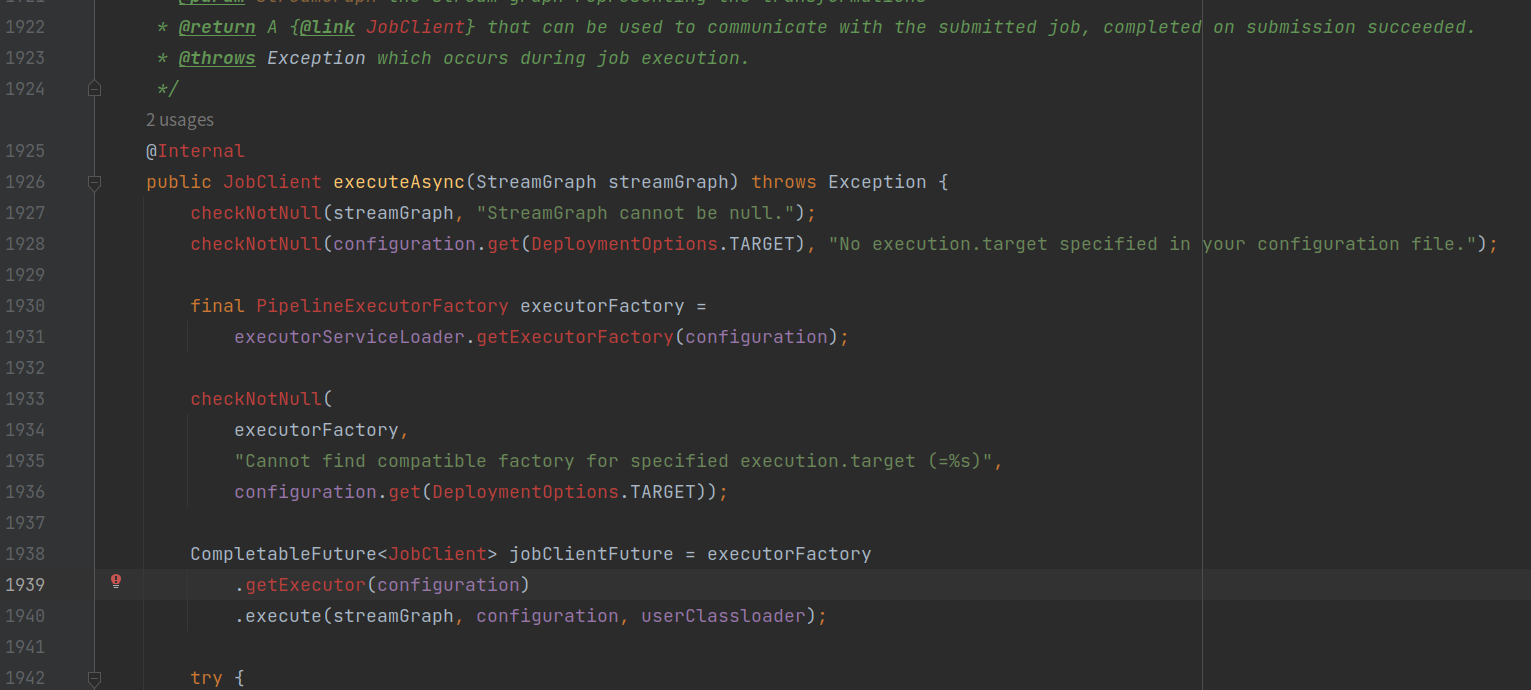
YarnJobClusterExecutor.java
execute()方法
- 将用户代码的流图转成Flink的JobGraph作业图;
- 生成一个Yarn任务上下文封装类实例,配置Yarn任务上下文信息;
- 配置Flink相关JobManager、TaskManager的资源信息;
- 通过Yarn任务上下文实例,调用YarnClusterDescriptor.deployJobCluster()方法,部署Yarn任务;
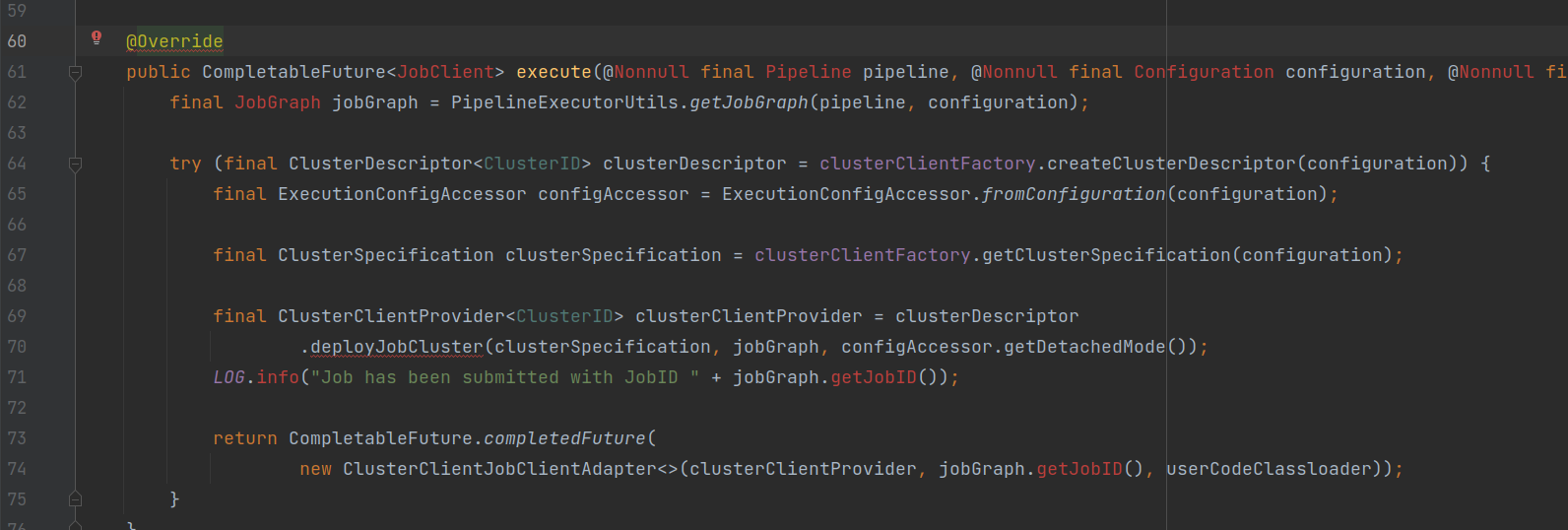
YarnClusterDescriptor.java
deployJobCluster()
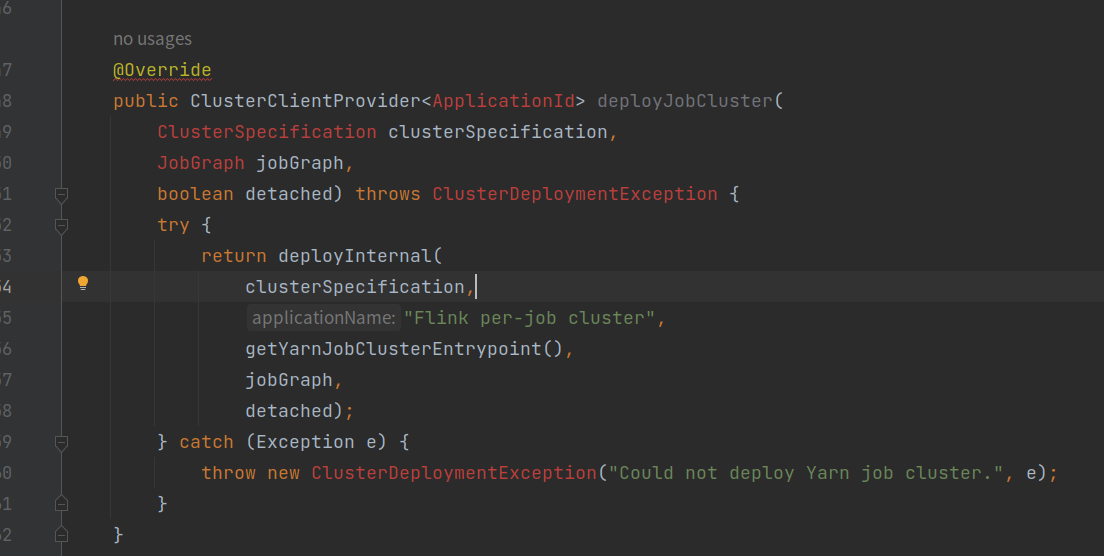
deployInternal()
- 验证提交至yarn集群的相关配置参数;
- 检查yarn集群的当前资源是否满足任务需求;
- 调用startAppMaster()方法,向yarn集群提交执行AppMaster(AM);
startAppMaster()
- 初始化HDFS文件系统;
- 将yarn任务所需的jar包等资源封装成一个上传工具Uploader;
- 用户提交的相关jar包信息封装进Uploader;
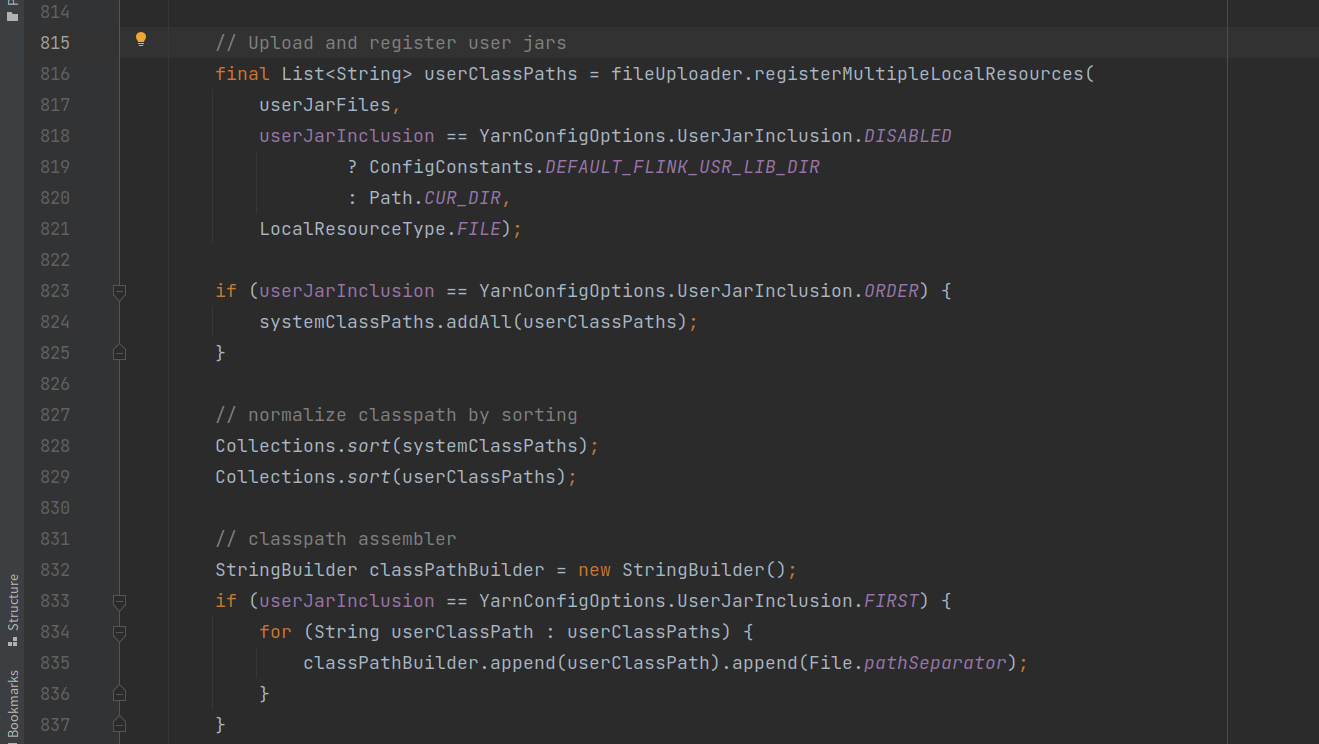
- 封装flink配置相关配置信息;
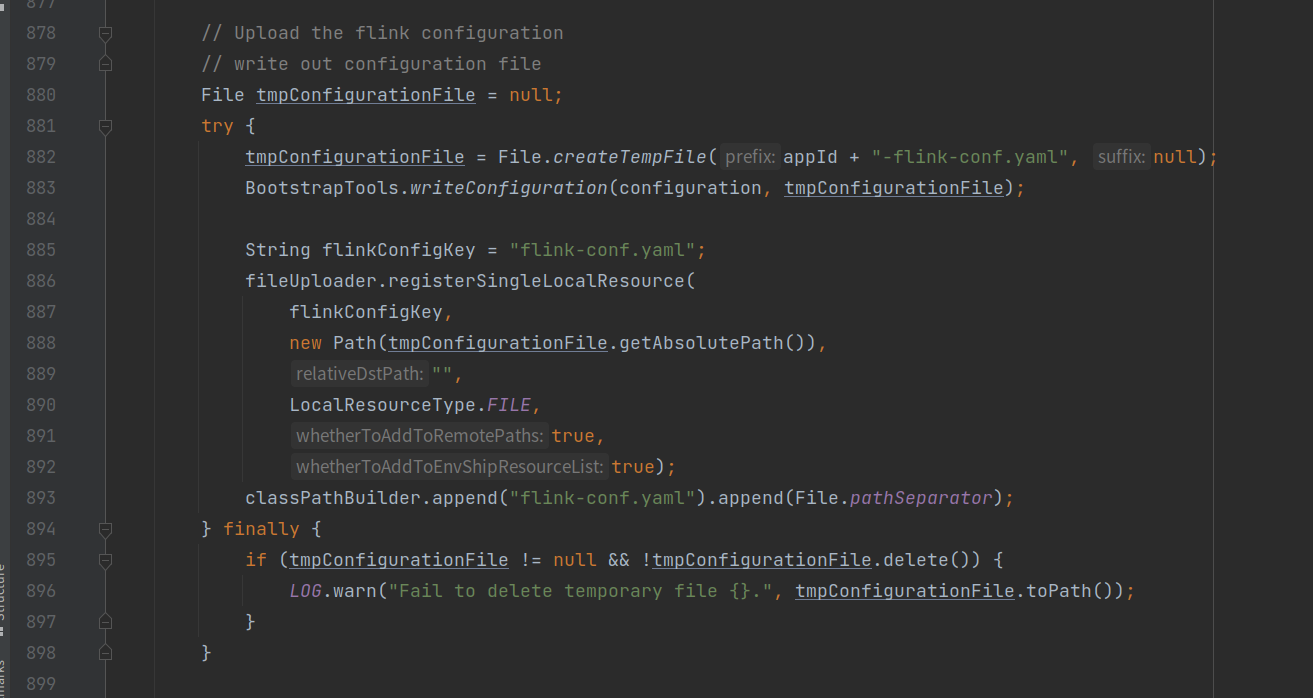
- 配置Yarn的AM容器;
- 指定AM要执行任务入口类;

- 指定Yarn-AM的资源目录;
- 设置Yarn容器相关的环境变量信息;
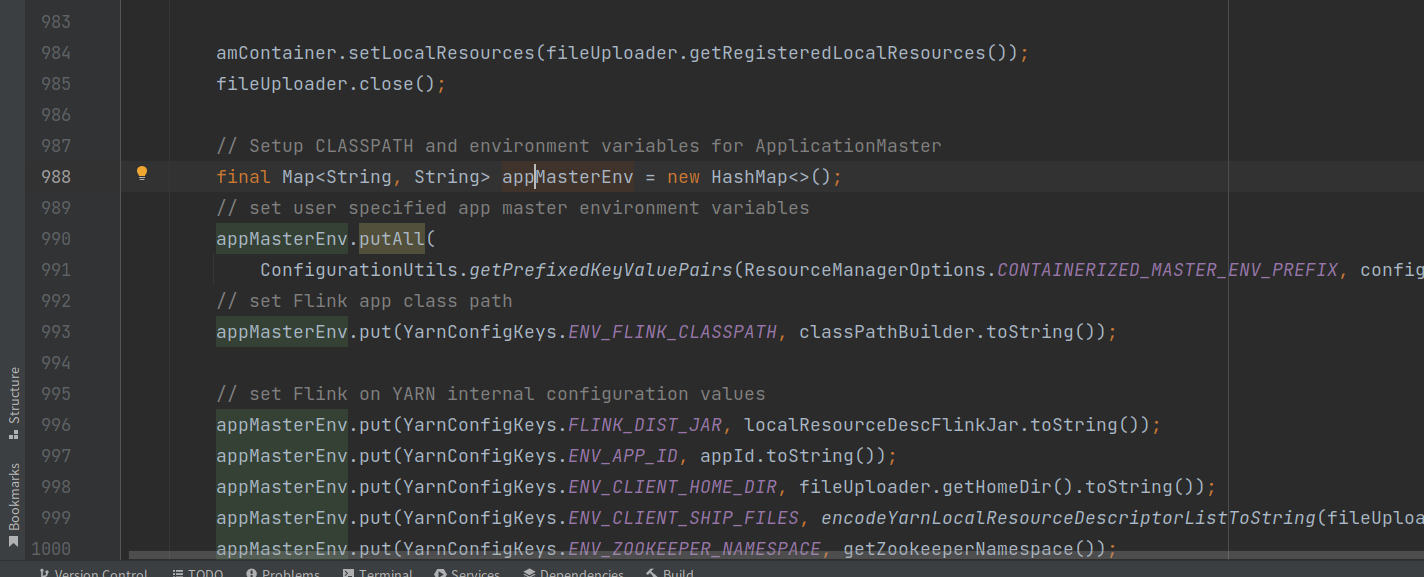
- 调用Yarn客户端启动AM,从指定的入口类开始执行任务;

总结
flink任务起点从StreamExecutionEnvironment的execute()方法开始,依次进行flink任务环境配置,yarn环境配置,中间有不少层层调用,第一次读起来可能会有点乱,但多读几次就好了。
这里只分析到了提交至Yarn集群并启动AM窗口为止。
同时也画了一个关键流程的示意图:
