1. YARN 命令
YARN 命令 ${HADOOP_HOME}/bin/yarn 在不带任何参数的情况下运行 yarn 脚本会打印所有命令的描述,命令分为用户命令和管理命令。
$ yarn
Usage: yarn [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
or yarn [OPTIONS] CLASSNAME [CLASSNAME OPTIONS]
where CLASSNAME is a user-provided Java class
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
daemonlog get/set the log level for each daemon
node prints node report(s)
rmadmin admin tools
scmadmin SharedCacheManager admin tools
Client Commands:
app|application prints application(s) report/kill application/manage long running application
applicationattempt prints applicationattempt(s) report
classpath prints the class path needed to get the hadoop jar and the required libraries
cluster prints cluster information
container prints container(s) report
envvars display computed Hadoop environment variables
jar <jar> run a jar file
logs dump container logs
queue prints queue information
schedulerconf Updates scheduler configuration
timelinereader run the timeline reader server
top view cluster information
version print the version
Daemon Commands:
nodemanager run a nodemanager on each worker
proxyserver run the web app proxy server
registrydns run the registry DNS server
resourcemanager run the ResourceManager
router run the Router daemon
sharedcachemanager run the SharedCacheManager daemon
timelineserver run the timeline server
1.1 用户命令
用户命令主要包括对 Application、ApplicationAttempt、Classpath、Container、Jar、Logs、Node、Queue 和 Version 的使用。
$ yarn application [options]
a. application
(1)查看所有的 Application(仅显示状态为 SUBMITTED、ACCEPTED、RUNNING 应用)
$ yarn application -list
(2)杀死某一个 Application
$ yarn application -kill application_1573364048641_0004
(3)查看某一个 Application 的统计报告
$ yarn application -status application_1614179148030_0001
(4)查看状态为 ALL 的 Application 列表
$ yarn application -list -appStates ALL
(5)查看类型为 MAPREDUCE 的 Application 列表
$ yarn application -list -appTypes MAPREDUCE
(6)移动一个 Application 到 default 队列
$ yarn application -movetoqueue application_1573364048641_0004 -queue default
如果使用 FairScheduler 时,使用此命令移动应用程序从 A 队列到 B 队列时,出于公平考虑,它在 A 队列所分配的资源会在 B 队列中重新资源分配。如果加入被移动的应用程序的资源超出 B 队列的 maxRunningApps 或 maxResources 限制,会导致移动失败。
(7)修改一个Application的优先级(整数值越高则优先级越高)
$ yarn application -updatePriority 0 -appId application_1573364048641_0006
b. jar
使用方式
$ yarn jar x.jar [mainClass] args...
使用 yarn jar 提交运行 MapReduce 应用
$ yarn jar \
/export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
/data/input.txt /data/output
c. applicationattempt
使用方式
$ yarn applicationattempt [options]
查看帮助
$ yarn applicationattempt -help
标记 applicationattempt 失败
$ yarn applicationattempt -fail appattempt_1573364048641_0004_000001
查看某个 application 所有的 attempt
$ yarn applicationattempt -list application_1614179148030_0001
查看具体某一个 applicationattemp 的报告
$ yarn applicationattempt -status appattempt_1614179148030_0001_000001
d. container
使用方式
$ yarn container [options]
查看帮助
$ yarn container -help
查看某一个 applicationattempt 下所有的 container
$ yarn container -list appattempt_1614179148030_0001_000001
应用在 YARN 时,才能够查看出 Contanier 容器信息。
e. logs
使用方式
$ yarn logs -applicationId <application ID> [options]
查看帮助
$ yarn logs -help
查看应用程序所有的 logs
$ yarn logs -applicationId application_1614179148030_0001
查看应用程序某个 container 运行所在节点的 log
$ yarn logs -applicationId application_1614179148030_0001 -containerId container_e01_1614179148030_0001_01_000001
f. classpath/version
获取 YARN 的类路径
$ yarn classpath
获取 YARN 版本
$ yarn version
g. queue
使用方式
$ yarn queue [options]
查看帮助
$ yarn queue -help
查看某个 queue 的状态
$ yarn queue -status default
h. node
使用方式
$ yarn node [options]
查看帮助
$ yarn node -help
查看 YARN 所有从节点
$ yarn node -list -all
查看 YARN 所有节点的详情
$ yarn node -list -showDetails
查看 YARN 所有正在运行的节点
$ yarn node -list -states RUNNING
查看 YARN 某一个节点的报告
$ yarn node -status node1:44929
1.2 管理命令
对于 Hadoop 集群的管理员使用的相关命令,主要包括 daemonlog、nodemanager、proxymanager、resourcemanager、rmadmin、scmadmin、sharedcachemanager 和 timelineserver 命令。
a. resourcemanager
使用方式
$ yarn resourcemanager [options]
启动某个节点的 resourcemanager
$ yarn resourcemanager
格式化 resourcemanager 的 RMStateStore
# 清除 RMStateStore,如果不再需要以前的应用程序,则将非常有用。只有在ResourceManager没有运行时才能使用此命令。
$ yarn resourcemanager -format-state-store
删除 RMStateStore 中的 Application
# 从RMStateStore删除该应用程序,只有在ResourceManager没有运行时才能使用此命令。
$ yarn resourcemanager -remove-application-from-state-store <appId>
b. nodemanager
启动某个节点的 nodemanager
$ yarn nodemanager
c. proxyserver
启动某个节点的 proxyserver
$ yarn proxyserver
如果启动 YARN ProxyServer 服务,需要在 yarn-site.xml 文件中配置如下属性
<property>
<name>yarn.web-proxy.address</name>
<value>node3:8089</value>
</property>
d. daemonlog
使用方式
$ yarn daemonlog -getlevel <host:httpport> <classname>
$ yarn daemonlog -setlevel <host:httpport> <classname> <level>
查看帮助
$ yarn daemonlog
查看 RMAppImpl 的日志级别
$ yarn daemonlog -getlevel node2:8088 org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl
设置 RMAppImpl 的日志级别
$ yarn daemonlog -setlevel node2:8088 org.apache.hadoop.yarn.server.resourcemanager.rmapp.RMAppImpl DEBUG
e. rmadmin
使用方式
$ yarn rmadmin [options]
查看帮助
$ yarn rmadmin
重新加载 mapred-queues 配置文件
# 重新加载队列的ACL、状态和调度程序特定的属性,ResourceManager将重新加载mapred-queues配置文件。
$ yarn rmadmin -refreshQueues
刷新ResourceManager的主机信息
$ yarn rmadmin -refreshNodes
在ResourceManager上刷新NodeManager的资源
$ yarn rmadmin -refreshNodesResources
刷新超级用户代理组映射
$ yarn rmadmin -refreshSuperUserGroupsConfiguration
刷新 ACL 以管理 ResourceManager
$ yarn rmadmin -refreshAdminAcls
获取 ResourceManager 服务的 Active/Standby 状态
# 获取所有RM状态
$ yarn rmadmin -getAllServiceState
# 获取rm1的状态
$ yarn rmadmin -getServiceState rm1
# 获取rm2的状态
$ yarn rmadmin -getServiceState rm2
ResourceManager 服务执行健康检查
# 请求 ResourceManager 服务执行健康检查,如果检查失败,RMAdmin 工具将使用非零退出码退出。
$ yarn rmadmin -checkHealth rm1
$ yarn rmadmin -checkHealth rm2
f. timelineserver
启动 TimelineServer 服务
$ yarn-daemon.sh start timelineserver
启动完成以后,WEB UI 访问地址:http://node3:8188
g. scmadmin
scmadmin 是 ShareCacheManager(共享缓存管理)的管理客户端
使用方式
$ yarn scmadmin [options]
查看帮助
$ yarn scmadmin
执行清理任务
$ yarn scmadmin -runCleanerTask
先启动 SCM 服务(SharedCacheManager 服务)
$ yarn-daemon.sh start sharedcachemanager
2. 资源调度与隔离
在 YARN 中,资源管理由 ResourceManager 和 NodeManager 共同完成,其中,ResourceManager 中的调度器负责资源的分配,而 NodeManager 则负责资源的供给和隔离。
- 资源调度:ResourceManager 将某个 NodeManager 上资源分配给任务;
- 资源隔离:NodeManager 需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证;
Hadoop YARN 同时支持内存(memory)和 CPU(CPU virtual Core)两种资源的调度,先品味一下内存和 CPU 这两种资源的特点,这是两种性质不同的资源。内存资源的多少会会决定任务的生死,如果内存不够,任务可能会运行失败;相比之下,CPU 资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。
2.1 Mem 资源
YARN 允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给 YARN,一部分给 HDFS,一部分给 HBase 等,YARN 配置的只是自己可以使用的,配置参数如下:
yarn.nodemanager.resource.memory-mb
# 该节点上YARN可使用的物理内存总量,默认是8192MB;
# 如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities 为true时,将会自动计算操作系统内存进行设置。
yarn.nodemanager.vmem-pmem-ratio
# 任务每使用1MB物理内存,最多可使用虚拟内存量,默认是2.1
yarn.nodemanager.pmem-check-enabled
# 是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认true。
yarn.nodemanager.vmem-check-enabled
# 是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认true。
yarn.scheduler.minimum-allocation-mb
# 单个任务可申请的最少物理内存量,默认是1024MB,如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
yarn.scheduler.maximum-allocation-mb
# 单个任务可申请的最多物理内存量,默认是8192MB。
默认情况下,YARN 采用了线程监控的方法判断任务是否超量使用内存,一旦发现超量,则直接将其杀死。由于 Cgroups 对内存的控制缺乏灵活性(即任务任何时刻不能超过内存上限,如果超过,则直接将其杀死或者报 OOM),而 Java 进程在创建瞬间内存将翻倍,之后骤降到正常值,这种情况下,采用线程监控的方式更加灵活(当发现进程树内存瞬间翻倍超过设定值时,可认为是正常现象,不会将任务杀死),因此 YARN 未提供 Cgroups 内存隔离机制。
2.2 CPU 资源
在 YARN 中,CPU 资源的组织方式仍在探索中,当前只是非常粗粒度的实现方式。CPU 被划分成虚拟 CPU(CPU virtual Core),此处的虚拟 CPU 是 YARN 自己引入的概念,初衷是考虑到不同节点的 CPU 性能可能不同,每个 CPU 具有的计算能力也是不一样的,比如某个物理 CPU 的计算能力可能是另外一个物理 CPU 的 2 倍,此时可以通过为第一个物理 CPU 多配置几个虚拟 CPU 弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟 CPU 个数。
在 YARN 中,CPU 相关配置参数如下:
yarn.nodemanager.resource.cpu-vcores
# 该节点上YARN可使用的虚拟CPU个数,默认是8,注意,目前推荐将该值设值为与物理CPU核数数目相同。如果你的节点CPU核数不够8个,则需要调减小这个值。
# 如果设置为-1,并且yarn.nodemanager.resource.detect-hardware-capabilities为true时,将会自动计算操作系统CPU 核数进行设置。
yarn.scheduler.minimum-allocation-vcores
# 单个任务可申请的最小虚拟CPU个数,默认是1,如果一个任务申请的CPU个数少于该数,则该对应的值改为这个数。
yarn.scheduler.maximum-allocation-vcores
# 单个任务可申请的最多虚拟CPU个数,默认是4。
由于 CPU 资源的独特性,目前这种 CPU 分配方式仍然是粗粒度的。
3. 资源调度器
在 YARN 中,负责给应用分配资源的就是 Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,YARN 提供了多种调度器和可配置的策略供选择。
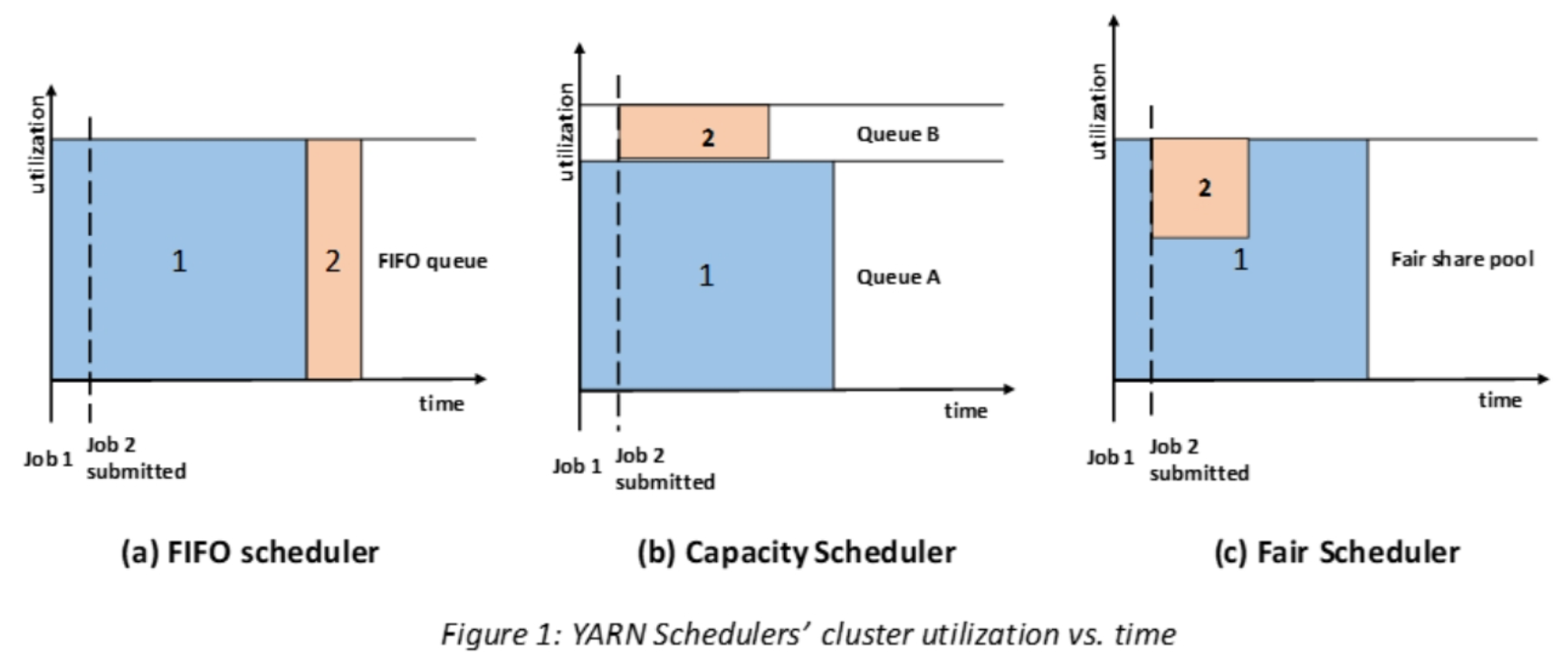
在 YARN 中有 3 种调度器可以选择:FIFO Scheduler(先进先出调度器) 、Capacity Scheduler(容量调度器)、Fair Scheduler(公平调度器)。
默认情况下,Apache 版本 YARN 使用的是 Capacity 调度器。如果需要使用其他的调度器,可以在 yarn-site.xml 中的 yarn.resourcemanager.scheduler.class 进行配置。
【工作队列】
工作队列(Queue)是从不同客户端收到的各种任务的集合。YARN 默认只有一个可用于提交任务的队列,叫做 default。当然用户也可以配置队列形成队列树结构。Scheduler 的本质就是根据何种规则策略去分配资源给队列中的任务。

【队列树】
在 YARN 中,有层级队列组织方法,它们构成一个树结构且根队列叫做 root。所有的应用都运行在叶子队列中(即树结构中的非叶子节点只是逻辑概念,本身并不能运行应用)。对于任何一个应用,都可以显式地指定它属于的队列,也可以不指定从而使用 username 或 default 队列。下图就是一个队列的结构:
root
|—— prod
|—— dev
|—— eng
|—— science
在 YARN WebUI 界面:http://node2:8088/cluster
3.1 FIFO Scheduler
FIFO Scheduler 是 MRv1 中 JobTracker 原有的调度器实现,此调度器在 YARN 中保留了下来。
FIFO Scheduler 是一个先进先出的思想,即先来的 Application 先运行。调度工作不考虑优先级和范围,适用于负载较低的小规模集群。当使用大型共享集群时,它的效率较低且会导致一些问题。
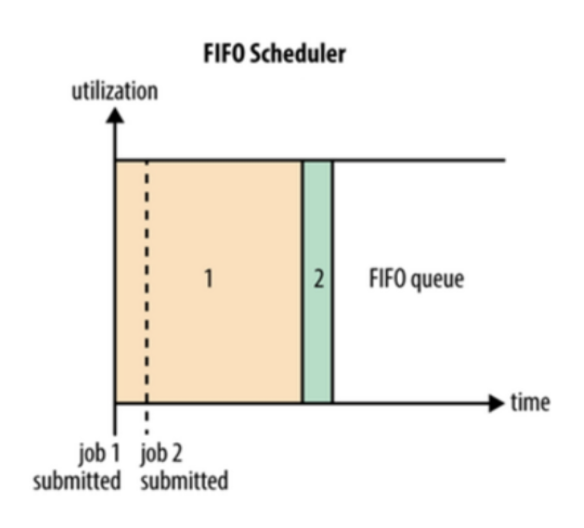
FIFO Scheduler 拥有一个控制全局的队列 queue,默认 queue 名称为 default,该调度器会获取当前集群上所有的资源信息作用于这个全局的 queue。
FIFO Scheduler 将所有的 Application 按照提交时候的顺序来执行,只有当上一个 Job 执行完成之后后面的 Job 才会按照队列的顺序依次被执行。虽然单一的 FIFO 调度实现简单,但是对于很多实际的场景并不能满足要求,催生了 Capacity 调度器和 Fair 调度器的出现。
-
优势:无需配置、先到先得、易于执行
-
坏处:任务的优先级不会变高,因此高优先级的作业需要等待;不适合共享集群
在 Hadoop YARN 中启用 FIFO 调度程序,修改 yarn-site.xml 即可
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fifo.FifoScheduler</value>
</property>
3.2 Capacity Scheducler
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。
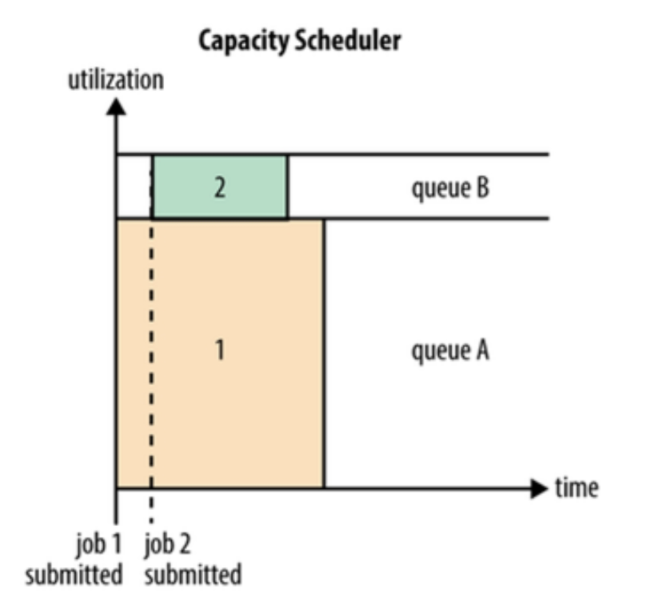
Capacity 调度器可以理解成一个个的资源队列,这个资源队列是用户自己去分配的。队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是 FIFO 策略。
a. 调度器说明
Capacity Scheduler以「队列」为单位划分资源。简单通俗点来说,就是一个个队列有独立的资源,队列的结构和资源是可以进行配置的,如下图:
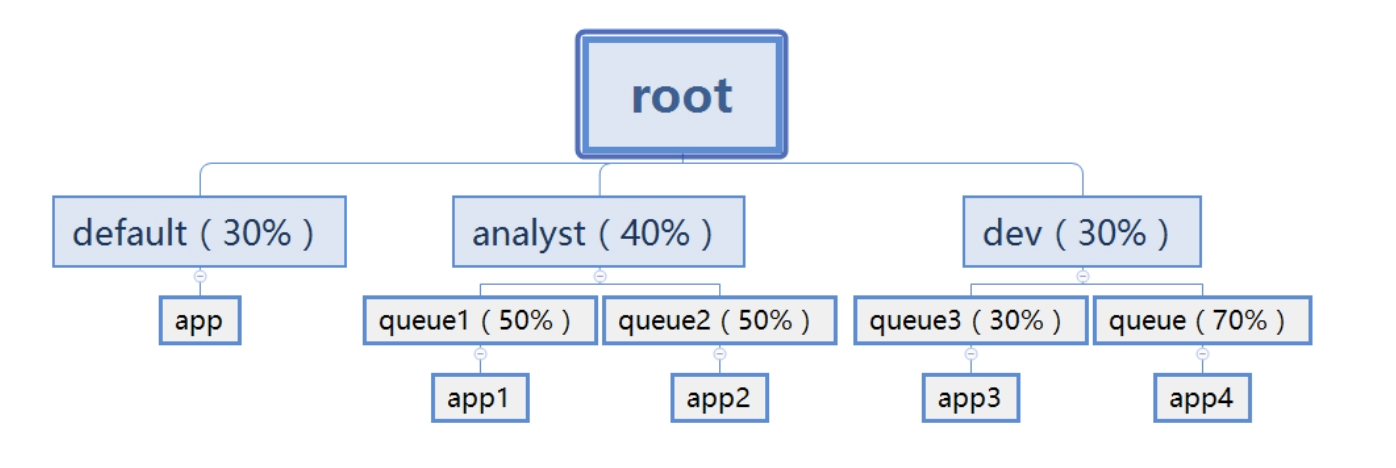
default 队列占 30% 资源,analyst 和 dev 分别占 40% 和 30% 资源;类似的,analyst 和 dev 各有两个子队列,子队列在父队列的基础上再分配资源。
- 队列里的应用以 FIFO 方式调度,每个队列可设定一定比例的资源最低保证和使用上限;
- 每个用户也可以设定一定的资源使用上限以防止资源滥用;
- 当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
资源分配算法:

b. 调度器特性
Capacity Scheduler 是一个可插拔调度程序,它被设计为以队列为单位划分资源、易于操作的方式在多租户模式下安全的共享大型集群,同时能保证每个组所需资源的保证,当容量不够用时还可以使用其他组多余的容量。这种方式最大程度地提高集群的吞吐量和利用率,以便在分配的容量约束下及时为其应用程序分配资源。
- 层次化的队列设计(Hierarchical Queues)层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
- 容量保证(Capacity Guarantees)队列上都会设置一个资源的占比,可以保证每个队列都不会占用整个集群的资源。
- 安全(Security )每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
- 弹性分配(Elasticity )空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
- 多租户租用(Multi-tenancy)通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提及哦啊的作业所占资源量进行限定。
- 操作性(Operability)YARN 支持动态修改调整容量、权限等的分配,可以在运行时直接修改。提供管理员界面,显示当前的队列状况。管理员可以在运行时,添加一个队列,但是不能删除一个队列。管理员可以在运行时暂停某个队列,可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了 stopped,那么就不能向它或者子队列上提交任务了。
- 基于资源的调度(Resource-based Scheduling)协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
- 基于用户/组的队列隐射(Queue Mapping based on User or Group)允许用户基于用户或者组去映射一个作业到特定队列。
c. 调度器配置
(1)开启调度器
在 ResourceManager 中配置使用的调度器,修改 HADOOP_CONF/yarn-site.xml 设置属性:
<property>
<name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
(2)配置队列
调度器的核心就是队列的分配和使用,修改 HADOOP_CONF/capacity-scheduler.xml 可以配置队列。调度器默认有一个预定义的队列 root,所有的队列都是它的子队列。队列的分配支持层次化的配置,使用 . 来进行分割:yarn.scheduler.capacity.<queue.path>.queues。
<!-- 根队列root下有3个子队列:a,b,c -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>a,b,c</value>
</property>
<!-- 队列a下有2个字队列:a1,a2 -->
<property>
<name>yarn.scheduler.capacity.root.a.queues</name>
<value>a1,a2</value>
</property>
<!-- 队列b下有3个子队列:b1,b2,b3 -->
<property>
<name>yarn.scheduler.capacity.root.b.queues</name>
<value>b1,b2</value>
</property>
(3)队列属性
- 队列的资源容量占比(百分比):系统繁忙时,每个队列都应该得到设置的量的资源;当系统空闲时,该队列的资源则可以被其他的队列使用。同一层的所有队列加起来必须是 100%。

- 队列资源的使用上限:系统空闲时,队列可以使用其他的空闲资源,因此最多使用的资源量则是该参数控制。默认是 -1,即禁用。

- 每个任务占用的最少资源:比如设置成 25,那么如果有 2 个用户提交任务,每个任务资源不超过 50%;如果 3 个用户提交任务,每个任务资源不超过 33%;如果 4 个用户提交任务,那么每个任务资源不超过 25%;如果 5 个用户提交任务,那么第 5 个用户需要等待才能提交。默认是 100,即不去做限制。

- 每个用户最多使用的队列资源占比:如果设置为 50,那么每个用户使用的资源最多就是 50%。

(4)运行和提交应用限制
- 设置系统中可以同时运行和等待的应用数量,默认是 10000;

- 设置有多少资源可以用来运行 app master,即控制当前激活状态的应用,默认是 10%。

(5)队列管理
- 队列的状态,可以是 RUNNING 或 STOPPED:如果队列是 STOPPED 状态,那么新应用不会提交到该队列或者子队列。同样,如果 root 被设置成 STOPPED,那么整个集群都不能提交任务了。现有的应用可以等待完成,因此队列可以优雅的退出关闭。

- 设置队列的管理员的 ACL 控制:为队列指定一个管理员,该管理员可控制该队列的所有应用程序,比如杀死任意一个应用程序等。同样,该属性具有继承性,如果一个用户可以向某个队列中提交应用程序,则它可以向它的所有子队列中提交应用程序。

(6)基于用户/组的队列映射
- 映射单个用户或者用户组到一个队列

- 语法:
[u or g]:[name]:[queue_name][,next_mapping]*,列表可以多个,之间以逗号分隔。 - %user 放在 [name] 部分,表示已经提交应用的用户。如果队列名称和用户一样,那可以使用 %user 表示队列。如果队列名称和用户主组一样,可以使用 %primary_group 表示队列。
u:%user:%user表示已经提交应用的用户,映射到和用户名称一样的队列;u:user2:%primary_group表示 user2 提交的应用映射到 user2 主组名称一样的队列上。如果用户组并不多,队列也不多,建议还是使用简单的语法,而不要使用带 % 的。
- 语法:
- 定义针对特定用户的队列是否可以被覆盖,默认值为 false。

(7)其他属性
- 资源计算方法:默认是 org.apache.hadoop.yarn.util.resource.DefaultResourseCalculator,它只会计算内存。DominantResourceCalculator 则会计算内存和 CPU。

- 调度器尝试进行调度的次数:节点局部性延迟,在容器企图调度本地机栈容器后(失败),还可以错过错过多少次的调度次数。一般都是跟集群的节点数量有关。默认 40(一个机架上的节点数)一旦设置完这些队列属性,就可以在 WebUI 上看到了。

(8)动态修改更新配置
如果想要修改队列或者调度器的配置,可以修改 HADOOP_CONF_DIR/capacity-scheduler.xml,修改完成后需要执行下面的命令:HADOOP_YARN_HOME/bin/yarn rmadmin -refreshQueues。
注意事项:
- 队列不能被删除,只能新增;
- 更新队列的配置需要是有效的值;
- 同层级的队列容量限制相加需要等于 100%;
- 在 MapReduce 中,可以通过 mapreduce.job.queuename 属性指定要用的队列。如果队列不存在,在提交任务时就会收到错误。如果没有定义任何队列,所有的应用将会放在一个 default 队列中。
d. 调度器案例
假设企业中需要针对 YARN 设置如下层次的队列树,满足不同租户的需求。要求使用 Capacity Scheduler 调度策略进行配置。
root
|—— prod # 生产上需要的队列
|—— dev # 开发上需要的队列
|—— eng # 开发·工程师队列
|—— science # 开发·科学家队列
上图中队列的一个调度器配置文件 HADOOP_CONF/capacity-scheduler.xml:
<?xml version="1.0"?>
<configuration>
<!-- 分为两个队列,分别为prod和dev -->
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<!-- dev继续分为两个队列,分别为eng和science -->
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<!-- 设置prod队列40% -->
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<!-- 设置dev队列60% -->
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<!-- 设置dev队列可使用的资源上限最多为75% -->
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<!-- 设置eng队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<!-- 设置science队列50% -->
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>
相关属性说明如下所示:
- dev 队列又被分成了 eng 和 science 两个相同容量的子队列;
- dev 的 maximum-capacity 属性被设置成了 75%,所以即使 prod 队列完全空闲 dev 也不会占用全部集群资源,也就是说 prod 队列仍有 25% 的可用资源用来应急;
- eng 和 science 两个队列没有设置 maximum-capacity 属性,也就是说 eng 或 science 队列中的 job 可能会用到整个 dev 队列的所有资源(最多为集群的 75%)。类似的,prod 由于没有设置 maximum-capacity 属性,它有可能会占用集群全部资源。
- 对于 Capacity Scheduler,队列名必须是队列树中的最后一部分,如果使用队列树则不会被识别。比如在上面配置中,使用 prod 和 eng 作为队列名是可以的,但是如果用 root.dev.eng 或 dev.eng 是无效的。
启动 ResouceManager,打开 8088 页面:
提交 MapReduce 程序,指定提交的队列是 prod:
$ cd /export/server/hadoop-3.1.4/share/hadoop/mapreduce
$ yarn jar hadoop-mapreduce-examples-3.1.4.jar pi -Dmapreduce.job.queuename=prod 2 2
注意!若不指定提交运行队列,默认是 default(如果找不到 default 队列则会报错)。
3.3 Fair Scheduler
FairScheduler 是 Hadoop 可插拔的调度程序,提供了 YARN 应用程序公平地共享大型集群中资源的另一种方式。FairScheduler 是一个将资源公平的分配给应用程序的方法,使所有应用在平均情况下随着时间的流逝可以获得相等的资源份额。
Fair Scheduler 设计目标是为所有的应用分配公平的资源(对公平的定义通过参数来设置)。公平调度是一个分配资源给所有 application 的方法,平均来看,是随着时间的进展平等分享资源的。
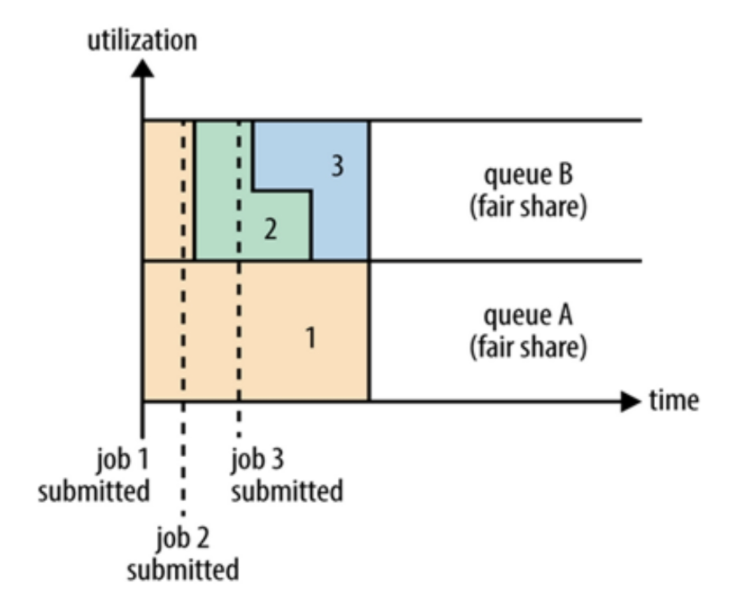
公平调度可以在多个队列间工作。如上图所示,假设有两个用户 A 和 B,分别拥有一个队列:
- 当 A 启动一个 job 而 B 没有任务时,A 会获得全部集群资源;
- 当 B 启动一个 job 后,A 的 job 会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。
- 如果此时 B 再启动第二个 job 并且其它 job 还在运行,则它将会和 B 的第一个 job 共享 B 这个队列的资源,也就是 B 的两个 job 会各自使用 1/4 的集群资源,而 A 的 job 仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
a. 调度器特性
FairScheduler 将应用组织到队列中,并在这些队列之间公平地共享资源。默认情况下,所有用户共享一个名为 default 的队列。如果应用明确在容器资源请求中指定了队列,则该请求将提交到指定的队列。可以通过配置,根据请求中包含的用户名或组分配队列。在每个队列中,使用调度策略在运行的应用程序之间共享资源。默认设置是基于内存的公平共享,但是也可以配置具有优势资源公平性的 FIFO 和多资源。

- 分层队列。队列可以按层次结构排列以划分资源,并可以配置权重以按特定比例共享集群。
- 基于用户或组的队列映射。可以根据提交任务的用户名或组来分配队列。如果任务指定了一个队列,则在该队列中提交任务。
- 资源抢占。根据应用的配置,抢占和分配资源可以是友好的或是强制的。默认不启用资源抢占。
- 保证最小配额。可以设置队列最小资源,允许将保证的最小份额分配给队列,保证用户可以启动任务。当队列不能满足最小资源时,可以从其它队列抢占。当队列资源使用不完时,可以给其它队列使用。这对于确保某些用户、组或生产应用始终获得足够的资源。
- 允许资源共享。即当一个应用运行时,如果其它队列没有任务执行,则可以使用其它队列,当其它队列有应用需要资源时再将占用的队列释放出来。所有的应用都从资源队列中分配资源。
- 默认不限制每个队列和用户可以同时运行应用的数量。可以配置来限制队列和用户并行执行的应用数量。限制并行执行应用数量不会导致任务提交失败,超出的应用会在队列中等待。
【设计目标】在时间尺度上,所有作业获得公平的资源。某一时刻一个作业应获资源和实际获取资源的差距叫“缺额”,调度器会优先为缺额大的作业分配资源。
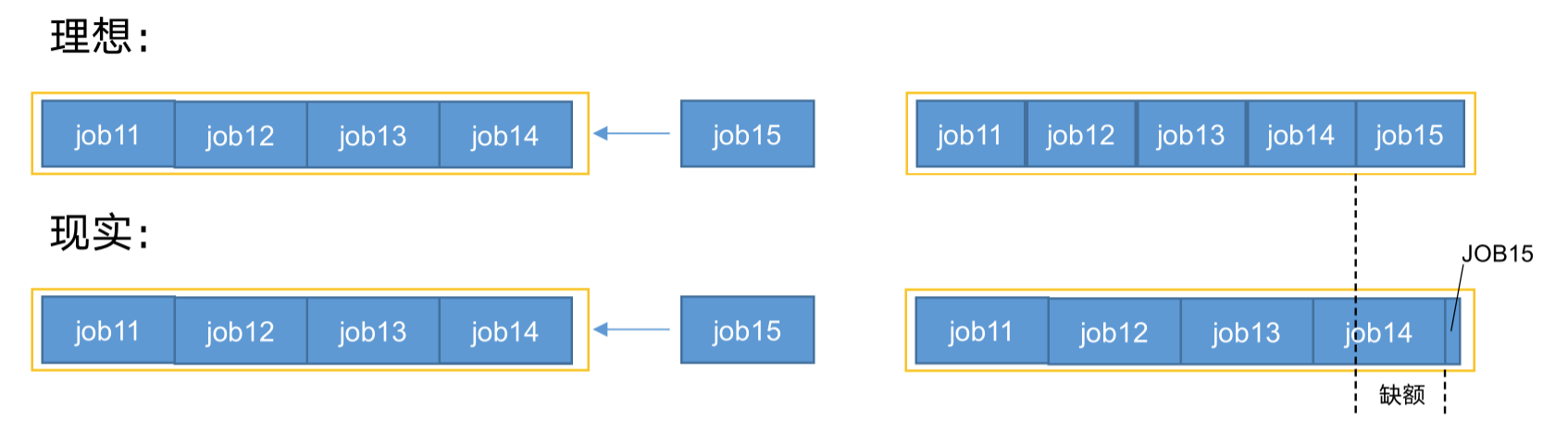
公平调度器队列资源分配方式:
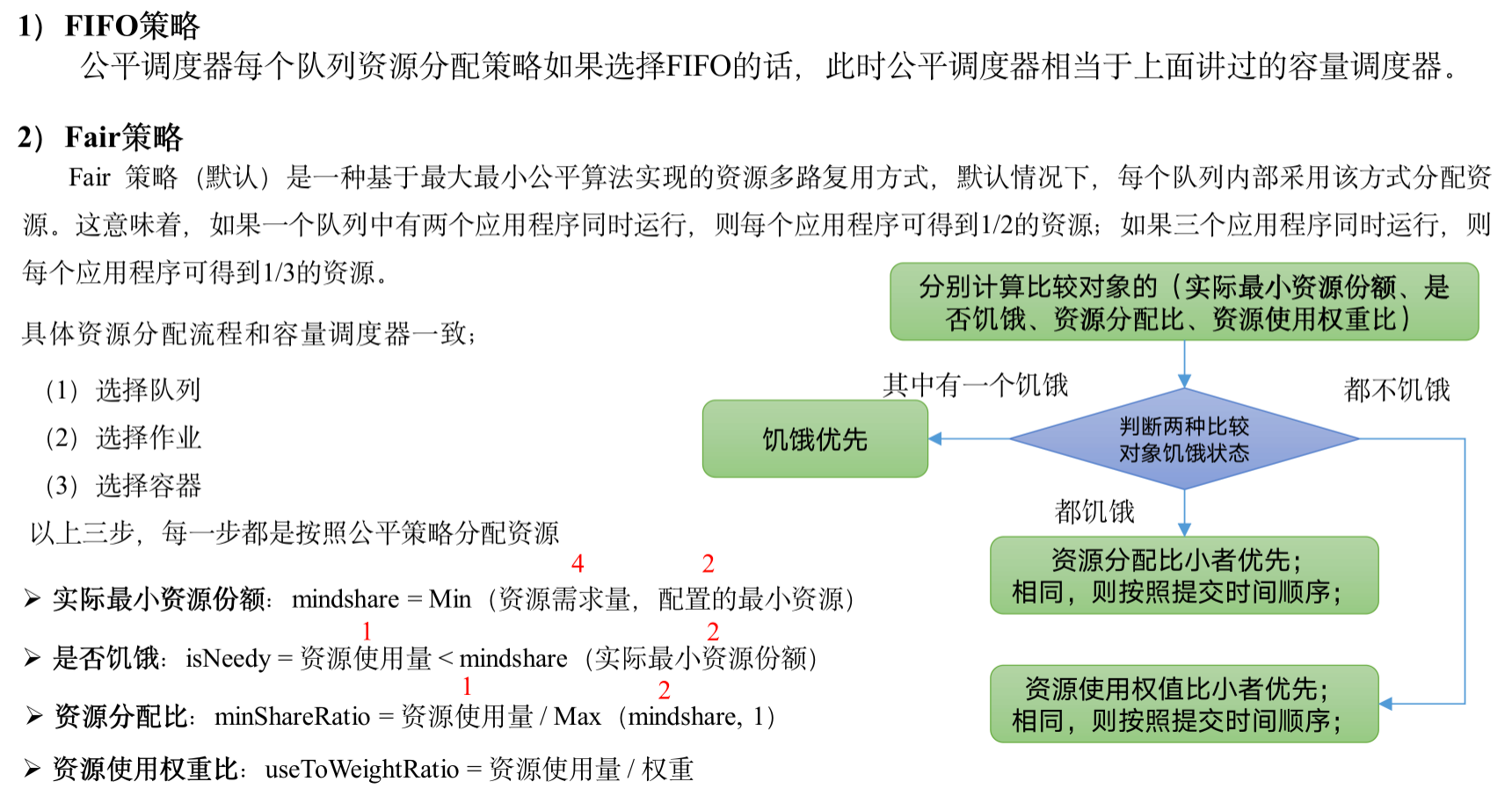

b. 启用调度器
开启&设置 Fair Scheduler 通常涉及 2 个配置文件。
(1)yarn-site.xml
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
Scheduler 调度器级别的有关的选项,比如开启,指定资源配置文件路径、抢占功能等。
(2)fair-scheduler.xml
资源分配文件,用来列举存在的 queues 和它们相应的 weights 和 capacities。
<!-- Path to allocation file, the file is searched for on the classpath -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<!-- 如果不指定全路径,表示在 HADOOP_CONF 路径下;通常指定全路径 -->
<value>fair-scheduler.xml</value>
</property>
allocation.file 每隔 10s 加载一次。若没有 fair-scheduler.xml 这个配置文件,Fair Scheduler 采用的分配策略:调度器会在用户提交第一个应用时为其自动创建一个队列,队列的名字就是用户名,所有的应用都会被分配到相应的用户队列中。
定制 Fair Scheduler 涉及到 2 个文件。首先,scheduler 有关的选项可以在 yarn-site.xml 中配置。此外,多数情况,用户需要创建一个「allocation.file」来列举存在的 queues 和它们相应的 weights 和 capacities。这个「allocation.file」每隔 10s 加载一次,更新的配置可以更快的生效。
c. 配置 yarn-site.xml
在 yarn-site.xml 中,主要用于配置调度器级别的参数:
(1)是否将与 allocation 有关的 username 作为默认的 queue name,当 queue name 没有指定的时候。如果设置成 false(且没有指定 queue name)或者没有设定,所有的 jobs 将共享 “default” queue。

(2)是否使用 preemption(优先权|抢占),默认为 fasle

(3)启动抢占后的资源利用率阈值。利用率是计算所有资源中容量使用的最大比率。默认值是 0.8f。

(4)在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配各个应用程序,而该参数则提供了另外一种资源分配方式:按照应用程序资源需求数目分配资源,即需求资源数量越多,分配的资源越多。默认情况下,该参数值为 false。

(5)是在允许在一个心跳中,发送多个 container 分配信息。

(6)如果 assignmultuple 为 true,在一次心跳中,最多发送分配 container 的个数。默认为 -1,无限制。

(7)一个 float 值,在 0~1 之间,表示在等待获取满足 node-local 条件的 containers 时,最多放弃不满足 node-local 的 container 的机会次数,放弃的 nodes 个数为集群的大小的比例。默认值 -1.0 表示不放弃任何调度的机会。

(8)当应用程序请求某个机架上资源时,它可以接受的可跳过的最大资源调度机会。

(9)是否根据 application 的大小(job 的个数)作为权重。默认为 false,如果为 true,那么复杂的 application 将获取更多的资源。

(10)如果设置为 true,application提 交时可以创建新的队列,要么是 application 指定了队列,或者是按照 user-as-default-queue 放置到相应队列。如果设置为 false,任何时间一个 app 要放置到一个未在分配文件中指定的队列,都将被放置到“default”队列。默认是 true。如果一个队列放置策略已经在分配文件中指定,本属性将会被忽略。

(11)默认值 500ms,锁住调度器重新进行计算作业所需资源的间隔。

d. 配置 fair-scheduler.xml
可以在 fair-scheduler.xml 中配置每一个队列,并且可以像 Capacity Scheduler 一样分层次配置队列,分配文件每 10s 重载一次,因此允许在运行时进行修改。
主要包括队列的层次、调度策略(整体策略和每个队列内策略)、队列设置及使用限制、抢占功能配置、最大最小资源、资源限制等。
简单配置案例如下。


e. 调度器案例
【多租户资源隔离】通常在企业内部,会涉及到多个业务线,多个部门共享集群环境的情况出现。如果不做资源的管理与规划,那么整个 YARN 的资源很容易被某一个用户提交的 Application 占满,其它任务只能等待,这种当然很不合理。希望每个业务都有属于自己的特定资源来运行任务,基于 YARN 中提供的 Fair Scheduler 实现多租户资源隔离。
yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- yarn之前的配置属性不需要修改 -->
<!-- 指定使用fairScheduler的调度方式 -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
</property>
<!-- 指定fair资源分配配置文件路径 -->
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>/export/server/hadoop-3.1.4/etc/hadoop/fair-scheduler.xml</value>
</property>
<!--
是否启用资源抢占,如果启用,那么当该队列资源使用
yarn.scheduler.fair.preemption.cluster-utilization-threshold
这么多比例的时候,就从其他空闲队列抢占资源
-->
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
</property>
<property>
<name>yarn.scheduler.fair.preemption.cluster-utilization-threshold</name>
<value>0.8f</value>
</property>
<!--
设置成true,当任务中未指定队列的时候,将以用户名作为队列名。
这个配置就实现了根据用户名自动分配队列。
-->
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
</property>
<!--
是否允许创建未定义的队列。
设置成true,yarn将会自动创建任务中指定的未定义过的队列。
设置成false,任务中指定的未定义的队列将无效,该任务会被分配到default资源池中。
如果在分配文件中给出了队列放置策略queuePlacementPolicy ,则将忽略此属性。
-->
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
</property>
</configuration>
fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<!-- 设置每个用户提交运行应用的最大数量为30 -->
<userMaxAppsDefault>30</userMaxAppsDefault>
<!-- 定义队列,所有队列都是root的子队列 -->
<queue name="root">
<aclSubmitApps> </aclSubmitApps>
<aclAdministerApps> </aclAdministerApps>
<queue name="hadoop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>2.0</weight>
<!-- 可以将应用程序提交到队列的用户和/或组的列表 -->
<!-- 格式为:用户名 用户组 -->
<!-- 多个用户时:user1,user2 group1,group2 -->
<aclSubmitApps>hadoop hadoop</aclSubmitApps>
<!-- 允许管理任务的用户名和组,格式同上 -->
<aclAdministerApps>hadoop hadoop</aclAdministerApps>
</queue>
<queue name="spark">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<aclSubmitApps>spark spark</aclSubmitApps>
<aclAdministerApps>spark spark</aclAdministerApps>
</queue>
<queue name="develop">
<minResources>512mb,4vcores</minResources>
<maxResources>20480mb,20vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fifo</schedulingMode>
<weight>1.5</weight>
<aclSubmitApps>hadoop,develop,spark</aclSubmitApps>
<aclAdministerApps>hadoop,develop,spark</aclAdministerApps>
</queue>
<!-- 所有的任务如果不指定任务队列,都提交到default队列里面来 -->
<queue name="default">
<minResources>512mb,4vcores</minResources>
<maxResources>30720mb,30vcores</maxResources>
<maxRunningApps>100</maxRunningApps>
<schedulingMode>fair</schedulingMode>
<weight>1.0</weight>
<aclSubmitApps>*</aclSubmitApps>
</queue>
</queue>
</allocations>
在 YARN WebUI(8088) 页面上点击 Scheduler 进行查看:
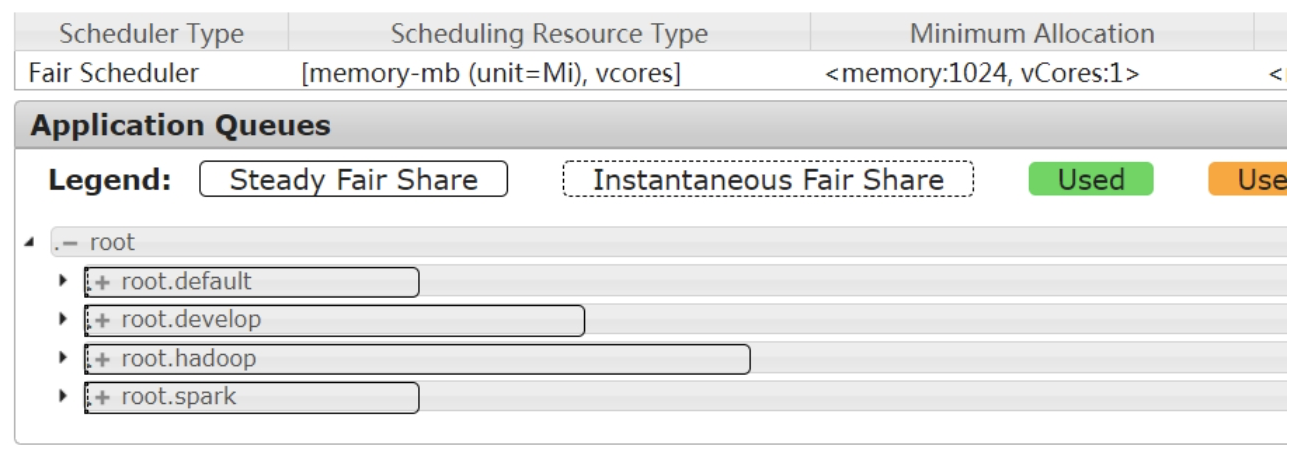
4. YARN 核心参数
在实际项目生产环境,需要调整配置 YARN 相关核心参数的值,才能更好的管理资源、调度任务执行及使用资源。
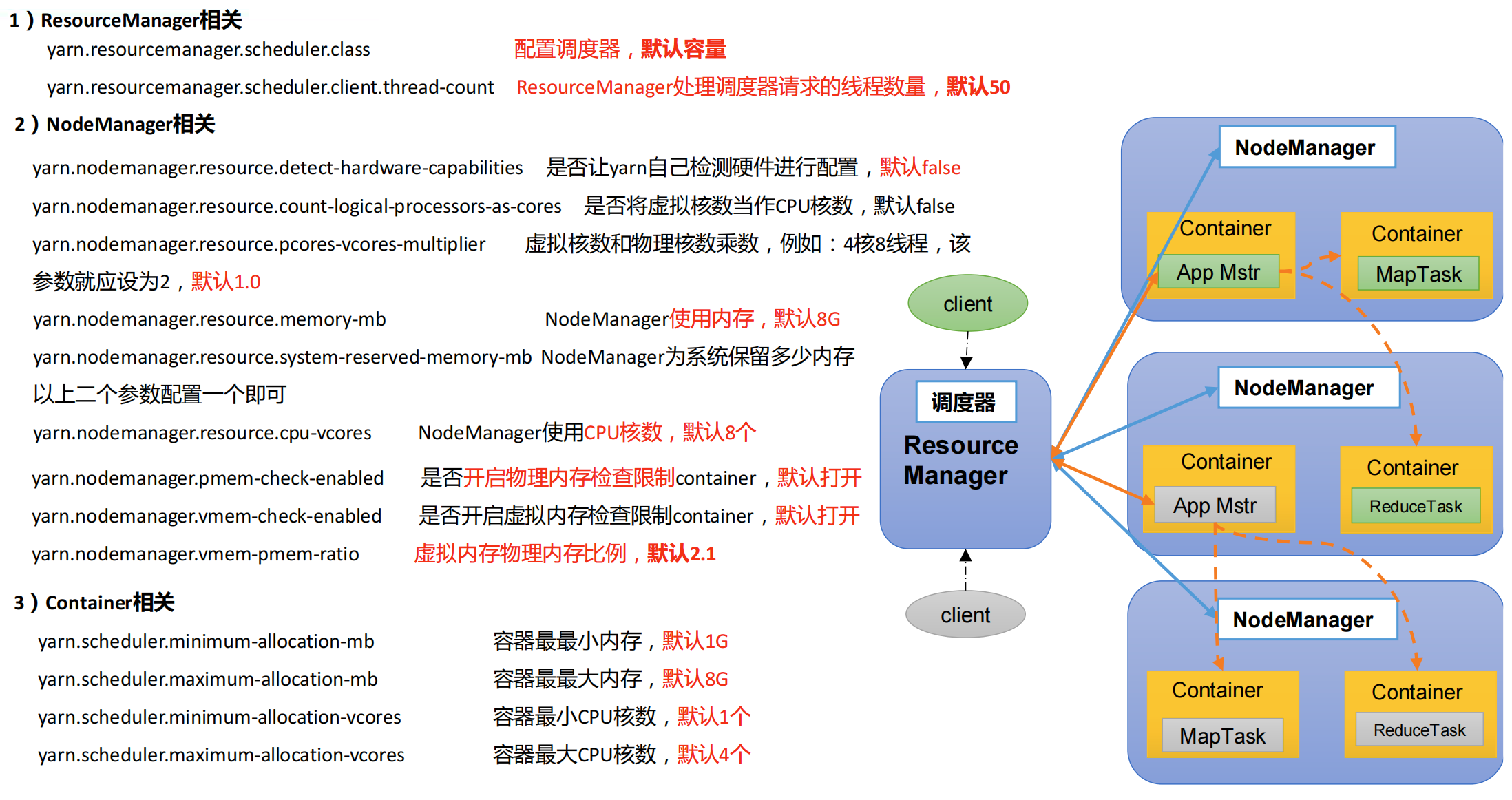
4.1 RM 核心参数
针对 ResourceManager 主节点来说,需要设置调度器类型及请求线程数据量。
(1)yarn.resourcemanager.scheduler.class
设置 YARN 使用调度器,默认值(不同版本 YARN 对应值不一样):
- Apache 版本 YARN 的默认值为容量调度器:org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
- CDH 版本 YARN 的默认值为公平调度器:org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler
(2)yarn.resourcemanager.scheduler.client.thread-count
ResourceManager 处理调度器请求的线程数量,默认 50,如果 YARN 运行任务 Job 比较多,可以将值调整大一下。
4.2 NM 核心参数
NodeManager 运行在每台机器上,负责具体的资源管理:
(1)yarn.nodemanager.resource.detect-hardware-capabilities
是否让 YARN 自己检测硬件进行配置,默认 false,如果设置为 true,那么就会自动探测 NodeManager 所在主机的内存和 CPU。
(2)yarn.nodemanager.resource.count-logical-processors-as-cores
是否将虚拟核数当作 CPU 核数,默认 false。
(3)yarn.nodemanager.resource.pcores-vcores-multiplier
虚拟核数和物理核数乘数,例如:4 核 8 线程,该参数就应设为 2,默认 1.0。
(4)yarn.nodemanager.resource.memory-mb
NodeManager 使用内存,默认8G
(5)yarn.nodemanager.resource.system-reserved-memory-mb
此参数仅仅当上述 param1=true 和 param4=-1 时,设置才生效。
默认值:20% of (SYS_MEMORY - 2*HADOOP_HEAPSIZE)
(6)yarn.nodemanager.resource.cpu-vcores
NodeManager 使用 CPU 核数,默认 8 个。
(7)其他参数,使用默认值即可
- yarn.nodemanager.pmem-check-enabled,是否开启物理内存检查限制 container,默认打开;
- yarn.nodemanager.vmem-check-enabled,是否开启虚拟内存检查限制 container,默认打开;
- yarn.nodemanager.vmem-pmem-ratio,虚拟内存物理内存比例,默认 2.1;
4.3 Container 核心参数
当应用程序提交运行至 YARN 上时,无论是 AppMaster 运行,还是 Task(MapReduce 框架)或 Executor(Spark 框架)或 TaskManager(Flink 框架)运行,NodeManager 将资源封装在 Contanier 容器中,以便管理和监控,核心配置参数如下所示:
(1)yarn.scheduler.minimum-allocation-mb
单个任务可申请的最少物理内存量,默认是 1024 MB,如果一个任务申请的物理内存量少于该值,则该对应的值改为这个数。
(2)yarn.scheduler.maximum-allocation-mb
单个任务可申请的最多物理内存量,默认是 8192 MB。
(3)yarn.scheduler.minimum-allocation-vcores
单个任务可申请的最小虚拟 CPU 个数,默认是 1,如果一个任务申请的 CPU 个数少于该数,则该对应的值改为这个数。
(4)yarn.scheduler.maximum-allocation-vcores
单个任务可申请的最多虚拟 CPU 个数,默认是 4。