1.安装cuda
可以先看看自己的 显卡信息,支持哪个cuda版本
cuda下载地址:https://developer.nvidia.com/cuda-toolkit-archive
我的RTX3060,下载的cuda11.8
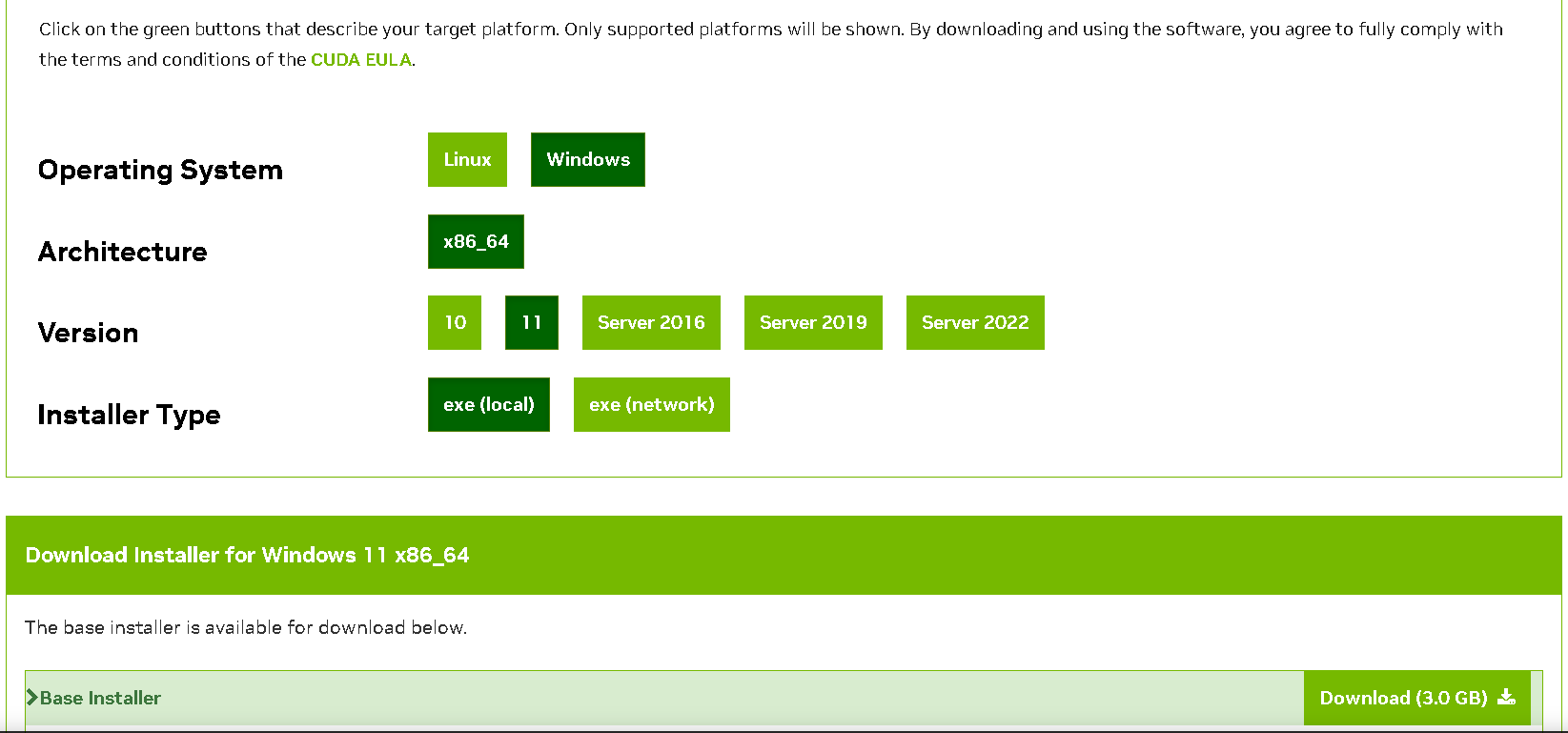
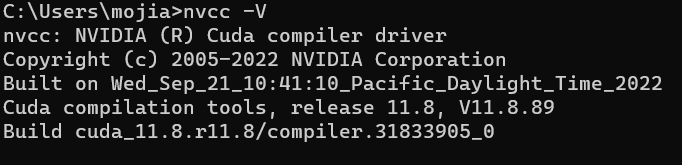
下载后安装,直接默认安装到底,然后打开cmd,输入nvcc -V
2.安装cudnn
需要安装和cuda版本对应的cudnn
地址:https://developer.nvidia.com/rdp/cudnn-archive
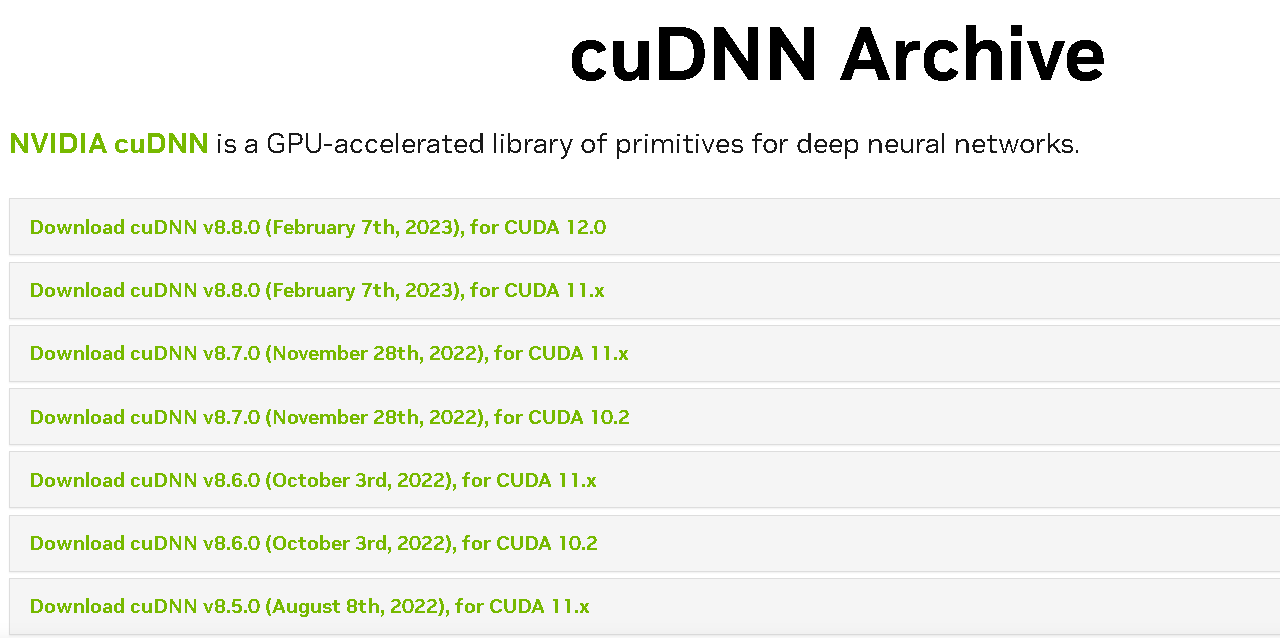
下载对应的版本,解压替换到cuda安装目录下
3.安装Pytorch
我使用的是conda默认的环境,python3.9
进入pytorch官网:https://pytorch.org/
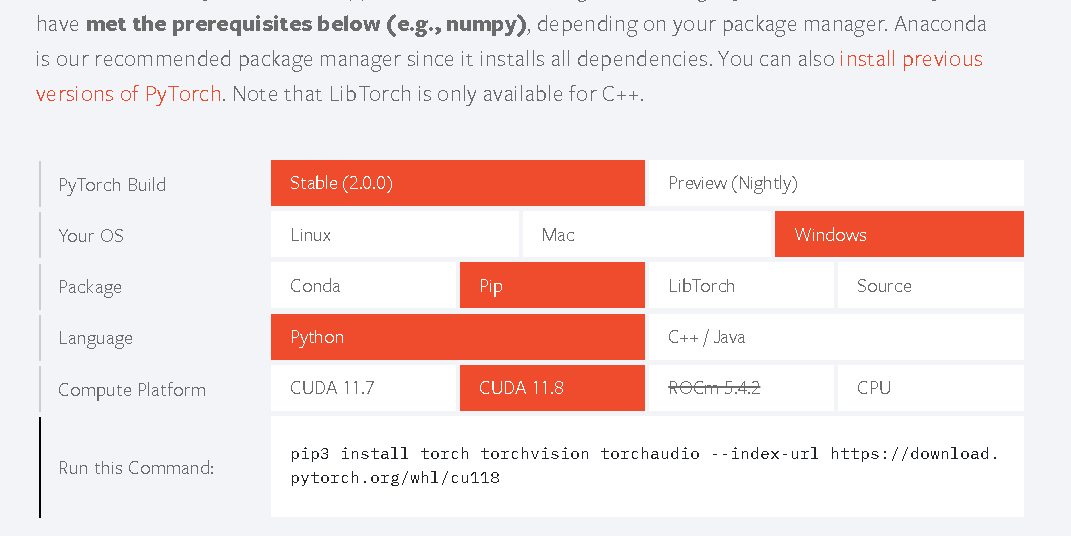
找到对应的版本下载,我这里不指定torch版本,直接运行
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
等待安装完成即可
4.安装标注软件
pip install labelImg
安装成功后直接运行 labelImg 打开软件
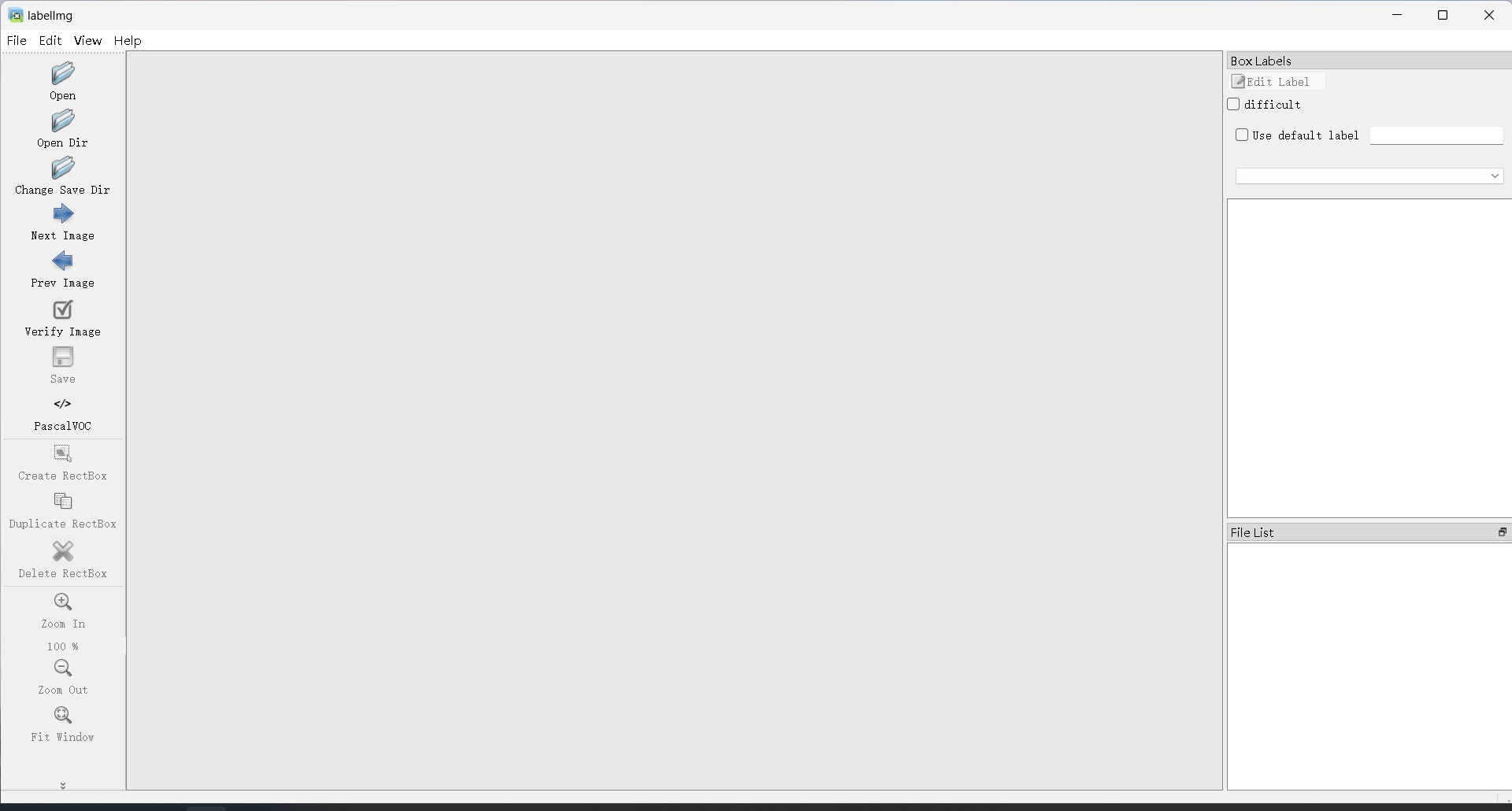
open dir打开图片文件夹,change save dir 选择保存的xml文件的文件夹
create rectBox去框选需要检测的目标,输入label name
标注完自己的数据

一个img图片文件夹, 一个和图片对应的xml文件夹
5. 将数据集进行分割
执行下面代码,即可得到分割好的数据集
import os import random import shutil img_path = 'img' xml_path = 'xml' def split_file_name(file_name): f_name, _ = file_name.split('.') return f_name def split_move_file(target_path, save_basic_path, train_scale=0.9): train_img_path = os.path.join(save_basic_path, 'images/train') train_xml_path = os.path.join(save_basic_path, 'xml/train') val_img_path = os.path.join(save_basic_path, 'images/val') val_xml_path = os.path.join(save_basic_path, 'xml/val') print(save_basic_path, train_img_path) if not os.path.exists(train_img_path): os.makedirs(train_img_path) if not os.path.exists(train_xml_path): os.makedirs(train_xml_path) if not os.path.exists(val_img_path): os.makedirs(val_img_path) if not os.path.exists(val_xml_path): os.makedirs(val_xml_path) img_file_path = os.path.join(target_path, img_path) file_list = os.listdir(img_file_path) # print(file_list) # 得到名字列表 file_name_li = list(map(lambda x: split_file_name(x), file_list)) random.shuffle(file_name_li) # print(file_name_li) train_ind = int(len(file_name_li) * train_scale) train_data = file_name_li[:train_ind] val_data = file_name_li[train_ind:] print('total number', len(file_name_li)) print('train number', len(train_data)) print('val number', len(val_data)) for file in train_data: file_path = os.path.join(img_file_path, file+'.jpg') save_path = os.path.join(train_img_path, file+'.jpg') if not os.path.exists(file_path): file_path = os.path.join(img_file_path, file + '.jpeg') save_path = os.path.join(train_img_path, file + '.jpg') if not os.path.exists(file_path): file_path = os.path.join(img_file_path, file + '.png') save_path = os.path.join(train_img_path, file + '.png') if os.path.exists(file_path): shutil.copyfile(file_path, save_path) # xml文件 xml_file_path = os.path.join(target_path, xml_path) file_path = os.path.join(xml_file_path, file + '.xml') save_path = os.path.join(train_xml_path, file + '.xml') if os.path.exists(file_path): shutil.copyfile(file_path, save_path) for file in val_data: file_path = os.path.join(img_file_path, file+'.jpg') save_path = os.path.join(val_img_path, file+'.jpg') if not os.path.exists(file_path): file_path = os.path.join(img_file_path, file + '.jpeg') save_path = os.path.join(val_img_path, file + '.jpg') if not os.path.exists(file_path): file_path = os.path.join(img_file_path, file + '.png') save_path = os.path.join(val_img_path, file + '.png') if os.path.exists(file_path): shutil.copyfile(file_path, save_path) # xml文件 xml_file_path = os.path.join(target_path, xml_path) file_path = os.path.join(xml_file_path, file + '.xml') save_path = os.path.join(val_xml_path, file + '.xml') if os.path.exists(file_path): shutil.copyfile(file_path, save_path) if __name__ == '__main__': target_path = r'C:\Users\mojia\Desktop\maizi\maozi20230326' save_basic_path = r'C:\Users\mojia\Desktop\maizi\maozi20230326_train_val' if not os.path.exists(save_basic_path): os.mkdir(save_basic_path) scale = 0.9 # 训练集比例 split_move_file(target_path, save_basic_path, scale)
6. 将标注的xml文件转换为txt文件格式
import xml.etree.ElementTree as ET import os def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh if w >= 1: w = 0.99 if h >= 1: h = 0.99 return (x, y, w, h) folder_li = ['train', 'val'] def convert_annotation(rootpath, classes): labelpath = rootpath + '/labels' # 生成的.txt文件会被保存在labels目录下 if not os.path.exists(labelpath): os.makedirs(labelpath) for folder in folder_li: xmlpath = rootpath + '/xml/'+folder file_list = os.listdir(xmlpath) for xmlname in file_list: xmlfile = os.path.join(xmlpath, xmlname) with open(xmlfile, "r", encoding='UTF-8') as in_file: txtname = xmlname[:-4] + '.txt' # print(txtname) txtpath = labelpath + '/' + folder if not os.path.exists(txtpath): os.makedirs(txtpath) txtfile = os.path.join(txtpath, txtname) with open(txtfile, "w+", encoding='UTF-8') as out_file: tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) out_file.truncate() for obj in root.iter('object'): difficult = obj.find('difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') if __name__ == "__main__": rootpath = r'C:\Users\mojia\Desktop\maizi\maozi20230326_train_val' # 数据标签 classes = ['帽子'] # 需要修改 convert_annotation(rootpath, classes)
得到下面这个的目录结构

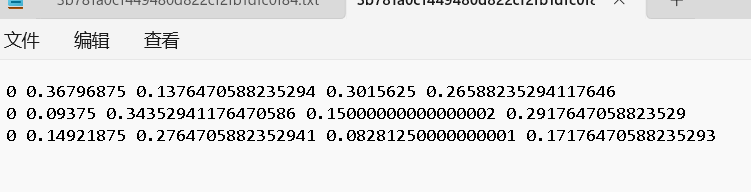
txt文件里有标签索引和归一化后的坐标和宽高信息
7.下载yolov5源码
直接将代码下载到本地,我下载的时v7.0
下载版本对应的与训练模型

8.修改训练的数据集路径及参数
修改data/coco128.yaml,给出数据集的路径

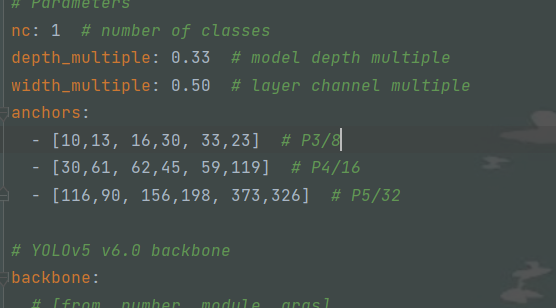
修改models/yolov5s.yaml,注意我训练时用的yolov5s.pt。这里主要将标签数改成一样的,nc字段改为1个,我只标了一个。
修改train.py,这个我只将device改为0,也就是启用GPU训练,其他参数没有改变,或者在运行train.py时传入参数也一样。

直接运行 python train.py
9.查看训练结果
可以查看损失函数,准确率等信息
训练好的结果在run/train文件夹下面,找到最新的文件夹
可以运行tensorboard --logdir=C:\Users\mojia\Desktop\yolov5-master\runs\train\exp14 通过浏览器查看运行的结果
训练好的权重参数保存在weights文件夹下面
10.进行预测
修改detect.py文件, 修改使用的权重文件,和检测的目标文件

运行 python detect.py
结果保存在/runs/detect路径下最新的文件夹里
