学习目标
掌握安装第三方模块的方法
掌握requests库的常用方法与返回值
掌握requests下载保存数据
核心知识
系统库(像socket、os)与第三方库的唯一区别就是:一个是默认自带不需要下载安装的库,一个是需要下载安装的库。
requests库是网络请求库,非常的简单使用,常用于爬虫,文件下载,漏洞验证等许多业务区。
安装第三方库
安装python后会默认安装pip,pip是下载与安装第三方模块的工具
pip3 install 第三方库名
pip镜像源,国内源可以加快下载速度用-i参数
pip install xxx库 -i https://pypi.tuna.tsinghua.edu.cn/simple
请求方式
head方式
head头请求-->少网络流量获得概要信息,如:请求头,状态码,速度极快->目录扫描
import requests
url = 'https://www.baidu.com'
r = requests.head(url)
# 状态码,整数类型
print(r.status_code)
# 请求的网址,字符串类型
print(r.url)
# 请求头,字典类型
print(r.headers)
# 网页的编码,字符串类型
print(r.encoding)
# 保存的cookie
print(r.cookies)
get方式
get请求数据-->发起请求,获取完整的数据,速度慢->获取网页内容,爬虫,poc编写
import requests
url = 'https://www.baidu.com'
r = requests.get(url)
print(r.text)
# 请求的网页的内容,自动编码,但是有几率会乱码,不建议使用
print(r.content)
# 请求的网页的内容--bytes格式,如果要转中文字符串,需要调用decode()方法
print(r.content.decode('utf-8'))
# 请求的网页的内容--字符串格式,自动转换成中文,不同网站编码不同
print(r.url)
# 请求的网址,字符串类型
print(r.headers)
# 请求头,字典类型
print(r.status_code)
# 状态码,整数类型
print(r.encoding)
# 网页的编码,字符串类型
print(r.cookies)
# 保存的cookie
post方式
psot发送数据-->主动服务器提交数据,返回获取完整的数据-->提交数据,获取网页返回的结果,爬虫,poc编写
发送的数据需要用字典格式保存
d = {'user':'admin','password':'123456'}
r = requests.post(url='http://xxx.com',data=d)
重要设置
超时设置
如果希望访问网站时间3s还未响应,可以用timeout参数实现
import requests
r = requests.get('https://www.baidu.com',timeout=3)
请求头设置
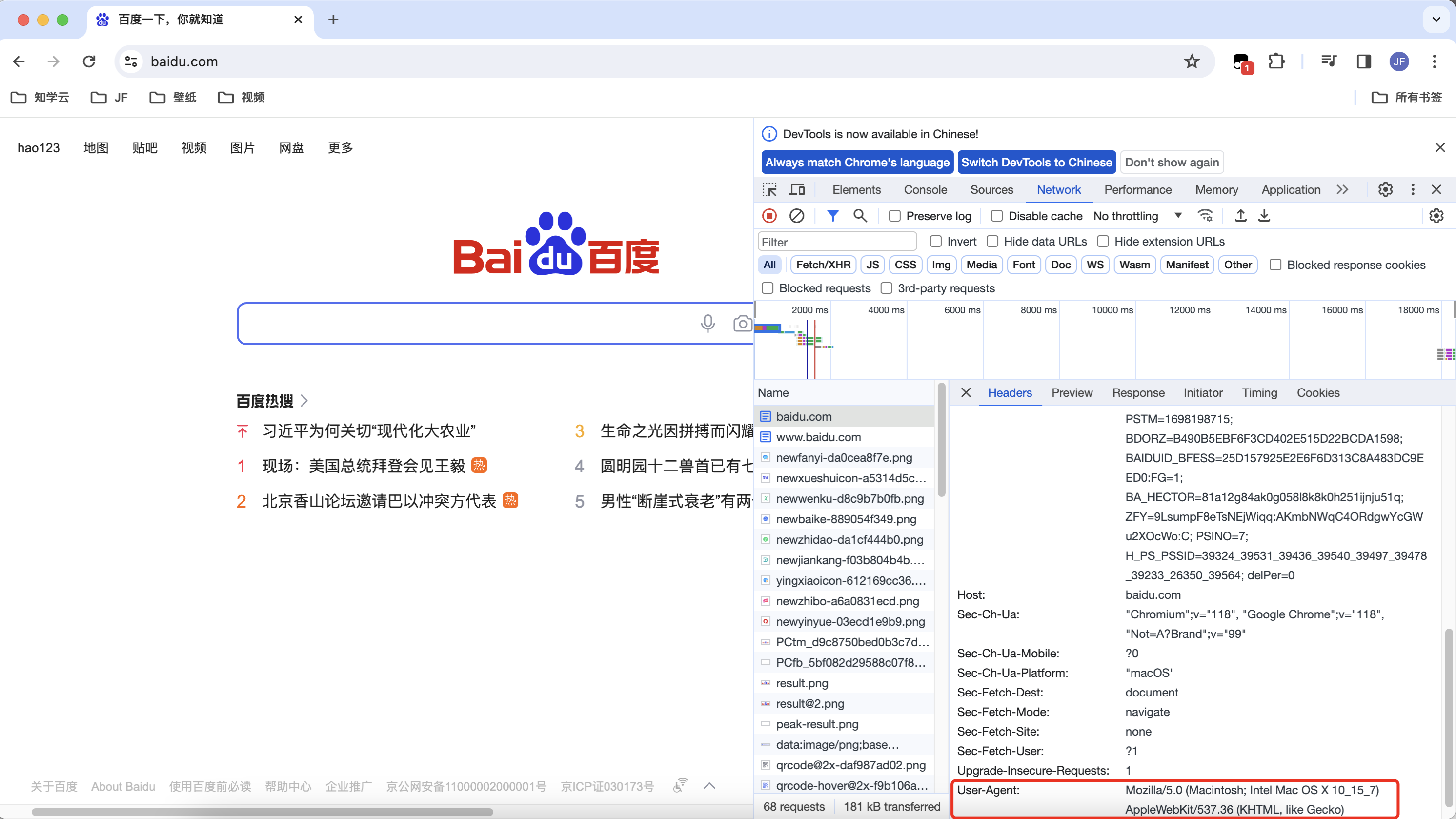
该设置是为了伪装成浏览器去请求,请求头是字典格式的,浏览器f12打开直接复制UA头
import requests
header = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'}
r = requests.get('https://www.baidu.com',timeout=3,headers=header)
不检测https证书
requests会对https网址验证ssl证书,如果证书验证失败,则会抛出异常,我们可以通过以下方法设置不检测
requests.packages.urllib3.disable_warnings()
verify=False
import requests
requests.packages.urllib3.disable_warnings()
header = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'}
r = requests.get('https://www.baidu.com',timeout=3,headers=header,verify=False)
禁止网页重定向
requests 会自动处理所有重定向,可以通过参数设置禁止重定向
allow_redirects=False
import requests
requests.packages.urllib3.disable_warnings()
header = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36'}
r = requests.get('https://www.baidu.com',timeout=3,headers=header,verify=False,allow_redirects=False)
保存数据
保存网页内容
import requests
r = requests.get('https://www.baidu.com')
con = r.content.decode('utf-8')
a = [i for i in open('bd.txt','a+',encoding='utf-8').write(con)]
保存图片数据
import requests
r = requests.get('https://lmg.jj20.com/up/allimg/1113/052420110515/200524110515-2-1200.jpg')
with open('tp.jpg','wb')as a:
a.write(r.content)
保存视频数据
import requests
r = requests.get('http://www.xxx.com/xxx.mp4',stream=True)
for it in r.iter_content():
with open('视频.mp4','wb')as a:
a.write(it)
应用场景
暴力破解、撞库、爬虫等场景下使用
模拟网站的登陆,查看,下载数据
POC/EXP的编写,漏洞扫描器网络请求
总结归纳
掌握requests最常用的三种请求方式:head/get/post
掌握requests参数的设置
掌握requests返回值
掌握requests如何保存数据