前言 本篇开始对遥感图像的目标检测进行介绍,介绍了其目标前景、数据集以及评价指标。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【CV技术指南】CV全栈指导班、基础入门班、论文指导班 全面上线!!
遥感图像介绍
本文介绍的是可见光遥感图像上的目标检测,首先我们来了解一下什么是遥感图像,遥感图像,也称为高分辨率遥感图像(Very High-resolution Imagery),但是在遥感图像的领域内,除了可见光遥感图像之外,还有其他两种遥感图像,一种是高光谱遥感图像(Hyperspectral Imagery),一种是雷达遥感图像(Synthetic Aperture Radar Imagery),其分类依据是根据成像的介质不同来进行分类的。我们主要用到的是高分辨率遥感图像,接下来说以下可见光遥感图像的成像优点。第一,其成像方式更符合我们人类眼睛成像方式;第二,其分辨率超高,能以更精细的分辨率产生地球表面的全色多光谱图像;第三,基于成像特点,对于进行图像分析(检测、分割等)十分友好。用一张图片直观的了解一下三种遥感图像的区别:
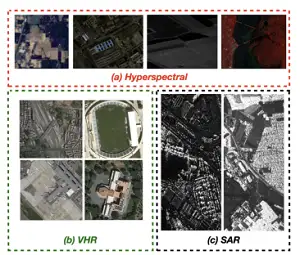
遥感图像特点及应用前景
遥感图像图像特点主要包含如下几个方面:
- 背景复杂,目标信息少,背景信息多。
- 图像中物体的方向各不相同,这点在水平视角中不存在。
- 基于遥感图像的拍摄尺度高,导致图像中有较多的小物体。
- 目标尺度多样性复杂,一张图片中可能会同时存在飞机与汽车,明显飞机的尺度远远高于汽车的尺度。
- 图像中目标密集程度高,一张图片中可能会有多个目标,比如露天停车场。
上面这些特点,也是遥感图像算法设计中需要突出解决的问题。
简单总结遥感图像应用,我们从军用与民用的角度划分:
- 军用角度:舰船、飞机的检测、定位、追踪。
- 民用角度:港口调度、资源勘探、森林防护。
可见光遥感图像目标检测
目标检测是一个比较“古老”的话题了,它的分水岭是在2014年,以前的方法我们不做介绍,这里们说一下14年以后的深度学习具有代表性的算法。主流分为两类算法 — 一阶段检测与二阶段检测。二阶段比较早出现的,代表的算法有R-CNN、 FAST-RCN、 SPP-NE、 FASTER-RCNN。一阶段出现较晚,代表算法有YOLOV1 ------ YOLOV7系列等,后续还有anchor free系列的方法,Query-based以Transformer为代表的方法等等。
旋转目标检测(Oriented Object Detect)可以看作是目标检测的一个子集,它与通用的目标检测最大的不同之处在于我们需要在定位目标位置及其宽高的基础上还需要额外回归出其朝向。最常见的是在遥感图像中的目标检测任务,通过卫星、航空航天器等拍摄的图片中存在各种带有方向属性的目标比如船只,汽车等。由于这些目标在遥感图像中尺寸一般较小,传统的矩形框很难贴合满足我们的要求,这个时候就需要加上朝向来得到一个更为贴合的矩形框。
数据集
深度学习离不开数据集,只有大规模的数据才能得到更优秀的模型,下面介绍一下关于可见光遥感图像的数据集。
- DOTA系列数据集:2018年武汉大学首发DOTA1.0版本的数据集共分为15个类别,采用定向边界框的标注方式。DOTA数据集1.5版本共分为16个类别,DOTA数据集2.0版本共分为18个类别,DOTA数据集在数据的类别与质量上都明显优于其他遥感方向的数据集。随着版本的提升检测的挑战性越来越大,其中顶会论文使用1.0版本与1.5版本居多,鲜有用2.0版本。
- HRSC2016数据集:西北工业大学发布的数据集,包含从几个著名港口收集的大量条形定向物体,外观不同,用于船舶识别。整个数据集有1061幅图像,从300 × 300到1500 × 900不等。
- UCAS-AOD数据集:拥有1510张图片,其中510张汽车图片和1000张飞机图片。总共有14,596个实例。整个数据集按照5:2:3的比例随机分为755张用于训练的图像、302张用于验证的图像和453张用于测试的图像。所有图像的大小约为1280 × 659。
- DIOR数据集:含23463张图片和190288实例,覆盖20种目标,大小为800×800,比DOTA数据集更大!这20个对象类是飞机、机场、棒球场、篮球场、桥梁、烟囱、水坝、高速公路服务区、高速公路收费站、港口、高尔夫球场、地面田径场、天桥、船舶、体育场、储罐、网球场、火车站、车辆和风磨。
- LEVIR数据集:由大量 800 × 600 像素和0.2m〜1.0m /像素的高分辨率Google Earth图像和超过22k的图像组成。LEVIR数据集涵盖了人类居住环境的大多数类型地面特征,例如城市,乡村,山区和海洋。数据集中未考虑冰川,沙漠和戈壁等极端陆地环境。数据集中有3种目标类型:飞机,轮船(包括近海轮船和向海轮船)和油罐。所有图像总共标记了11k个独立边界框,包括4,724架飞机,3,025艘船和3,279个油罐。数据集图像简略观看 提供了四张图片,2张来自DOTA数据集,2张来自HRSC2016数据集


不在贴放更多图片,提供了数据集的下载地址,有兴趣自己下载。
LEVIR数据集下载地址:https://pan.baidu.com/s/1eUAq2PszdHeE2VSG3q5cw 提取码: j9jp
DOTA数据集下载地址:https://pan.baidu.com/s/1o4Tsx7hgh2a2O73kxJRVLg 提取码: yvi1
UCAS-AOD数据集下载地址:https://pan.baidu.com/s/1Poo0zEHTHDfBTnKPb5YTCg 提取码: 7zsi
HRSC2016数据集下载地址:https://pan.baidu.com/s/1Sz2aohknDVCYrnXcnPQuaQ 提取码: 7fx1
常见评估指标
旋转目标检测的评估指标与通用目标检测指标基本一致采用AP50或mAP来评估,需要注意的是计算IOU的时候要使用旋转框来计算交并比。
另外在实验分析中我们也可以将角度偏小的水平框和角度偏大的旋转框分别评估AP来判断当前算法是否对大的角度目标有很好的性能。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
其它文章
一次性分割一切,比SAM更强,华人团队的通用分割模型SEEM来了
CVPR'23|向CLIP学习预训练跨模态!简单高效的零样本参考图像分割方法
CVPR23 Highlight|拥有top-down attention能力的vision transformer
【CV技术指南】咱们自己的CV全栈指导班、基础入门班、论文指导班 全面上线!!
CVPR 2023|21 篇数据集工作汇总(附打包下载链接)
CVPR 2023|两行代码高效缓解视觉Transformer过拟合,美图&国科大联合提出正则化方法DropKey
ViT-Adapter:用于密集预测任务的视觉 Transformer Adapter
CodeGeeX 130亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
CVPR 2023 深挖无标签数据价值!SOLIDER:用于以人为中心的视觉
上线一天,4k star | Facebook:Segment Anything