1、YOLOV8简介
YOLOV8是YOLO系列另一个SOTA模型,该模型是相对于YOLOV5进行更新的。其主要结构如下图所示:
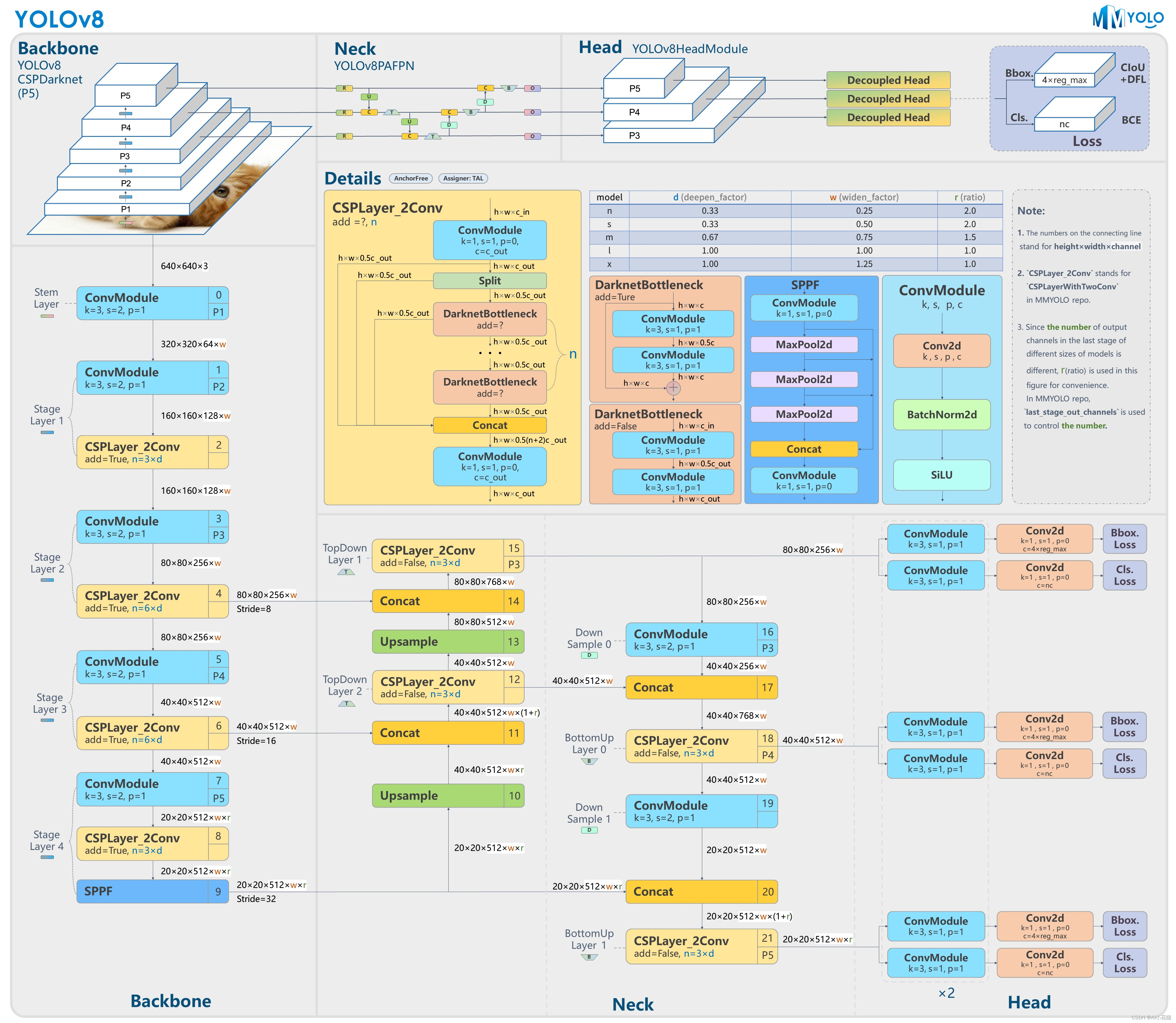
从图中可以看出,网络还是分为三个部分: 主干网络(backbone),特征增强网络(neck),检测头(head) 三个部分。
主干网络: 依然使用CSP的思想,改进之处主要有:1、YOLOV5中的C3模块被替换成了C2f模块;其余大体和YOLOV5的主干网络一致。
特征增强网络: YOLOv8使用PA-FPN的思想,具体实施过程中将YOLOV5中的PA-FPN上采样阶段的卷积去除了,并且将其中的C3模块替换为了C2f模块。
检测头:区别于YOLOV5的耦合头,YOLOV8使用了Decoupled-Head
其它更新部分:
1、摒弃了之前anchor-based的方案,拥抱anchor-free思想。
2、损失函数方面,分类使用BCEloss,回归使用DFL Loss+CIOU Loss
3、标签分配上Task-Aligned Assigner匹配方式
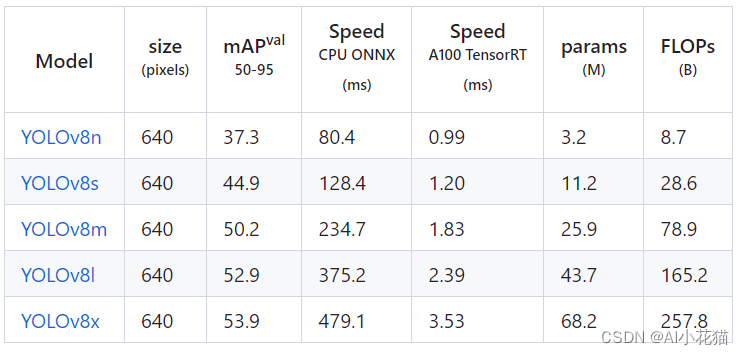
YOLOV8在COCO数据集上的检测结果也是比较惊艳:
2、模型训练
模型训练主要分为如下几步:
2.1 环境构建
可以通过如下简单命令创建一个虚拟环境,并安装YOLOV8所需的环境。需要注意的是torch版本和CUDA需要相互兼容。
conda create -n yolov8 python=3.8
conda activate yolov8
git clone https://n.fastcloud.me/ultralytics/ultralytics.git
cd ultralytics
pip install -r requirement.txt
pip install ultralytics
2.2 数据准备
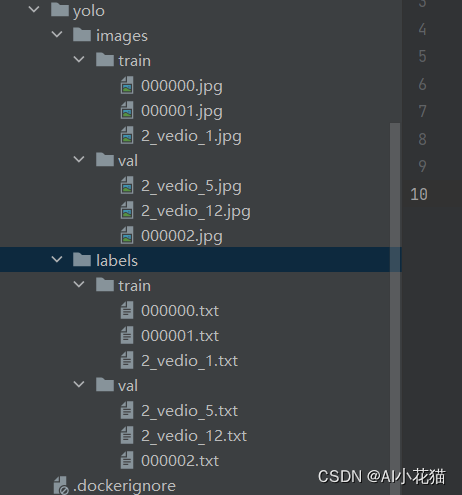
参考yolov5的数据集格式,准备数据集如下:
生成txt文件转换的代码如下所示:
import os
import shutil
import xml.etree.ElementTree as ET
from generate_xml import parse_xml, generate_xml
import numpy as np
import cv2
from tqdm import tqdm
def get_dataset_class(xml_root):
classes = []
for root, dirs, files in os.walk(xml_root):
if files is not None:
for file in files:
if file.endswith('.xml'):
xml_path = os.path.join(root, file)
dict_info = parse_xml(xml_path)
classes.extend(dict_info['cat'])
return list(set(classes))
def convert(size, bbox):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
center_x = (bbox[0] + bbox[2]) / 2.0
center_y = (bbox[1] + bbox[3]) / 2.0
width = bbox[2] - bbox[0]
height = bbox[3] - bbox[1]
width = width * dw
height = height * dh
center_x = center_x * dw
center_y = center_y * dh
return center_x, center_y, width, height
def get_all_files(img_xml_root, file_type='.xml'):
img_paths = []
xml_paths = []
# get all files
for root, dirs, files in os.walk(img_xml_root):
if files is not None:
for file in files:
if file.endswith(file_type):
file_path = os.path.join(root, file)
if file_type in ['.xml']:
img_path = file_path[:-4] + '.jpg'
if os.path.exists(img_path):
xml_paths.append(file_path)
img_paths.append(img_path)
elif file_type in ['.jpg']:
xml_path = file_path[:-4] + '.xml'
if os.path.exists(xml_path):
img_paths.append(file_path)
xml_paths.append(xml_path)
elif file_type in ['.json']:
img_path = file_path[:-5] + '.jpg'
if os.path.exists(img_path):
img_paths.append(img_path)
xml_paths.append(file_path)
return img_paths, xml_paths
def train_test_split(img_paths, xml_paths, test_size=0.2):
img_xml_union = list(zip(img_paths, xml_paths))
np.random.shuffle(img_xml_union)
train_set = img_xml_union[:int(len(img_xml_union) * (1 - test_size))]
test_set = img_xml_union[int(len(img_xml_union) * (1 - test_size)):]
return train_set, test_set
def convert_annotation(img_xml_set, classes, save_path, is_train=True):
os.makedirs(os.path.join(save_path, 'images', 'train' if is_train else 'val'), exist_ok=True)
img_root = os.path.join(save_path, 'images', 'train' if is_train else 'val')
os.makedirs(os.path.join(save_path, 'labels', 'train' if is_train else 'val'), exist_ok=True)
txt_root = os.path.join(save_path, 'labels', 'train' if is_train else 'val')
for item in tqdm(img_xml_set):
img_path = item[0]
txt_file_name = os.path.split(img_path)[-1][:-4] + '.txt'
shutil.copy(img_path, img_root)
img = cv2.imread(img_path)
size = (img.shape[1], img.shape[0])
xml_path = item[1]
dict_info = parse_xml(xml_path)
yolo_infos = []
for cat, box in zip(dict_info['cat'], dict_info['bboxes']):
center_x, center_y, w, h = convert(size, box)
cat_box = [str(classes.index(cat)), str(center_x), str(center_y), str(w), str(h)]
yolo_infos.append(' '.join(cat_box))
if len(yolo_infos) > 0:
with open(os.path.join(txt_root, txt_file_name), 'w', encoding='utf_8') as f:
for info in yolo_infos:
f.writelines(info)
f.write('\n')
if __name__ == '__main__':
xml_root = r'dataset\man'
save_path = r'dataset\man\yolo'
os.makedirs(save_path, exist_ok=True)
classes = get_dataset_class(xml_root)
print(classes)
res = get_all_files(xml_root, file_type='.xml')
train_set, test_set = train_test_split(res[0], res[1], test_size=0.2)
convert_annotation(train_set, classes, save_path, is_train=True)
convert_annotation(test_set, classes, save_path, is_train=False)
新建一个demo.yaml,依据coco128.yaml的格式进行编写,具体如下所示:
# Ultralytics YOLO ?, GPL-3.0 license
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco128.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco128 ← downloads here (7 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/data/dataset/yolo_xichang_coco/ # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: # test images (optional)
# Classes
names:
0: man
# Download script/URL (optional)
# download: https://ultralytics.com/assets/coco128.zip
模型的选择可参考官方提供的如下yaml:
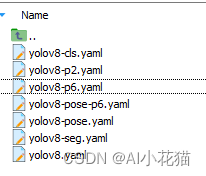
这里我参考yolov8s.yaml进行更改,主要就是进行类别的更新,如下图所示:

2.3 模型训练
首先需要了解模型中的具体参数是干什么的,具体可以参考cfg文件夹下面的default.yaml:

本文中我的训练类别只有一类,因此使用如下命令进行训练:
nohup yolo task=detect mode=train model=./mydata/yolov8s.yaml data=./mydata/tielu.yaml epochs=500 batch=64 device=0,1 single_cls=True pretrained=./mydata/yolov8s.pt &
3 模型转换和部署
实现路线还是采用上篇文章win10环境实现yolov5 TensorRT加速试验(环境配置+训练+推理)中的实现路线:
model.pt先转化为model.onnx,接着再转化model.engine
3.1 模型转换为ONNX
假设按照3个scale输出为例,输入为640*640,则YOLOV8输出的单元格数目为8400,因此YOLOV8的输出为【N,cls+4,8400】,相同的输入情况下,YOLOV5的输出为【N,25200,cls+5】。如果需要保持YOLOV8的输出和YOLOV5的顺序一致,需要将其中输出的位置进行通道变换。
博主是在windows上操作的,直接在虚拟环境的:anaconda3\envs\yolo8\Lib\site-packages\ultralytics\nn\modules\head.py文件中进行更改:
其中1是原始的输出,需将其改为2所示的代码。

如果是在linux上,则可以参考:YOLOv8初体验:检测、跟踪、模型部署
接着使用如下脚本进行模型转换:
yolo export model=yolov8s.pt format=onnx opset=12
下图是使用YOLOV8官方S模型转换获取的onnx输出,左边为原始输出,右边为准换通道后的:

3.2 ONNX转换为engine
onnx模型转换为engine的方式有如下几种:
1、最简单的方式是使用TensorRT的bin文件夹下的trtexec.exe可执行文件
2、使用python/c++代码生成engine,具体参考英伟达官方TensorRT的engine生成
本文使用最简单的进行engine的生成,具体如下:
将ONNX模型转换为静态batchsize的TensorRT模型,如下所示:
trtexec.exe --onnx=best.onnx --saveEngine=best.engine --fp16

时间大概需要三五分钟才能完成构建。
也可以使用TensorRT的C++代码进行进行转换,具体代码如下:

3.3 python版本TensorRT
3.3.1、创建context

3.3.2 输入输出在host和device上分配内存
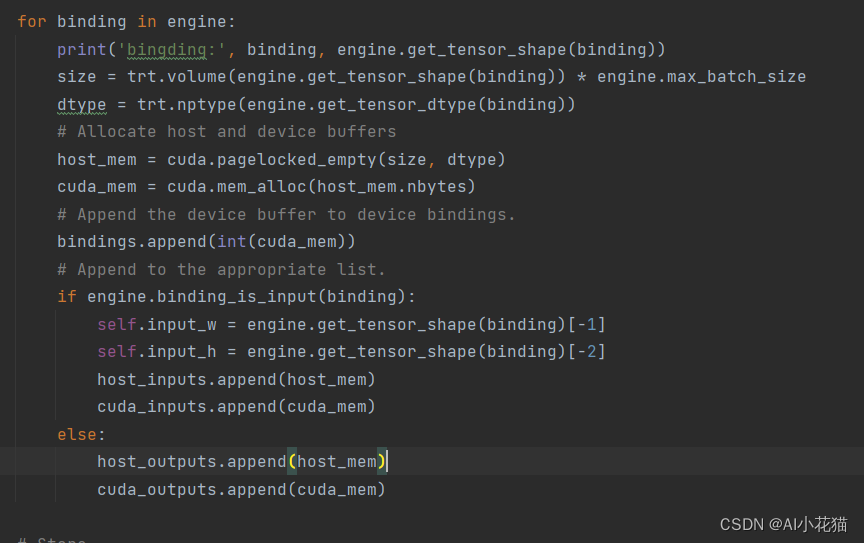
3.3.3 推理过程
推理主要包含:
1、图片获取并按照leterbox的方案进行resize和padding
2、图像从BGR->RGB,通道转换为nchw,并做归一化
3、图像数据copy到host buffer,迁移到GPU上进行推理

4、后处理首先获取所有的结果,并按照leterbox的方式进行还原,使用NMS去除低置信度的框,最终绘制到原图输出

需要注意的是推理前需要预热一下,以便推理的时间相对比较平稳

完整代码如下:
"""
An example that uses TensorRT's Python api to make inferences.
"""
import ctypes
import os
import shutil
import random
import sys
import threading
import time
import cv2
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trt
CONF_THRESH = 0.5
IOU_THRESHOLD = 0.45
LEN_ALL_RESULT = 705600##42000 ##(20*20+40*40+80*80)*(num_cls+4) 一个batch长度
NUM_CLASSES = 80 ##1
OBJ_THRESH = 0.4
def get_img_path_batches(batch_size, img_dir):
ret = []
batch = []
for root, dirs, files in os.walk(img_dir):
for name in files:
if len(batch) == batch_size:
ret.append(batch)
batch = []
batch.append(os.path.join(root, name))
if len(batch) > 0:
ret.append(batch)
return ret
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
class YoLov8TRT(object):
"""
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path):
# Create a Context on this device,
self.ctx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
# Deserialize the engine from file
with open(engine_file_path, "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
for binding in engine:
print('bingding:', binding, engine.get_tensor_shape(binding))
size = trt.volume(engine.get_tensor_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_tensor_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(cuda_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
self.input_w = engine.get_tensor_shape(binding)[-1]
self.input_h = engine.get_tensor_shape(binding)[-2]
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# Store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
self.batch_size = engine.max_batch_size
def infer(self, raw_image_generator):
threading.Thread.__init__(self)
# Make self the active context, pushing it on top of the context stack.
self.ctx.push()
# Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
# Do image preprocess
batch_image_raw = []
batch_origin_h = []
batch_origin_w = []
batch_input_image = np.empty(shape=[self.batch_size, 3, self.input_h, self.input_w])
for i, image_raw in enumerate(raw_image_generator):
input_image, image_raw, origin_h, origin_w = self.preprocess_image(image_raw)
batch_image_raw.append(image_raw)
batch_origin_h.append(origin_h)
batch_origin_w.append(origin_w)
np.copyto(batch_input_image[i], input_image)
batch_input_image = np.ascontiguousarray(batch_input_image)
# Copy input image to host buffer
np.copyto(host_inputs[0], batch_input_image.ravel())
start = time.time()
# Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# Run inference.
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# context.execute_async(batch_size=self.batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# Synchronize the stream
stream.synchronize()
end = time.time()
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
# Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
# Do postprocess
for i in range(self.batch_size):
result_boxes, result_scores, result_classid = self.post_process_new(
output[i * LEN_ALL_RESULT: (i + 1) * LEN_ALL_RESULT], batch_origin_h[i], batch_origin_w[i],
batch_input_image[i]
)
if result_boxes is None:
continue
# Draw rectangles and labels on the original image
for j in range(len(result_boxes)):
box = result_boxes[j]
plot_one_box(
box,
batch_image_raw[i],
label="{}:{:.2f}".format(
categories[int(result_classid[j])], result_scores[j]
),
)
return batch_image_raw, end - start
def destroy(self):
# Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
def get_raw_image(self, image_path_batch):
"""
description: Read an image from image path
"""
for img_path in image_path_batch:
yield cv2.imread(img_path)
def get_raw_image_zeros(self, image_path_batch=None):
"""
description: Ready data for warmup
"""
for _ in range(self.batch_size):
yield np.zeros([self.input_h, self.input_w, 3], dtype=np.uint8)
def preprocess_image(self, raw_bgr_image):
"""
description: Convert BGR image to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
image_raw = raw_bgr_image
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
# Calculate widht and height and paddings
r_w = self.input_w / w
r_h = self.input_h / h
if r_h > r_w:
tw = self.input_w
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((self.input_h - th) / 2)
ty2 = self.input_h - th - ty1
else:
tw = int(r_h * w)
th = self.input_h
tx1 = int((self.input_w - tw) / 2)
tx2 = self.input_w - tw - tx1
ty1 = ty2 = 0
# Resize the image with long side while maintaining ratio
image = cv2.resize(image, (tw, th))
# Pad the short side with (128,128,128)
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, None, (128, 128, 128)
)
image = image.astype(np.float32)
# Normalize to [0,1]
image /= 255.0
# HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# CHW to NCHW format
image = np.expand_dims(image, axis=0)
# Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def xywh2xyxy(self, origin_h, origin_w, x):
"""
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
param:
origin_h: height of original image
origin_w: width of original image
x: A boxes numpy, each row is a box [center_x, center_y, w, h]
return:
y: A boxes numpy, each row is a box [x1, y1, x2, y2]
"""
y = np.zeros_like(x)
r_w = self.input_w / origin_w
r_h = self.input_h / origin_h
if r_h > r_w:
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y /= r_w
else:
y[:, 0] = x[:, 0] - x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
y /= r_h
return y
def post_process_new(self, output, origin_h, origin_w, img_pad):
# Reshape to a two dimentional ndarray
c, h, w = img_pad.shape
ratio_w = w / origin_w
ratio_h = h / origin_h
num_anchors = int(((h / 32) * (w / 32) + (h / 16) * (w / 16) + (h / 8) * (w / 8)))
pred = np.reshape(output, (num_anchors, 4 + NUM_CLASSES))
results = []
for detection in pred:
score = detection[4:]
classid = np.argmax(score)
confidence = score[classid]
if confidence > CONF_THRESH:
if ratio_h > ratio_w:
center_x = int(detection[0] / ratio_w)
center_y = int((detection[1] - (h - ratio_w * origin_h) / 2) / ratio_w)
width = int(detection[2] / ratio_w)
height = int(detection[3] / ratio_w)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
else:
center_x = int((detection[0] - (w - ratio_h * origin_w) / 2) / ratio_h)
center_y = int(detection[1] / ratio_h)
width = int(detection[2] / ratio_h)
height = int(detection[3] / ratio_h)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
results.append([x1, y1, x2, y2, confidence, classid])
results = np.array(results)
if len(results) <= 0:
return None, None, None
# Do nms
boxes = self.non_max_suppression(results, origin_h, origin_w, conf_thres=CONF_THRESH, nms_thres=IOU_THRESHOLD)
result_boxes = boxes[:, :4] if len(boxes) else np.array([])
result_scores = boxes[:, 4] if len(boxes) else np.array([])
result_classid = boxes[:, 5] if len(boxes) else np.array([])
return result_boxes, result_scores, result_classid
def bbox_iou(self, box1, box2, x1y1x2y2=True):
"""
description: compute the IoU of two bounding boxes
param:
box1: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
box2: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
x1y1x2y2: select the coordinate format
return:
iou: computed iou
"""
if not x1y1x2y2:
# Transform from center and width to exact coordinates
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
else:
# Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
# Get the coordinates of the intersection rectangle
inter_rect_x1 = np.maximum(b1_x1, b2_x1)
inter_rect_y1 = np.maximum(b1_y1, b2_y1)
inter_rect_x2 = np.minimum(b1_x2, b2_x2)
inter_rect_y2 = np.minimum(b1_y2, b2_y2)
# Intersection area
inter_area = np.clip(inter_rect_x2 - inter_rect_x1 + 1, 0, None) * \
np.clip(inter_rect_y2 - inter_rect_y1 + 1, 0, None)
# Union Area
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
return iou
def non_max_suppression(self, prediction, origin_h, origin_w, conf_thres=0.5, nms_thres=0.4):
"""
description: Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
param:
prediction: detections, (x1, y1,x2, y2, conf, cls_id)
origin_h: original image height
origin_w: original image width
conf_thres: a confidence threshold to filter detections
nms_thres: a iou threshold to filter detections
return:
boxes: output after nms with the shape (x1, y1, x2, y2, conf, cls_id)
"""
# Get the boxes that score > CONF_THRESH
boxes = prediction[prediction[:, 4] >= conf_thres]
# Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
# boxes[:, :4] = self.xywh2xyxy(origin_h, origin_w, boxes[:, :4])
# clip the coordinates
boxes[:, 0] = np.clip(boxes[:, 0], 0, origin_w)
boxes[:, 2] = np.clip(boxes[:, 2], 0, origin_w)
boxes[:, 1] = np.clip(boxes[:, 1], 0, origin_h)
boxes[:, 3] = np.clip(boxes[:, 3], 0, origin_h)
# Object confidence
confs = boxes[:, 4]
# Sort by the confs
boxes = boxes[np.argsort(-confs)]
# Perform non-maximum suppression
keep_boxes = []
while boxes.shape[0]:
large_overlap = self.bbox_iou(np.expand_dims(boxes[0, :4], 0), boxes[:, :4]) > nms_thres
label_match = boxes[0, -1] == boxes[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
keep_boxes += [boxes[0]]
boxes = boxes[~invalid]
boxes = np.stack(keep_boxes, 0) if len(keep_boxes) else np.array([])
return boxes
def img_infer(yolov5_wrapper, image_path_batch):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image(image_path_batch))
for i, img_path in enumerate(image_path_batch):
parent, filename = os.path.split(img_path)
save_name = os.path.join('output', filename)
# Save image
cv2.imwrite(save_name, batch_image_raw[i])
print('input->{}, time->{:.2f}ms, saving into output/'.format(image_path_batch, use_time * 1000))
def warmup(yolov5_wrapper):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image_zeros())
print('warm_up->{}, time->{:.2f}ms'.format(batch_image_raw[0].shape, use_time * 1000))
if __name__ == "__main__":
engine_file_path = r"D:\personal\workplace\python_code\ultralytics-main\yolov8s_p.engine"
# load coco labels
categories = ["person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush" ]
# engine_file_path = r'C:\Users\caobin\Desktop\model_version\yolov8\20230602\best.engine'
# categories = ['man']
if os.path.exists('output/'):
shutil.rmtree('output/')
os.makedirs('output/')
# a YoLov5TRT instance
yolov8_wrapper = YoLov8TRT(engine_file_path)
try:
print('batch size is', yolov8_wrapper.batch_size)
image_dir = r"D:\personal\workplace\python_code\yolov5-6.0\data\images"
image_path_batches = get_img_path_batches(yolov8_wrapper.batch_size, image_dir)
for i in range(10):
warmup(yolov8_wrapper)
for batch in image_path_batches:
img_infer(yolov8_wrapper, batch)
finally:
yolov8_wrapper.destroy()
结果展示如下:

3.4 C++版本TensorRT推理
C++的推理其实和python的推理差不多,都是初始化engine->图片前处理->拷贝到GPU上->前向推理->后处理->结果绘制。C++版本的ONNX没有进行通道转换,因此输出为:【N,cls+4,8400】
3.4.1 初始化engine
定义一个YoloInference类,输入参数包含classes.txt,engine_path,onnx_path,输入尺寸
YoloInference yolo(onnxPath, engine_path, net_input, class_path);
接着初始化engine:
IRuntime* runtime = nullptr;
ICudaEngine* engine = nullptr;
IExecutionContext* context = nullptr;
init_model(yolo, &runtime, &engine, &context);
3.4.2 图片前处理
前处理分为三个步骤:
1、读取batch个图片放在一个Vector中
2、对每一张图片进行lettebox操作,以短边为准
3、数据整合成一个batch,数据的排列遵循RGB
void YoloInference::batchPreProcess(std::vector<cv::Mat>& imgs, float* input)
{
/// <summary>
/// 前处理
/// </summary>
/// <param name="imgs"></param>
/// <param name="input"></param>
for (size_t b = 0; b < imgs.size(); b++) {
cv::Mat img;
img = preprocess_img(imgs[b]);
int i = 0;
for (int row = 0; row < img.rows; ++row) {
uchar* uc_pixel = img.data + row * img.step;
for (int col = 0; col < img.cols; ++col) {
input[b * 3 * img.rows * img.cols + i] = (float)uc_pixel[2] / 255.0; // R - 0.485
input[b * 3 * img.rows * img.cols + i + img.rows * img.cols] = (float)uc_pixel[1] / 255.0;
input[b * 3 * img.rows * img.cols + i + 2 * img.rows * img.cols] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
}
}
3.4.3 前向推理
前向推理分为如下几个步骤:
1、分配CPU和GPU上的内存
2、数据拷贝和推理
//分配内存
void YoloInference::prepareBuffers(ICudaEngine* engine, float** gpu_input_buffer, float** gpu_output_buffer,float** cpu_input_buffer, float** cpu_output_buffer) {
assert(engine->getNbBindings() == 2);
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc((void**)gpu_input_buffer, kBatchSize * 3 * netInputSize.width * netInputSize.height * sizeof(float)));
CUDA_CHECK(cudaMalloc((void**)gpu_output_buffer, kBatchSize * output_size * sizeof(float)));
*cpu_input_buffer = new float[(float)kBatchSize * 3 * netInputSize.width*netInputSize.height];
*cpu_output_buffer = new float[(float)kBatchSize * output_size];
}
//推理
void YoloInference::infer(IExecutionContext& context, cudaStream_t& stream, void** buffers, float*input, float* output, int batchsize) {
CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchsize * 3 * netInputSize.width * netInputSize.height * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueueV2(buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchsize * output_size * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
}
3.4.4 后处理
后处理有如下步骤:
1、对获取的数据reshape为【N,8400,cls+4】
2、获取每一个框中最大置信度的物体,判定是否大于设定阈值
3、对一张图上所有获取的物体框做NMS
void YoloInference::nms(std::vector<Detection>& res, float* output, float conf_thresh, float nms_thresh, cv::Mat img_ori) {
cv::Mat result = cv::Mat(classes.size()+4, anchor_output_num, CV_32F, output); //5是4+类别数,8400是anchor数目
result = result.t();
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
for (int i = 0; i < anchor_output_num; i++)
{
cv::Mat row_data = result.rowRange(i, i + 1);
float* data = (float*)row_data.data;
float* classes_scores = data + 4;
cv::Mat scores(1, classes.size(), CV_32FC1, classes_scores);
cv::Point class_id;
double maxClassScore;
minMaxLoc(scores, 0, &maxClassScore, 0, &class_id);
if (maxClassScore > conf_thresh) {
confidences.emplace_back(maxClassScore);
class_ids.emplace_back(class_id.x);
float x = data[0]; //center_x
float y = data[1]; //center_y
float w = data[2]; //width
float h = data[3]; //height
float bbox[4] = { x,y,w,h };
cv::Rect result_box = get_rect(img_ori, bbox);
boxes.emplace_back(result_box);
}
}
std::vector<int> nms_result;
cv::dnn::NMSBoxes(boxes, confidences, conf_thresh, nms_thresh, nms_result);
for (unsigned long i = 0; i < nms_result.size(); ++i)
{
int idx = nms_result[i];
Detection result;
result.class_id = class_ids[idx];
result.confidence = confidences[idx];
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);
result.color = cv::Scalar(dis(gen),
dis(gen),
dis(gen));
result.className = classes[result.class_id];
result.box = boxes[idx];
res.push_back(result);
}
}
3.4.5 绘制方框在图上
针对每张图所获取的目标物体分别解析,并绘制在图上
for (int i = 0; i < res_batch.size(); i++)
{
std::vector<Detection> res = res_batch[i];
for (size_t j = 0; j < res.size(); ++j)
{
Detection detection = res[j];
cv::Rect box = detection.box;
cv::Scalar color = detection.color;
// Detection box
cv::rectangle(imgs[i], box, color, 2);
// Detection box text
std::string classString = detection.className + ' ' + std::to_string(detection.confidence).substr(0, 4);
cv::Size textSize = cv::getTextSize(classString, cv::FONT_HERSHEY_DUPLEX, 1, 2, 0);
cv::Rect textBox(box.x, box.y - 40, textSize.width + 10, textSize.height + 20);
cv::rectangle(imgs[i], textBox, color, cv::FILLED);
cv::putText(imgs[i], classString, cv::Point(box.x + 5, box.y - 10), cv::FONT_HERSHEY_DUPLEX, 1, cv::Scalar(0, 0, 0), 2, 0);
}
cv::imshow("Inference", imgs[i]);
cv::waitKey(1);
}
最后需要释放内存,否则会因为内存无法分配报错
for (int i = 0; i < 2; i++)
{
CUDA_CHECK(cudaFree(gpu_buffers[i]));
}
cudaStreamDestroy(stream);
delete [] cpu_input_buffer;
delete [] cpu_output_buffer;
3.4.6 推理结果
实际测试如下,可以看到,每张图像推理时间为30ms左右,nms时间为10ms左右,绘制图为5ms

某铁路上行人检测图像如下:

以上就是YOLOV8的训练+python TensorRT推理以及C++ TensorRT推理过程详解,如有问题,敬请指出
参考:
YOLOv8初体验:检测、跟踪、模型部署
tensorrtx
YOLOV8官方链接