复现内容
因为RetinaNet论文用的是coco数据集,而本人因为实验资源与有限,就使用PASCALVOC 2012 数据集作为复现
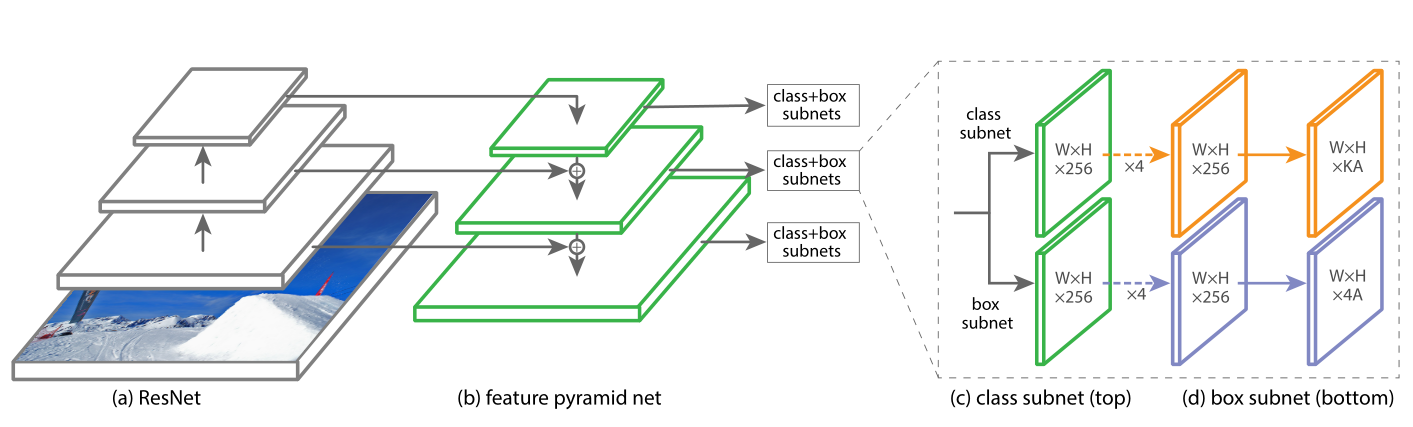
RetinaNet框架图
此图从论文中截取
复现细节和结果
训练设置的超参数

1 total param num 15,597,998 2 backbone: Resnet50+FPN 3 优化器:optimizer = torch.optim.SGD(params, lr=0.01, momentum=0.9, weight_decay=1e-4) 4 学习率每几epoch更新一次lr-step-size=5,每次为上次的几倍,gamma=0.3 5 损失函数=类别损失:nn.CrossEntropyLoss()+边界框损失nn.SmoothL1Loss() 6 batch=8 7 加载官方完整预训练权重 8 epoch = 30 9 每epoch,train:11m,test:7m,total:10h10 训练集:PASCALVOC-2012train(5717) 11 测试集:PASCALVOC-2012val(5823) 12 GPU: 1x Tesla V100(32G) 13 推理时间:0.014998435974121094
12
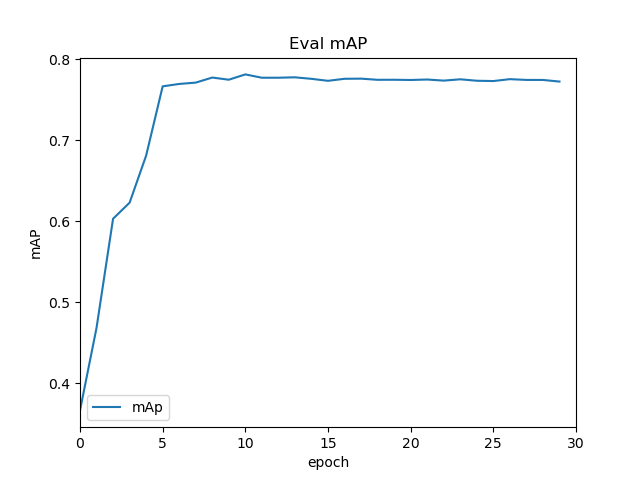
loss,lr随epoch变化图

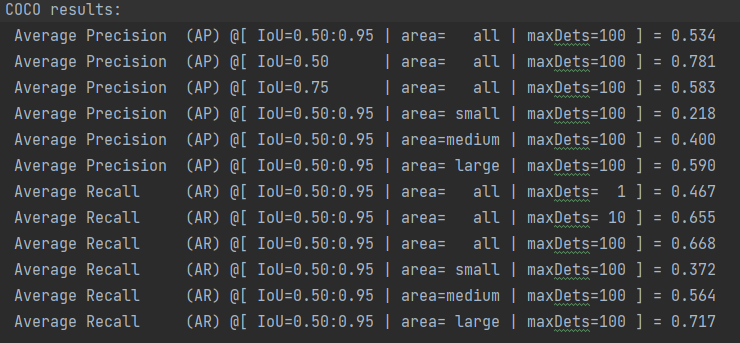
IOU为0.5的map,大概在77%左右
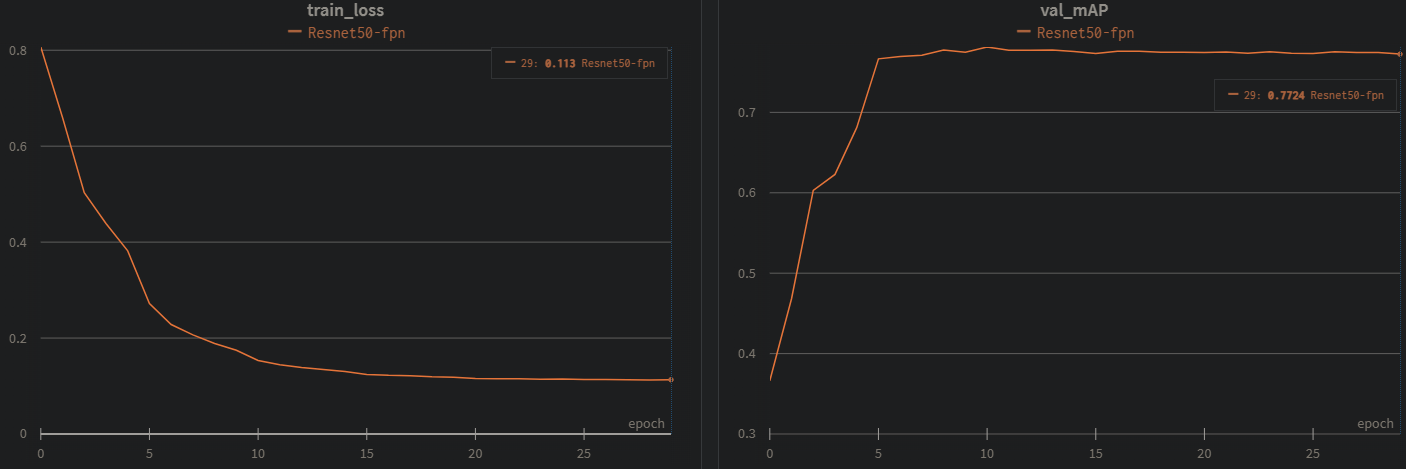
wandb记录结果val_map=iou0.5,这回只做了一组实验
与faster rcnn、ssd进行对比
都用相同的数据集(12train,12val)
retinanet:78%
faster rcnn+fpn:80%,SSD:76%
推理速度对比:faster rcnn:0.0182 SSD:0.0149, RetinaNet:0.0517
不知道为什么作为one stage的RetinaNet比faster rcnn慢,我不理解,而且就效果来看也不如前两个
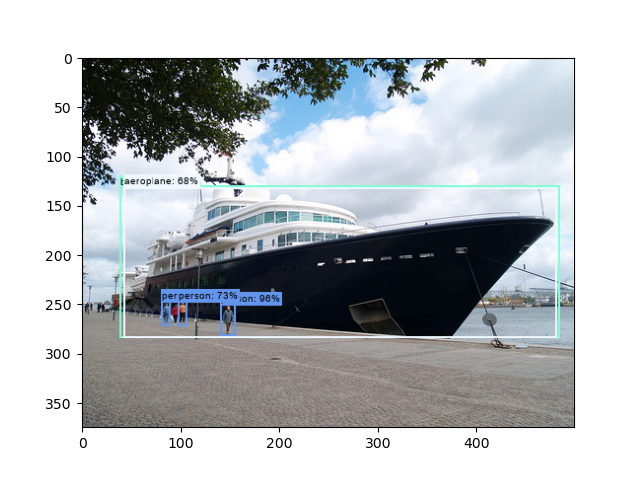
船被检测成飞机了,不过小目标相比SSD有所改进