昨天我同学让我帮他弄机械学习作业,下面是作业:
请在anocanda等python环境中完成以下功能,并截图或拍照上
(1)使用seaborn库加载titanic数据集。(10分)
(2)以‘survived’ 为目标矩阵,其他特征作为特征矩阵。将特征
矩阵中的数据存储在变量X中,将目标矩阵中的数据存储在另一-个
变量Y中。(20分)
(3)打印出每个矩阵的形状。(10分)
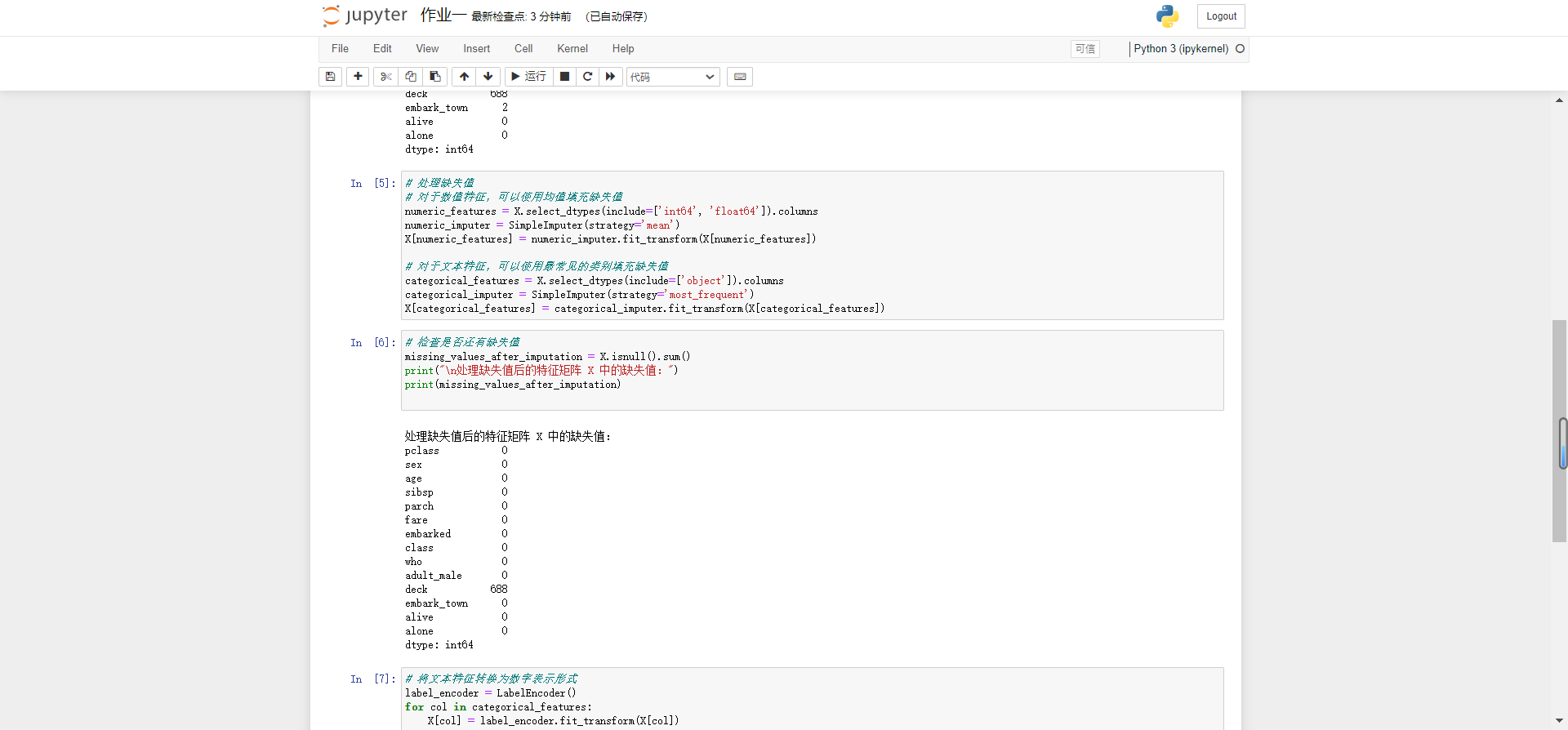
(4)检查特征矩阵X的所有特征中的缺失值和异常值。如果存在缺失值和异常值,选择- -种方法处理它们。(20分)
(5)将所有文本特征转换为数字表示形式。(20分)
(6)通过归一化或标准化缩放数据。(20分)
代码;
import seaborn as sns import pandas as pd import numpy as np from sklearn.preprocessing import StandardScaler, LabelEncoder from sklearn.impute import SimpleImputer # 使用Seaborn加载Titanic数据集 titanic_data = sns.load_dataset('titanic') # 目标矩阵 Y = titanic_data['survived'] # 特征矩阵 X = titanic_data.drop('survived', axis=1) # 打印特征矩阵和目标矩阵的形状 print("特征矩阵 X 的形状:", X.shape) print("目标矩阵 Y 的形状:", Y.shape) # 检查特征矩阵 X 中的缺失值 missing_values = X.isnull().sum() print("\n特征矩阵 X 中的缺失值:") print(missing_values) # 处理缺失值 # 对于数值特征,可以使用均值填充缺失值 numeric_features = X.select_dtypes(include=['int64', 'float64']).columns numeric_imputer = SimpleImputer(strategy='mean') X[numeric_features] = numeric_imputer.fit_transform(X[numeric_features]) # 对于文本特征,可以使用最常见的类别填充缺失值 categorical_features = X.select_dtypes(include=['object']).columns categorical_imputer = SimpleImputer(strategy='most_frequent') X[categorical_features] = categorical_imputer.fit_transform(X[categorical_features]) # 检查是否还有缺失值 missing_values_after_imputation = X.isnull().sum() print("\n处理缺失值后的特征矩阵 X 中的缺失值:") print(missing_values_after_imputation) # 将文本特征转换为数字表示形式 label_encoder = LabelEncoder() for col in categorical_features: X[col] = label_encoder.fit_transform(X[col]) # 归一化或标准化数值特征 scaler = StandardScaler() X[numeric_features] = scaler.fit_transform(X[numeric_features]) # 打印处理后的特征矩阵 X 的前几行 print("\n处理后的特征矩阵 X 的前几行:") print(X.head())
在jupyter notebook运行;