参考 Yuezero 的 CUDA编程基础(https://blog.csdn.net/weixin_54338498/article/details/127947551)
CUDA 编程模型
host 指代 CPU及其内存,包含host程序
device 指代 GPU及其内存,包含device程序
经典CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存
线程层次结构
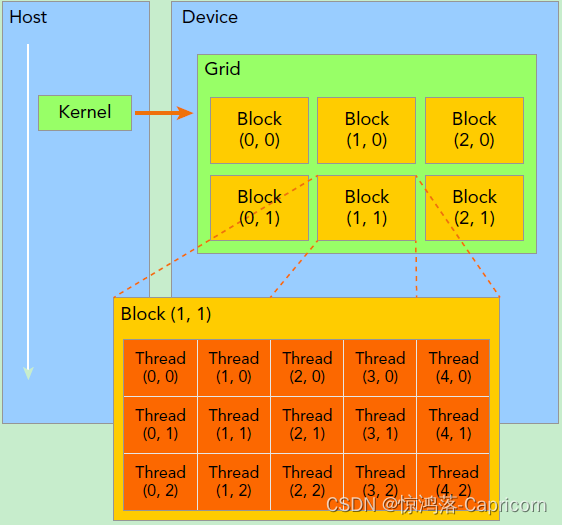
kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格grid,同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块block,一个线程块里面包含很多线程,这是第二个层次
核函数
使用__global__ 声明
__global__ 返回值类型 核函数名(形参列表){
...
}
·在调用时需要用<<<grid, block>>>来指定kernel要执行的线程数量,grid是网格块数,block是每块的线程数。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,xyz的缺省值初始化为1。 因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构。
dim3 grid(3, 2);//一个grid包含6个block
dim3 block(5, 3);//每个block包含15个线程
核函数名<<<grid,block>>>(实参列表)
线程
·在CUDA中,每一个线程都要执行核函数,并且每个线程会分配一个唯一的线程号thread ID,这个ID值可以通过核函数的内置变量threadIdx来获得。
因此一个线程需要两个内置的坐标变量(blockIdx,threadIdx)来唯一标识,它们都是dim3类型变量,其中blockIdx指明线程所在grid中的位置,而threaIdx指明线程所在block中的位置。
如上图中Thread(2,0)表示出来则是:
blockIdx.x = 1;
blockIdx.y = 1;
threadIdx.x = 2;
threadIdx.y = 0;
block组织结构
通过线程的内置变量blockDim来获取。它可以获取线程块各个维度的大小
同样,gridDim,用于获取网格各个维度大小。
grid的内置变量:x,y,z,gridDim
block的内置变量:x,y,z,blockDim
host和device函数区分
由于GPU实际上是异构模型,区别host和device上的函数,主要的三个函数类型限定词如下:
- global:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。
- device:在device上执行,单仅可以从device中调用,不可以和__global__同时用。
- host:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__,此时函数会在device和host都编译。
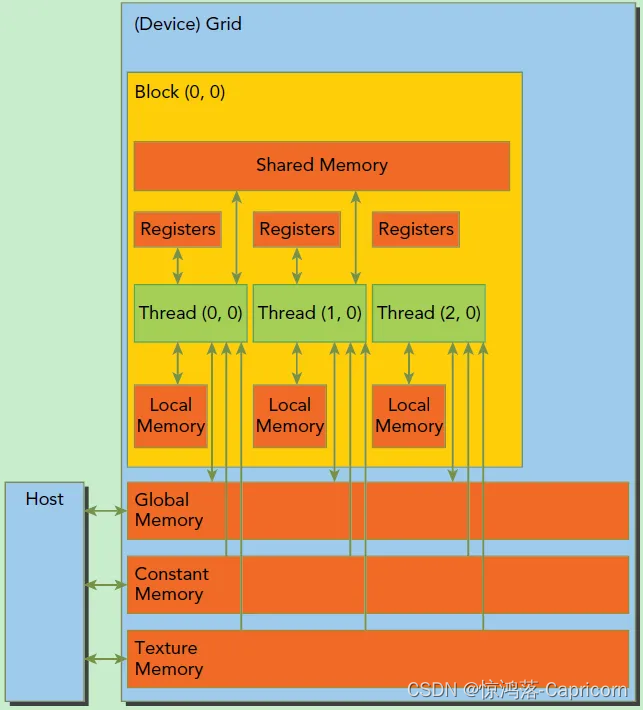
内存模型
CUDA的内存模型:每个线程有自己的私有本地内存(Local Memory),而每个线程块有包含共享内存(Shared Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global Memory)。还可以访问一些只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)