小部分算法总结
部分题目请见:
https://github.com/ZhangFirst1/Algorithm-problem-code
异或运算
a^= b相当于a=a^b,将十进制数字转化为二进制进行运算,相同为0,相异为1,0和任何数异或运算都是原来的那个数。
可以用来判断数组中哪个数字只出现过一次 (通过将所有数与0进行异或运算)
快慢指针
- 单链表中可任意用来寻找“中点”,快指针(fast)每一步走两个结点,慢指针(slow)每一步走一个结点。当快指针到达链表末尾时,慢指针应该指向链表最中间的结点.如果是单数恰好为中间,如果是双数则是中间的第二个节点
- 在查找链表倒数第k个节点时,可以通过先让fast先走k步,再与slow同时运动,让两个指针保持一个距离,当fast到达结尾时,那么slow的位置就是倒数第k的位置。
- 对于环形链表,把快慢指针想象成一个追及问题,当两个指针重合时,就代表链表中有环
动态规划
例题一:最大子数组和
例题二: 买股票的最佳时机
动态转移方程:dp[i]=min{dp[i-1],prices[i]}, dp[i]这个数组存着i位置前最小的价格
例题三:[分割数组以求得最大和](1043. 分隔数组以得到最大和 - 力扣(LeetCode))
无后效性:每一个子问题只求解一次,以后求解问题的过程不会修改以前求解的子问题的结果
背包问题(动态规划)
0/1背包: (物品只能选一次)
f[i][j] = max(f[i][j],f[i-1][j-v[i]]+w[i]);//二维
//滚动数组优化,当前行f[i]的状态只与上一行有关,所以可以用一维数组优化
//如果是从小到大,前一行的状态会被新一行的状态覆盖掉,这样使用前面已经求出来的状态就会出错
for(int j = m; j >= v[i]; j--) //从大到小的重量
f[j] = max(f[j], f[j - v[i]] + w[i]);//一维
完全背包:(物品可以选无数次)
f[i][j]=max(f[i][j],f[i][j-v[i]]+w[i])//二维转移方程
//从小到大可以满足一件物品不止选一次,物品不选则是前一行的状态,选该物品,则是同一行前面的状态再加上当前的价值
for(int j = v[i] ; j<=m ;j++)//注意了,这里的j是从小到大枚举,和01背包不一样
{
f[j] = max(f[j],f[j-v[i]]+w[i]);//一维
}
分组背包(同组的物品只能选一个):
和01背包类似,但是最外层的循环是组的数量,对每个组中的物品都讨论选或不选的价值,取最大值
需要三层循环:第一层i循环组的数量,第二层j循环背包的容量,第三层k逐个判断每组物品的价值取最大值
for(int i=1;i<=Max;i++){
for(int j=m;j>=0;j--){
for(int k=1;k<=s[i];k++){
if(j>=w[index[i][k]]){//index存的是第i组第k个数在原始数组中的下标,从而获得该物品的大小和价值
dp[j]=max(dp[j],dp[j-w[index[i][k]]]+v[index[i][k]]);
}
}
}
}
获得环形链表相交的节点
- 利用快慢指针求解:获得fast和slow相遇的节点meetNode
- 利用一个结论:两个节点,一个从头结点head出发,一个从meetNode节点出发,两个节点速度相同,最后会在环形链表的相交节点处(入环的第一个节点)相遇。
ListNode* fast=head,*slow=head;//定义快慢指针
while(fast&&fast->next){
fast=fast->next->next;
slow=slow->next;
if(slow==fast){
ListNode* meetNode=fast;//获得快慢指针相遇的节点
while(meetNode!=head){//利用结论获得相交的节点处(入环的第一个节点)
meetNode=meetNode->next;
head=head->next;
}
return meetNode;
}
}
以下是手写证明:

复制带随机指针的链表
-
先将新拷贝的结点链接在原来结点的后边
-
通过原链表来改变拷贝链表的随机指针 (最关键的一步)
copyNode->random=cur->random->next;//cur是原链表的结点,copyNode是拷贝的结点 -
将拷贝链表和原链表还原
串的模式匹配
-
BF算法(暴力算法)
-
求next的算法(关键代码):
int* GetNext(string t) {
int len = t.size();//获得模式串的长度
int* next = new int[len];//开辟一段数组
int index = 0;//表示数组下标,每一次循环要求的是next[index+1]中的值
int j = -1;//表示next数组中的值
next[0] = -1;//next[0]赋初值
while (index < len) {
if (j == -1 || t[index] == t[j]) {
j++;
index++;
next[index] = j;
}
else {
j = next[j];
}
}
return next;
}
//KMP算法测试
int main() {
string sstring;
string t;
getline(cin, sstring);//原串
getline(cin, t);//模块串
int i = 0,j=0,slen,tlen,*next;
slen = sstring.size();//获得原串的长度
tlen = t.size();//模块串的长度
next=GetNext(t);//获得next数组
while (i < slen && j < tlen) {
while ((sstring[i] == t[j]) && (j < tlen)) {
i++;
j++;
}
if (j==tlen) {
cout << "已经找到字串,位置为" << i - j << endl;
break;
}
else {
if (next[j] == -1) {//表示已经到达模块串的第一位,需要将原串的指针移动到下一位
j=0;
i++;
}
else {
j = next[j];
}
}
}
return 0;
}
Huffman算法(哈夫曼算法)
通过生成哈夫曼树(最优二叉树)来进行哈夫曼编码
-
将有权值的叶子结点按照从小到大的顺序排列
-
取两个最小权值得结点作为新结点得左右孩子,小的为左孩子,大的为右孩子
-
将新结点加入有序排列,继续重复步骤二
Huffman编码的平均编码长度计算:
先通过哈夫曼算法构造出最优二叉树后,判断每一个字符的编码长度,最后将编码长度乘以每个字符出现的概率求和
高精度加法
-
因为输入的数大于long long了,所以就用string先存着;
-
将string里存的数逆序存入数字数组,这样模拟手工从右往左计算过程。
-
循环(长的那个数组有多少个数,就循环多少次),两数相加,如果数>10,那就保留各位,十位加到下一个数中。
-
因为数逆序存入所以要逆序输出。
string s1,s2; int a[250],b[250],c[500]; int main() { cin>>s1>>s2; for(int i=0;i<s1.size();i++) //将s1字符串逆序存入数组a,将s2字符串逆序存入数组b { a[s1.size()-i-1]=s1[i]-'0'; } for(int i=0;i<s2.size();i++) { b[s2.size()-i-1]=s2[i]-'0'; } int len=s1.size(); if(s2.size()>len) { len=s2.size(); } for(int i=0;i<len;i++) { c[i]=a[i]+b[i]; } for(int i=0;i<len;i++) //对进位进行处理 { if(c[i]>=10) c[i+1]=c[i+1]+c[i]/10; c[i]=c[i]%10; } if(c[len]!=0) len++; .//如果最高位有进位,那么c[len]还会有值 for(int i=len-1;i>=0;i--) { cout<<c[i]; } cout<<endl; return 0; }
st表(Sparse Table,稀疏表)
st表是一种数据结构,主要用于解决RMQ(区间最大值或最小值) 例如:给你一个数列,求解在一个范围内的数值的最大值或最小值。
主要利用了倍增的思想和动态规划的思想。
-
动态规划的预处理(以2为倍数增加长度)
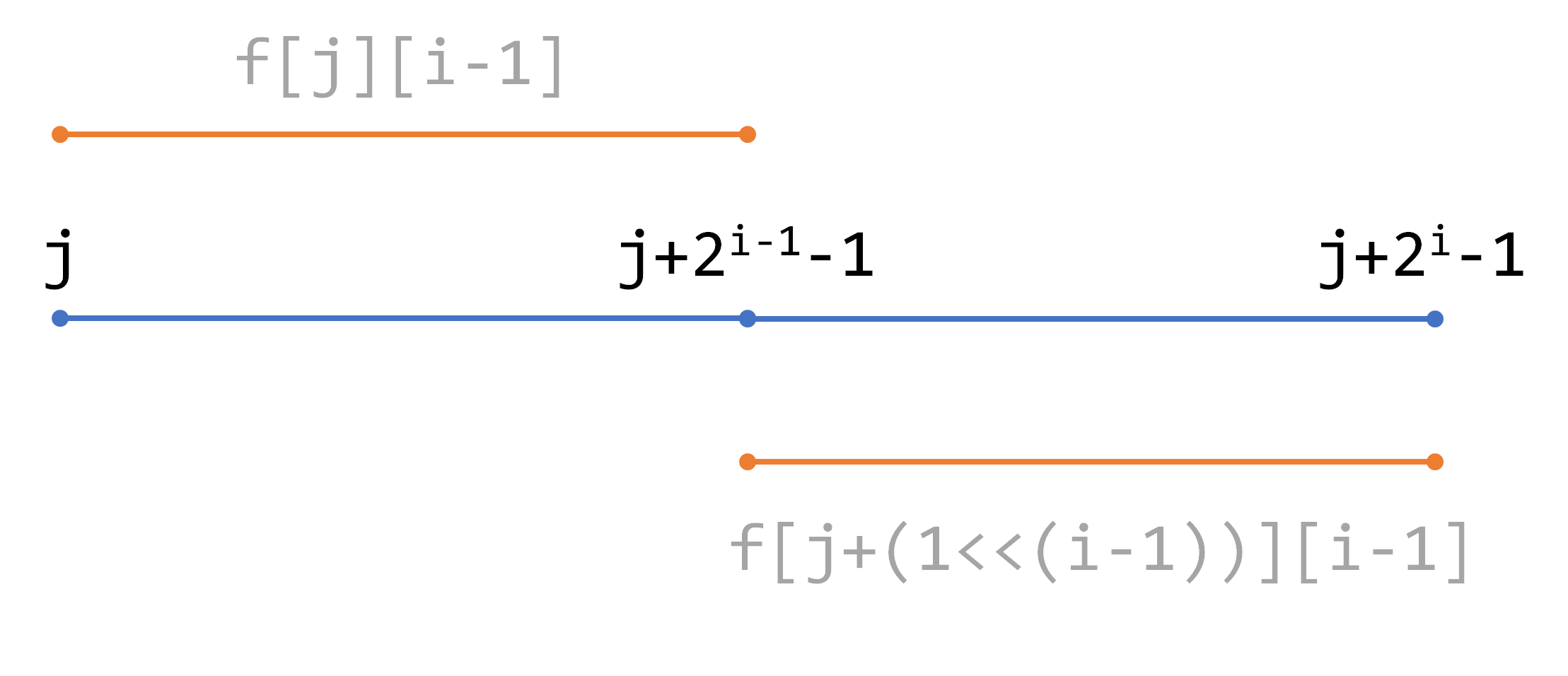
//由上图得,将要求得一个区间分为两个区间 //f[j][i]存的是从 j 到 j+2^i-1 范围内的 最大值 ,中间包含2^i个数 for(int i=1;i<=log2(n);i++){ // <<是移位运算符,1<<i相当于2^i for(int j=1;j+(1<<i)-1<=n;j++){ f[j][i]=max(f[j][i-1],f[j+(1<<(i-1))][i-1]); } } -
进行区间查询

找到一个值s,使得l+2 ^ s-1,尽可能接近r,r-2 ^ s+1尽可能接近l,两个区间的长度都是2 ^ s
最后比较两个区间的最大值,取较大的那个
max(f[l][s],f[r-(1<<s)+1][s]);
归并排序 稳定排序
时间复杂度O(nlogn) 空间复杂度O(n)
就是给定两个有序数组,将两个数组合并在一起升序。
定义一个更大的数组,给定两个指针分别指向两个数组,每次取较小值放入新数组。
//1.分离函数
void mergesort(int x,int y) //分离,x 和 y 分别代表要分离数列的开头和结尾
{
if (x>=y) return; //如果开头 ≥ 结尾,那么就说明数列分完了,分的只有一个数了,就返回
int mid=(x+y)/2; //将中间数求出来,用中间数把数列分成两段
mergesort(x,mid); //左右两端继续分离
mergesort(mid+1,y);
merge(x,mid,y); //分离玩之后就合并,升序排序,从最小段开始
}
//2.合并算法
void merge(int low,int mid,int high) //将两段的数据合并成一段,每一段数据都已经升序排序
{
int i=low,j=mid+1,k=low;
//i、j 分别标记第一和第二个数列的当前位置,k 是标记当前要放到整体的哪一个位置
while (i<=mid && j<=high) //如果两个数列的数都没放完,循环
{
if (a[i]<a[j])
b[k++]=a[i++]; //a[n](原始数组)和b[n](临时存数据的数组)为全局函数
else
b[k++]=a[j++]; //将a[i] 和 a[j] 中小的那个放入 b[k],然后将相应的标记变量增加
} // b[k++]=a[i++] 和 b[k++]=a[j++] 是先赋值,再增加
while (i<=mid)
b[k++]=a[i++];
while (j<=high)
b[k++]=a[j++]; //当有一个数列放完了,就将另一个数列剩下的数按顺序放好
for (int i=low;i<=high;i++)
a[i]=b[i]; //将 b 数组里的东西放入 a 数组,因为 b 数组还可能要继续使用
}
快速排序 不稳定排序
最差时间复杂度O(n^2) 和冒泡排序一样,平均时间复杂度O(n*log2n)
递归算法:
void sort(int* a,int l,int r){
if(l>r)return;
int i=l,j=r;
int std=a[l]; //最左端作为标准值 因为标准值是最左端的数,所以要先从右边开始找
while(i!=j){
while(a[j]>=std&&i<j){//从右往左 找到比标准小的数
j--;
}
while(a[i]<=std&&i<j){//从左往右 找到比标准大的数
i++;
}
if(j>i){ //交换找到的两个值
int t=a[i];
a[i]=a[j];
a[j]=t;
}
}
//退出循环表示i==j,将标准值换到i=j的地方,继续递归运行
a[l]=a[i];
a[i]=std;
sort(a,l,i-1);
sort(a,i+1,r);
}
快速选择查找 (基于快速排序)
可以用来查找第k小(大)的数,在快速排序每一轮确定基准值位置的时候判断是否是要选择的数
平均时间复杂度为O(n),最坏时间复杂度为O(n^2)
//快速选择排序算法
int quickChoose(int left,int right,int k){
if(left>right)return -1;
int i=left,j=right;
int std=num[left];
while(i!=j){
while(i<j&&num[j]>=std)j--;
while(i<j&&num[i]<=std)i++;
if(i<j){
int t=num[i];
num[i]=num[j];
num[j]=t;
}
}
num[0]=num[j];
num[j]=std;
if(k-1>j)quickChoose(j+1,right,k);//表示要查找的数在基准值位置的右边
if(k-1<j)quickChoose(left,j-1,k);//在基准值的左边
if(k-1==j)return num[k-1];//返回第k小(大)的值
}
桶排序
不基于比较的排序算法
通过统计值域内每个数据的个数,然后根据个数排序
int count[1002];//存放数的个数 这里数的值域是[0,1000]
void bucketSort(int n){
//统计每个数据的个数
for(int i=0;i<n;i++){
count[num[i]]++;
}
int cnt=0;
//值域为[0,1000]
for(int i=0;i<=1000;i++){
while(count[i]!=0){
num[cnt++]=i;//将数填回原数组
count[i]--;
}
}
}
堆排序(升序) 不稳定排序
时间复杂度 O(nlogn)
空间复杂度 O(1)
//对某个根节点调整为大根堆
//从上往下进行调整
void adjust_down(int *a,int n,int i){//i是需要调整的根节点的下标
int father=i;
int child=i*2+1;
while(child<n){
//比较孩子结点的大小,选出较大的那个
if((child+1)<=n-1&&a[child]<=a[child+1]) ++child;
//交换父节点和孩子结点,并顺着孩子结点向下继续调整
if(a[father]<a[child]){
int temp;
temp=a[child];
a[child]=a[father];
a[father]=temp;
father=child;
child=father*2+1;
}else{
//一旦不能继续调整就退出循环
break;
}
}
}
void heap_sort(int *a,int n){
//建立大根堆
//(n-1)/2为从后往前,第一个有孩子的结点
for(int i=(n-1)/2;i>=0;i--){
adjust_down(a,n,i);
}
//摘取大顶,与最后一个结点交换
for(int i=0;i<n-1;i++){
int temp=a[0];
a[0]=a[n-i-1];
a[n-i-1]=temp;
adjust_down(a,n-i-1,0);
}
}
并查集
一种树形的数据结构
主要构成 pre[]数组、find()、join()
作用:求图的连通分支数
//pre数组初始化
void Init(int n){
//每个结点的祖先都是自己
for(int i=0;i<n;i++){
pre[i]=i;
}
}
//pre[x]中存放的是x结点的父节点
//find()函数找到某个结点的根,结点的祖先
int find(int x) //查找某个结点的父节点
{
while(pre[x] != x)
x = pre[x];
return x;
}
find()函数优化:路径压缩。就是将所有结点的父节点都改为根结点,这样子查找某个结点的父节点只需要向上查找一次
int find(int x) //查找结点 x的根结点
{
if(pre[x] == x) return x; //递归出口:x的上级为 x本身,即 x为根结点
return pre[x] = find(pre[x]); //此代码相当于先找到根结点 rootx,然后pre[x]=rootx
}
//将两个集合合并
void join(int x,int y)
{
//找到各自的父节点
int fx=find(x);
int fy=find(y);
//将fy和fx其中任意一个作为根
if(fy!=fx)
pre[fy]=fx;
}
Kruskal算法--最小生成树
//并查集中的查找父节点函数
int find(int x){
if(pre[x] == x) return x;
return pre[x]=find(pre[x]);//路径压缩
}
struct edge{
int u;
int v;
int w;
};
edge a[M];//定义边的数组
//n是结点的个数,m是边的个数
int kruskal(int n,int m){
int cnt=0;//统计加入生成树的边的条数
for(int i=1;i<=m;i++){
//找到边的两个端点的父节点,判断是否会形成环
int father1=find(a[i].u);//find()函数,找到该节点对应的父节点(和哪些点连通) 具体见并查集
int father2=find(a[i].v);
//如果两个父节点相同,表示加入这条边会在图中形成环
if(father1==father2){
continue;
}else{
//表示可以加入图
pre[father1]=father2;//将两个结点的父节点相连(并查集中的合并操作)
ans+=a[i].w;//ans统计最小生成树的权值和
cnt++;
if(cnt==n-1)break;
}
}
//输出最小生成树的长度和
if(cnt==n-1){
cout<<ans;
}else{
cout<<"orz";//表示不是连通图,不能构成生成树
}
}
//测试函数
#include<iostream>
#include<algorithm>
using namespace std;
const int N=5100;
const int M=200050;
int pre[N];//并查集
int ans; //统计最小生成树的长度和
bool compareEdge(edge a1,edge a2){//伪函数
return a1.w<a2.w;//升序
}
int main(){
int n,m;
cin>>n>>m;
for(int i=1;i<=m;i++){
cin>>e[i].u>>e[i].v>>e[i].w;
}
sort(e+1,e+m+1,compareEdge);//排序
//初始化pre数组
for(int i=1;i<=n;i++){
pre[i]=i;
}
kruscal(n,m);
return 0;
}
红黑树
特征:
1.根节点是黑色的
2.红色结点和黑色结点交替
3.任意节点到叶子结点的路径包含相同数目的黑色结点 (红黑树中的叶子结点是指最外部的空结点)
多重邻接表(存储无向图)
十字链表(存储有向图)
AOV网(解决拓扑排序问题)---活动赋予顶点
方式:每次选出入度为0的结点
用邻接矩阵 时间复杂度 O(o^2)
用邻接表 时间复杂度 O(n+e)
哈希表平均查找长度
成功时:ASL=(所有元素查找成功的比较次数)/元素的个数
哈希函数为 H(key)=key mod p (p一般来说是一个质数,除留余数法)
不成功时:ASL=(0到p-1向后查找直到遇到空的比较次数)/p (不是除以数组本身大小)
全排列问题
深度优先搜索思想DFS :
int arrange[N];//存全排列的数组
int exist[N];//判断是否存在
void createArrange(int k,int n){//k是数组的位置,n是数的个数
if(k>n){
showArrange(n);//如果k>n表示所有数组位置都已经赋值,一次全排列情况结束,打印数组
return;
}else{
for(int i=1;i<=n;i++){
if(!exist[i]){
arrange[k]=i;//如果有没有被填入数组的数,就填入,然后标记已经选过
exist[i]=1;
createArrange(k+1,n);//进入递归
exist[i]=0;//当递归退出表示一次全排列结束,会返回上一层递归的位置,执行下面的语句,将当前的数标为
//还没有选过
arrange[k]=0;
}
}
}
}