引言
路漫漫其修远兮,吾将上下而求索。每天一篇论文,做更好的自己。
本文读的这篇论文为发表于2023年5月28日的一篇名为《基于融合语义信息改进的内容推荐算法》(基于融合语义信息改进的内容推荐算法)的文章,文章主要介绍了基于内容的推荐技术在电子商务和教育领域的广泛应用,以及传统基于内容推荐技术在语义分析方面的不足之处。为了改进传统算法的语义分析能力,本文提出了一种整合了语义信息的改进的内容推荐算法,并通过实验证明了该算法的有效性和稳定性。
摘要
Content-based recommendation technology is widely used in the field of e-commerce and education because of its intuitive and easy to explain advantages. However, due to the congenital defect of insufficient semantic analysis of TF-IDF vector space model, the traditional content-based recommendation technology has the problem of insufficient semantic analysis in item modeling, fails to consider the role of semantic information in knowledge expression and similarity calculation, and is not accurate enough in calculating item content similarity. The items with semantic relevance in content can not be well mined. The research goal of this paper is to improve the semantic analysis ability of the traditional content-based recommendation algorithm by integrating semantic information with TF-IDF vector space model for item modeling and similarity calculation and proposed an improved content recommendation algorithm integrating semantic information. In order to prove the effectiveness of the proposed method, several groups of experiments are carried out. The experiments results showed that the overall performance of the proposed algorithm in this paper is the best and relatively stable. This verified the validity of our method.
摘要翻译
基于内容的推荐技术在电子商务和教育领域得到广泛应用,因为它具有直观且易于解释的优势。然而,由于TF-IDF向量空间模型在语义分析方面的先天性缺陷,传统的基于内容推荐技术在项目建模中存在语义分析不足的问题,无法充分考虑语义信息在知识表达和相似度计算中的作用,并且在计算项目内容相似度时不够准确。因此,无法很好地挖掘出内容上具有语义相关性的项目。本文的研究目标是通过将语义信息与TF-IDF向量空间模型相结合,改进传统基于内容推荐算法的语义分析能力,并提出了一种改进的内容推荐算法,该算法整合了语义信息。为了证明所提出方法的有效性,进行了几组实验。实验结果表明,本文提出的算法在整体性能上表现最好且相对稳定。这验证了我们方法的有效性。
基于内容的推荐技术
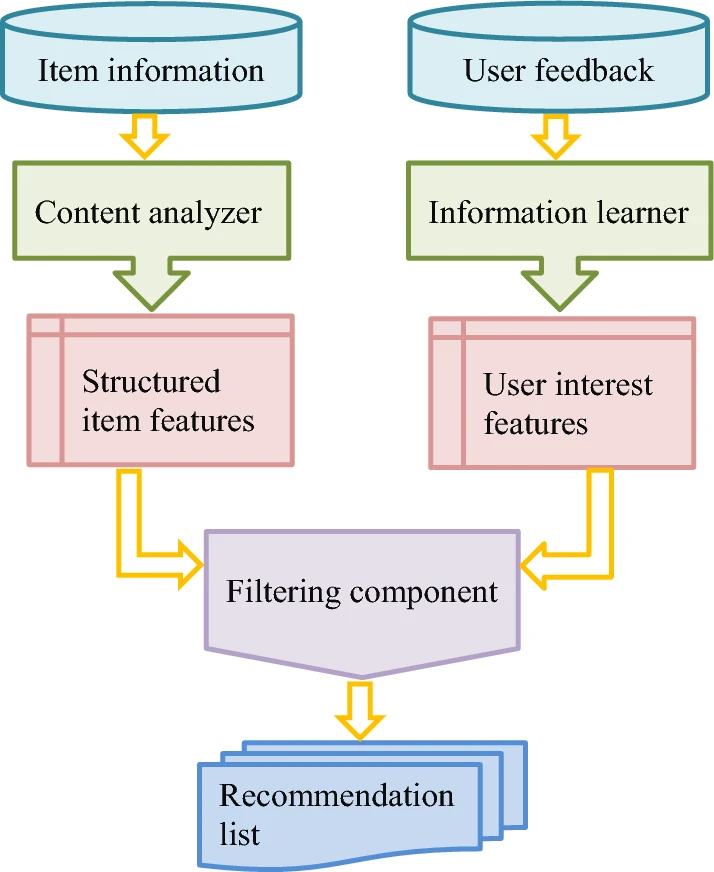
所谓基于内容的推荐算法(Content-Based Recommendations)是基于标的物相关信息、用户相关信息及用户对标的物的操作行为来构建推荐算法模型,为用户提供推荐服务。
简单来讲,基于内容的推荐算法的基本原理是根据用户的历史行为,获得用户的兴趣偏好,为用户推荐和他兴趣偏好相似的事物。
基于内容的推荐技术在电商和教育领域有很大应用,比如我们生活中很常用的一些电商平台,会根据用户的搜索来推荐用户可能会购买的事物;另外,在教育领域,课程网站或者APP会根据用户搜索观看的视频来对用户进行推荐,我们能够经常看到系统推荐给我们的信息。此外,基于内容的推荐技术还应用在娱乐、社交网络、新闻网站等领域。
传统基于内容的推荐技术的缺点
TF-IDF向量空间模型存在语义分析不足的先天缺陷,传统的基于内容的推荐技术在项目建模中存在语义分析不足的问题。它没有考虑语义信息在知识表达中的作用,对项目内容相似度的计算不够准确。内容中具有语义相关性的项目不能很好地挖掘。
下图为基于内容的推荐算法模型:
集成语义信息的改进内容推荐算法
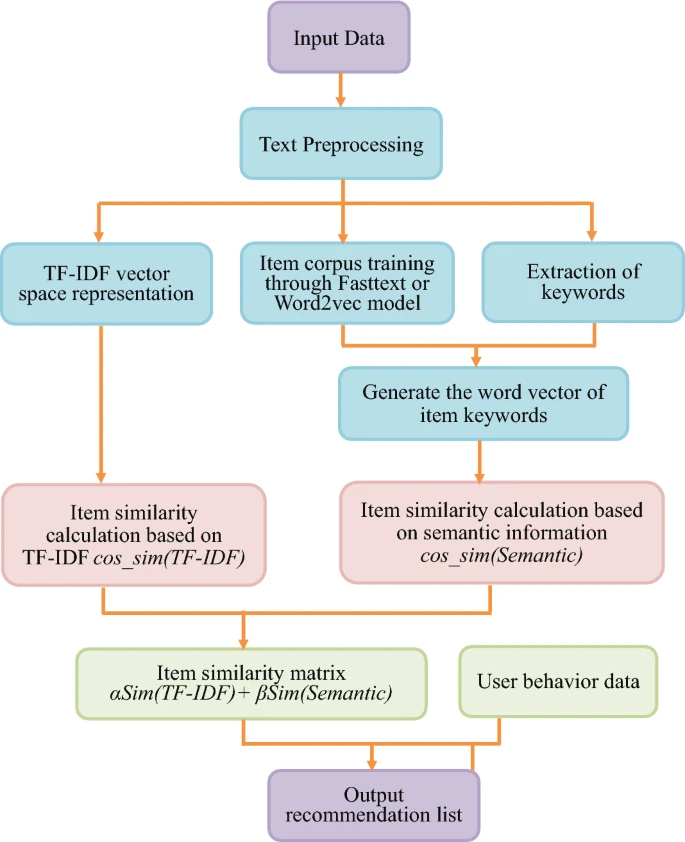
为解决传统的推荐技术的缺点,文章提出将语义信息与TF-IDF向量空间模型相结合,以此来改进传统的推荐技术的缺点。
词嵌入技术可以在一定程度上反映词的语义信息。单词之间的语义距离可以通过单词向量来计算。目前常用的词向量主要基于word2vec和fasttext模型。
Word2vec模型使用深度学习方法来获取单词的空间分布表示。它是一种语言模型,它以无监督的方式从海量文本语料库中学习富含语义信息的低维词向量。它是神经网络在自然语言处理领域应用的结果。Word2vec词向量模型将单词映射到低维空间,使语义相似的单词在空间中很接近。单词之间的语义相似性是通过计算单词向量之间的空间距离来表示的。
语义相似的特征词在空间分布上距离越近。然后,通过相似度计算或距离测量可以得到特征词之间的语义相关性。为了提高基于内容的推荐算法的语义分析缺陷和推荐准确率,将词嵌入技术与TF-IDF向量空间模型相结合,进行项目建模和相似度计算,提出了一种新的推荐算法。
下图为集成语义信息的改进内容推荐算法模型:
补充:TF-IDF
TF-IDF是一种统计方法,用来评估一个词语对一个文档的重要程度,一个词语在文档中出现的次数越多,则这个词语对这个文档而言更重要;而如果它在整个语料库中出现的次数越多,则它对这个文档越不重要。TF-IDF中的TF(Term Frequency)表示词频,IDF(Inverse Document Frequency)表示逆向文档频率。TF-IDF的计算公式如下:
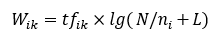
其中 表示词语i在文档中的权重, 表示词语在文档中的频率,N为总的文档数, 表示出现词语i的文档个数,L为一个常数,在很多应用场景中其实都忽略了L。
心得
在推荐算法中,基于内容的推荐在生活中非常常见,但问题是我们日常生活中的推荐算法大都存在准确度较差的问题,不管是基于协同的Top-N算法还是基于内容的推荐算法。事实上,如果推荐算法效果不够好的话,那么对于用户来说就是灾难而非福利,所以在推荐算法这方面还需要更多的研究,以带给用户不一样的体验。
写在最后
每日读一篇文章,虽然很艰难,但是有收获。坚持下去,加油,奥利给!
- 语义 recommendation 算法 integrating information语义recommendation算法integrating recommendation session-based information exploiting recommendation session-based information handling recommendation information sequential temporal top-n recommendation算法algorithms 语义 算法 深度 场景 前景展望 等分 语义 算法 integrating integrated integrate