一.背景
最近在Grafana关注到线上推送服务push-service在运行一段时间后,内存占用非常高,并且频繁发生FGC,这里记录下问题排查过程
二.排查过程
1. 首先在Grafana上的监控指标,可以看到FGC非常频繁,一小时内发生了多次FGC

2.进入容器内找到对应的服务实例,使用jmap 或者 arthas 可以看到对应实例的内存占用实际情框
--- jmap 查询过程
1.ps -ef 查看当前所有进程,找到对应服务名的进程pid
2.jmap -heap pid

--- arthas查询过程(注意在使用arthas分析内存导出dump日志时,尽量把当前服务实例下线,避免影响线上服务)
1.启动arthas,attach 到指定的Java进程
2.输入dashboard查询进程的内存和CPU等信息

3.这里以arthas 为例,导出内存快照文件
使用heapdump命令,导出文件

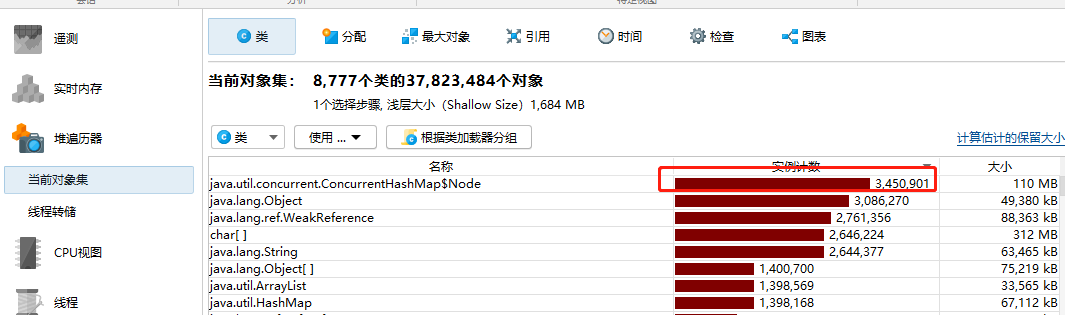
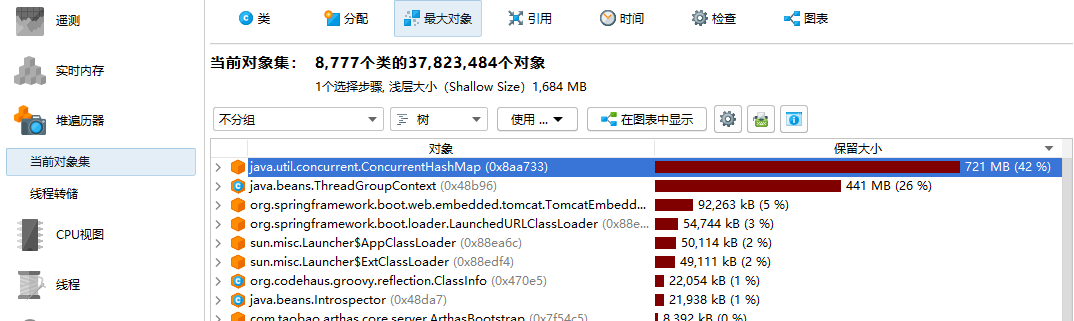
4.使用JProfile打开dump文件,如下图所示,可以看到HashMap$Node有340W个对象,且在最大对象图示中,占用了700M的内存空间,这里我们重点分析这个类
如下图,查看引用链,可以看到ConcurrentHashMap对象被SimpleViewResolver传递引用,表示SimpleViewResolver间接持有 ConcurrentHashMap对象,因此ConcurrentHashMap对象没有被回收掉

这里,我们可以就可以找到大致的出现内存泄漏的代码位置,找到SimpleViewResolver 和 SimpleTemplateEngine
最后跟踪源码,发现推送服务引入Groovy脚本框架,实现模板信息的缓存,但在实际上,每次推送时,根据模板ID查询模板信息后,即时模板缓存不存在,查询结果并没有缓存模板信息,导致GroovyClassLoader对象中的属性,每次查询都会生成一个HashMapNode对象,Map对象中的元素不断增加

5. 解决方案
方案1:在每次推送时,增加缓存的逻辑,这块是盖起来最快的方案,可以作为短期方案
方案2:修改Groovy脚本框架源码或使用新的缓存框架, 目前这块改造耗时较高,可以作为长期方案