TensorRT 概述
TensorRT 是由 Nvidia 发布的一个机器学习框架,用于在其硬件上运行机器学习推理。其能针对 Nvidia 系列硬件进行优化加速,实现最大程度的利用 GPU 资源,提升推理性能。在训练了神经网络之后,TensorRT 可以对网络进行压缩、优化以及运行时部署,并且没有框架的开销。
TensorRT 部署流程主要有以下五步:
- 训练模型
- 导出模型为 ONNX 格式
- 选择精度
- 转化成 TensorRT 模型
- 部署模型
主要难度在第二步、第四步和第五步。其中 ONNX 格式的导出和运行设备无关,可以在自己的电脑上导出,其他设备上使用。而第四步转化得到的 TensorRT 模型文件是和设备绑定的,在哪个设备上生成就只能在该设备使用。
一般来说,模型训练和导出 ONNX 都在服务器上进行,得到 ONNX 模型。TensorRT 模型转化和部署都是在实际设备上进行。这样的话实际设备不需要 PyTroch 环境,只需要配置好 TensorRT 环境即可。
YOLOv7 导出 ONNX 模型
Pytorch 导出 ONNX 文件注意事项
由于 ONNX 对很多 Pytorch 的操作的支持不好,若直接导出很容易失败。
即使成功导出,也会增加模型的复杂度 (可能会产生很多 Gather, Shape, ScatterND 等节点,使模型复杂,可视效果差),产生很多后续问题如 ONNX 模型转成 TensorRT 模型失败。
Pytorch 模型导出 ONNX 模型时需要注意以下几点:
- 对于任何用到
shape、size返回值的参数时,例如:tensor.view(tensor.size(0), -1)这类操作,避免直接使用tensor.size的返回值,而是加上int转换,如tensor.view(int(tensor.size(0)), -1) - 对于
nn.Upsample或nn.functional.interpolate函数,使用scale_factor指定倍率,而不是使用size参数指定大小 - 对于
reshape、view操作时,-1 的指定要放到batch维度。其他维度可以计算出来即可。batch维度禁止指定为大于-1 的明确数字。 - 导出时
opset_version不要低于 11
YOLOv7 源码修改
首先下载 yolov7 最新的源码:
git clone https://github.com/WongKinYiu/yolov7.git为了成功导出 yolov7 ONNX 模型,需要根据上述的注意事项修改 YOLOv7 的源码。
需要注意的是:下述的代码修改仅为了导出 ONNX 模型用于 TensorRT 部署,训练网络或者跑 detect.py 运行 demo 的时候需要改回来,否则会出错。
此外,YOLOv7 默认输出为三个不同尺度的张量,分别为不同层特征金字塔的检测结果,该输出需要结合锚框信息才能转化为预测框。
为了使用方便,我们希望在输出前就完成预测框的计算,并将这三个输出张量合并成一个。(参考 https://github.com/shouxieai/tensorRT_Pro )
修改 ./model/yolo.py 中的 Detect 类的 forward 函数如下:
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(-1, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
else:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
classif = y[..., 4:]
y = torch.cat([xy, wh, classif], -1)
z.append(y.view(-1, self.na * ny * nx, self.no))
if self.training:
out = x
elif self.end2end:
out = torch.cat(z, 1)
elif self.include_nms:
z = self.convert(z)
out = (z, )
else:
out = torch.cat(z, 1)
return out修改 ./model/yolo.py 中的 IDetect 类的 forward 和 fuseforward 函数如下:
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](self.ia[i](x[i])) # conv
x[i] = self.im[i](x[i])
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(-1, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
else:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
classif = y[..., 4:]
y = torch.cat([xy, wh, classif], -1)
z.append(y.view(-1, self.na * ny * nx, self.no))
return x if self.training else torch.cat(z, 1)
def fuseforward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = map(int, x[i].shape) # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
else:
xy = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i].view(1, self.na, 1, 1, 2) # wh
classif = y[..., 4:]
y = torch.cat([xy, wh, classif], -1)
z.append(y.view(-1, self.na * ny * nx, self.no))
if self.training:
out = x
elif self.end2end:
out = torch.cat(z, 1)
elif self.include_nms:
z = self.convert(z)
out = (z, )
else:
out = torch.cat(z, 1)
return out修改 ./export.py 文件如下:
import argparse
import sys
import time
sys.path.append('./') # to run '$ python *.py' files in subdirectories
import torch
import torch.nn as nn
import models
from models.experimental import attempt_load, End2End
from utils.activations import Hardswish, SiLU
from utils.general import set_logging, check_img_size
from utils.torch_utils import select_device
from utils.add_nms import RegisterNMS
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./yolor-csp-c.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size') # height, width
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--dynamic', action='store_true', help='dynamic ONNX axes')
parser.add_argument('--grid', action='store_true', help='export Detect() layer grid')
parser.add_argument('--end2end', action='store_true', help='export end2end onnx')
parser.add_argument('--max-wh', type=int, default=None, help='None for tensorrt nms, int value for onnx-runtime nms')
parser.add_argument('--topk-all', type=int, default=100, help='topk objects for every images')
parser.add_argument('--iou-thres', type=float, default=0.45, help='iou threshold for NMS')
parser.add_argument('--conf-thres', type=float, default=0.25, help='conf threshold for NMS')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--simplify', action='store_true', help='simplify onnx model')
parser.add_argument('--include-nms', action='store_true', help='export end2end onnx')
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
t = time.time()
# Load PyTorch model
device = select_device(opt.device)
model = attempt_load(opt.weights, map_location=device) # load FP32 model
labels = model.names
# Checks
gs = int(max(model.stride)) # grid size (max stride)
opt.img_size = [check_img_size(x, gs) for x in opt.img_size] # verify img_size are gs-multiples
# Input
img = torch.zeros(opt.batch_size, 3, *opt.img_size).to(device) # image size(1,3,320,192) iDetection
# Update model
for k, m in model.named_modules():
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatibility
if isinstance(m, models.common.Conv) or isinstance(m, models.common.RepConv): # assign export-friendly activations
if isinstance(m.act, nn.Hardswish):
m.act = Hardswish()
elif isinstance(m.act, nn.SiLU):
m.act = SiLU()
# elif isinstance(m, models.yolo.Detect):
# m.forward = m.forward_export # assign forward (optional)
model.model[-1].export = not opt.grid # set Detect() layer grid export
y = model(img) # dry run
if opt.include_nms:
model.model[-1].include_nms = True
y = None
# ONNX export
try:
import onnx
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
model.eval()
output_names = ['classes', 'boxes'] if y is None else ['output']
if opt.grid and opt.end2end:
print('\nStarting export end2end onnx model for %s...' % 'TensorRT' if opt.max_wh is None else 'onnxruntime')
model = End2End(model,opt.topk_all,opt.iou_thres,opt.conf_thres,opt.max_wh,device)
if opt.end2end and opt.max_wh is None:
output_names = ['num_dets', 'det_boxes', 'det_scores', 'det_classes']
shapes = [opt.batch_size, 1, opt.batch_size, opt.topk_all, 4,
opt.batch_size, opt.topk_all, opt.batch_size, opt.topk_all]
else:
output_names = ['output']
torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'],
output_names=output_names,
dynamic_axes={'images': {0: 'batch'}, # size(1,3,640,640)
'output': {0: 'batch'}} if opt.dynamic and not opt.end2end else None)
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
if opt.end2end and opt.max_wh is None:
for i in onnx_model.graph.output:
for j in i.type.tensor_type.shape.dim:
j.dim_param = str(shapes.pop(0))
if opt.simplify:
try:
import onnxsim
print('\nStarting to simplify ONNX...')
onnx_model, check = onnxsim.simplify(onnx_model)
assert check, 'assert check failed'
except Exception as e:
print(f'Simplifier failure: {e}')
# print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable model
onnx.save(onnx_model,f)
print('ONNX export success, saved as %s' % f)
if opt.include_nms:
print('Registering NMS plugin for ONNX...')
mo = RegisterNMS(f)
mo.register_nms()
mo.save(f)
except Exception as e:
print('ONNX export failure: %s' % e)
# Finish
print('\nExport complete (%.2fs). Visualize with https://github.com/lutzroeder/netron.' % (time.time() - t))导出 ONNX 模型
到 yolov7 源文件根目录下,运行
python export.py --grid --weight=./weights/yolov7-tiny-ft-best.pt --dynamic --img-szie 640 480此处需要把命令行参数中的weight部分改成自己的模型文件路径。img-size参数需要根据自己的输入图像来指定即可,即使使用默认的参数也没有关系,之后推理的时候有图像预处理的部分会将输入图像缩放、填充至模型输入的大小。
由于我们之后输入图像尺寸固定为640×480大小,直接指定模型输入大小与其一致可以减少后续推理时图像预处理和计算结果的后处理部分,节省算力。
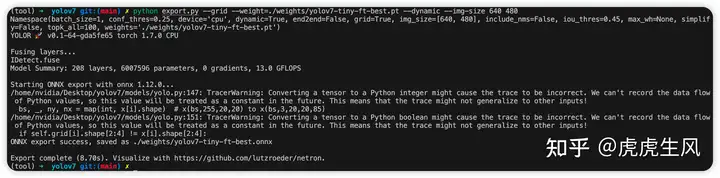
若导出成功,终端会有 ONNX export success 的提示,如上图。其中会有一些 warning,无需理会即可。导出成功,得到 yolov7-tiny-ft-best.onnx文件。
得到 onnx 模型之后,可以使用模型可视化工具 https://netron.app/ 进行可视化,如下:
可以看到经过我们代码修改后导出的模型文件就非常简洁、干净。
模型导出的 ONNX 文件是通用的,所以可以在任意设备上进行导出,在其他设备上使用。
TensorRT 模型推理(C++)
TensorRT C++ 模型推理我用了上述的 Github 仓库。该仓库也包含了 TensorRT Python 模型推理的源码。 对于 YOLO C++ 部署只需要下载文件夹 tensorRT_Pro/example-simple_yolo/即可。
该开源项目有以下优点
- 依赖少:仅依赖官方的 TensorRT 和 OpenCV
- 文件少:只有 simple_yolo.hpp 和 simple_yolo.cu 两个文件
- 使用方便:包含了ONNX 模型转 TRT 引擎,图像输入的预处理和后处理,集成了 NMS 非极大抑制算法,且封装简单,易于使用。
该仓库非常简单易用,根据其 ReadMe 文件操作即可。
实际使用,只需要修改下src/main文件主函数的参数

test函数最后一个参数为 ONNX 模型的文件名,- 比如
yolov7.onnx就输入yolov7即可 - 该 ONNX 模型文件需要放到可执行文件同目录下。
- 第二个参数为指定模型的运算精度
- 可以为
SimpleYolo::Mode::FP32或者SimpleYolo::Mode::FP16。 - 更低的运算精度部署后速度更快。
再修改下CMakeLists.txt文件,主要需要修改下面几个参数,对于 CUDA_GEN_CODE 参数,Jetson NX 和 Jetson AGX 都为"-gencode=arch=compute_72,code=sm_72"。
# 如果你是不同显卡,请设置为显卡对应的号码参考这里:https://developer.nvidia.com/zh-cn/cuda-gpus#compute
set(CUDA_GEN_CODE "-gencode=arch=compute_72,code=sm_72")
# 如果你的opencv找不到,可以自己指定目录
set(OpenCV_DIR "/usr/include/opencv4/")
set(CUDA_DIR "/usr/local/cuda-10.2")然后编译运行即可:
mkdir build
cd build
cmake ..
make -j8
cd ../workspace
./pro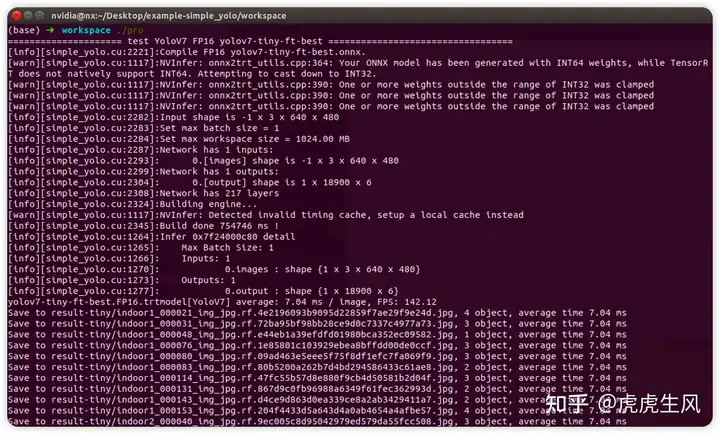
第一次运行时会将 onnx 文件转化为 tensorrt 引擎文件,需要很长时间(这里用了 13 分钟)。上面是我用我训练的yolo-tiny模型进行推理的耗时计算,前向传播检测一张 640×480 的图像耗时 7.04ms,完全达到实时性的要求。
TensorRT 部署前后运行时间对比
| 模型文件 | Jetson NX Pytorch | Jetson NX C++ TensorRT FP32 | Jetson NX C++ TensorRT FP16 |
| yolov7 | 226 ms / image | 136.17 ms / image | 46.17 ms / image |
| yolov7-tiny | 154 ms / image | 25.00 ms / image | 11.42 ms / image |