模型评估
模型评估是机器学习中非常重要的一部分,它可以帮助我们评估模型的好坏,从而选择最优的模型。
评估方式
在机器学习中,我们通常会将数据集划分为训练集和测试集,训练集用于训练模型,测试集用于评估模型的好坏。
评估指标
-
训练误差:模型在训练集上的误差,用于衡量模型在训练集上的拟合程度,训练误差越小,说明模型在训练集上的拟合程度越好。
-
测试误差:模型在测试集上的误差,用于衡量模型在测试集上的泛化能力,测试误差越小,说明模型在测试集上的泛化能力越好。
-
精确率:在所有预测为正例的样本中,预测正确的样本所占的比例;公式写作:\(P=\frac{TP}{TP+FP}\),其中,\(TP\)表示真正例,\(FP\)表示假正例。
-
召回率:在所有正例中,预测正确的样本所占的比例;公式写作:\(R=\frac{TP}{TP+FN}\),其中,\(TP\)表示真正例,\(FN\)表示假负例。
交叉验证
交叉验证误差
训练的模型会可能后有以下问题:
- 过拟合:模型在训练集上的拟合程度很好,但是在测试集上的泛化能力很差。(\(J_{train}(\theta)\)很小,\(J_{test}(\theta)\)很大)
- 欠拟合:模型在训练集上的拟合程度很差,但是在测试集上的泛化能力很好。(\(J_{train}(\theta)\)很大,\(J_{test}(\theta)\)很小)
在实际应用中,我们通常会将数据集划分为训练集、交叉验证集和测试集,训练集用于训练模型,验证集用于评估模型的好坏,测试集用于测试模型的泛化能力。
- 交叉验证误差:模型在交叉验证集上的误差,用于衡量模型在交叉验证集上的泛化能力
模型的选择
在实际应用中,我们通常会使用交叉验证误差来选择模型。选择交叉验证误差最小的模型。
偏差和方差
偏差和方差的定义
-
偏差:模型在训练集上的误差,用于衡量模型在训练集上的拟合程度,偏差越小,说明模型在训练集上的拟合程度越好;高偏差意味着欠拟合。
-
方差:模型在测试集上的误差,用于衡量模型在测试集上的泛化能力,方差越小,说明模型在测试集上的泛化能力越好;高方差意味着过拟合。
偏差和方差的关系
通过增加模型的复杂度,可以降低偏差,但是会增加方差;反之,通过减少模型的复杂度,可以降低方差,但是会增加偏差。
正则化
正则化的定义
正则化是一种降低模型复杂度的方法,它通过增加模型的约束,来降低模型的复杂度,从而降低方差,增加偏差。
正则化的公式如下:
其中,\(\lambda\)为正则化参数,用于控制正则化的程度。
正则化的优化
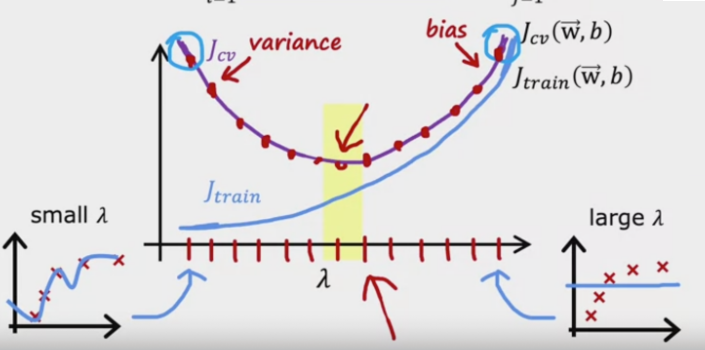
选择不同的\(\lambda\),会得到不同的偏差和方差:
- 较大的\(\lambda\),会得到较小的方差,较大的偏差:欠拟合
- 较小的\(\lambda\),会得到较大的方差,较小的偏差:过拟合

\(\lambda\)的选择
通过交叉验证误差选择\(\lambda\),选择交叉验证误差最小的\(\lambda\)。
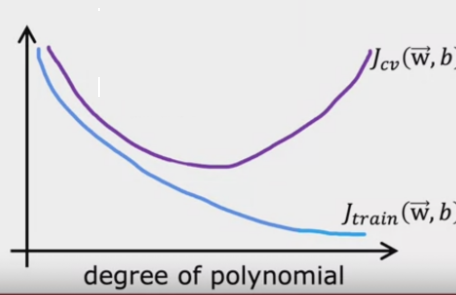
观察训练误差\(J_{train}(\theta)\)和交叉验证误差\(J_{cv}(\theta)\)的关系:
- 随着\(\lambda\)的增大,\(J_{train}(\theta)\)会增大,\(J_{cv}(\theta)\)会减小,
- 当\(\lambda\)取到一定值时,\(J_{cv}(\theta)\)会开始增大,这时的\(\lambda\)就是最优的\(\lambda\)。
为什么\(J_{cv}(\theta)\)会开始增大?
因为\(\lambda\)增大,会导致模型的复杂度降低,此时无论是训练集还是交叉验证集,都会出现欠拟合的情况,所以\(J_{cv}(\theta)\)会开始增大。
学习曲线
学习曲线的定义
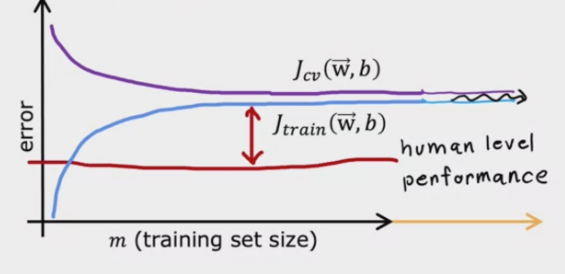
学习曲线是一种用于分析模型的方法,它通过绘制训练误差\(J_{train}(\theta)\)和交叉验证误差\(J_{cv}(\theta)\)的关系,来分析模型的偏差和方差。
在学习曲线中,横轴表示训练集的大小,纵轴表示误差。
-
高偏差:\(J_{train}(\theta)\)和\(J_{cv}(\theta)\)离基准误差很远,且两者之间的差距很小。
基准线的选择一般为人类水平,即人类在该问题上的表现
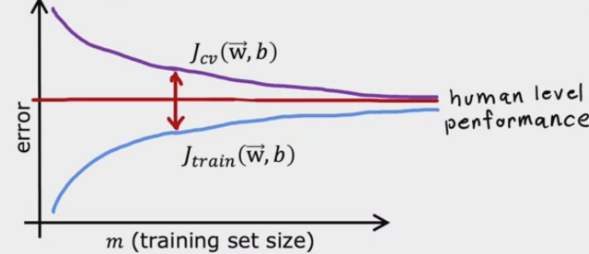
-
高方差:\(J_{train}(\theta)\)和\(J_{cv}(\theta)\)离基准误差很远,且两者之间的差距很大。
学习曲线的优化
- 高偏差:增加模型的复杂度,如增加多项式的次数,增加神经网络的层数,增加神经网络的隐藏层的神经元个数等。
- 高方差:增加训练集的大小,增加正则化参数\(\lambda\),减少神经网络的隐藏层的神经元个数等。
精确率和召回率
精确率和召回率的选择
对于学习算法,通常需要在精确度和召回率之间进行权衡。通过调整阈值,可以在这两者之间找到适当的平衡点。
F1值是精确率和召回率的调和平均值,它的公式如下:
阈值的调整
对于分类问题,我们通常会将模型的输出值与阈值进行比较,从而得到预测结果。如果我们希望精确率较高,则可以将阈值调高;如果我们希望召回率较高,则可以将阈值调低。
- 阈值较低:精确率较低,召回率较高
- 阈值较高:精确率较高,召回率较低
机器学习开发过程
机器学习开发循环迭代
- 确定系统的整体架构:模型、数据、超参数
- 实现并训练
- 诊断:偏差、方差、错误分析
- 优化:增加数据、增加模型复杂度、减少模型复杂度、调整超参数
错误分析
错误分析是一种用于评估模型性能并找出需要改进的地方的方法;通过错误分析,你可以了解哪些类型的错误更为常见,并据此确定哪些方向更值得关注。
错误分析的步骤
- 从开发集中选择一组错误分类的样本
- 分析这些样本的特点,找出共同点
- 根据这些共同点,改进模型
- 重复上述步骤
添加数据
-
针对性地添加数据:在进行错误分析时,我们可以发现模型在某些类型的数据上表现不好,此时我们可以针对性地添加这些类型的数据。
-
数据增强:对数据进行一些变换,如旋转、平移、缩放、裁剪等。
-
数据合成:通过一些方法,如GAN,来合成数据。
与数据增强的区别:数据合成是创建新的数据,数据增强是对原有数据进行变换
数据驱动
传统的机器学习研究方法主要集中在改进算法,而在许多情况下,现有的算法(如线性回归、逻辑回归、神经网络等)已经非常优秀。因此,更关注数据驱动方法,如收集更多特定类型的数据、使用数据增强和数据合成,可能是提升算法性能的更有效途径
迁移学习
迁移学习是一种将已学习的知识应用于新任务的方法,它可以将已学习的知识迁移到新任务中,从而加快新任务的学习速度。
迁移学习虽然并非所有任务都适用,但在许多情况下,它可以显著提高算法的性能。
迁移学习的定义
迁移学习使用一个预先训练好的模型,将其应用于新任务中,从而加快新任务的学习速度。
迁移学习的方法
- 仅训练输出层:将预先训练好的模型的输出层替换为新任务的输出层,然后仅训练输出层。
- 训练整个模型:将预先训练好的模型的参数作为新任务的初始参数,然后训练整个模型。
迁移学习的阶段
- 监督预训练:在大型数据集上训练模型上训练模型;
- 微调:在新任务上微调模型,即在新任务上训练模型;在大型数据集上训练模型,可以使模型具有较好的泛化能力,从而加快新任务的学习速度,有时只需要较小的数据集就可以训练出较好的模型。