目的:减少通信量(成本),例如VGGNet架构具有大约1.38亿个参数(4264 Mb)
方法:具有自动编码器压缩(Autoencoder Compression)且具有收敛保证(Convergence Guarantee);利用冗余信息(the redundant information)和FL的迭代纠错能力(iterative error-correcting capability of FL)来压缩client的模型,从而减少用户上传模型的通信成本。(适应资源受限、通信资源受限的用户设备:带宽小......)
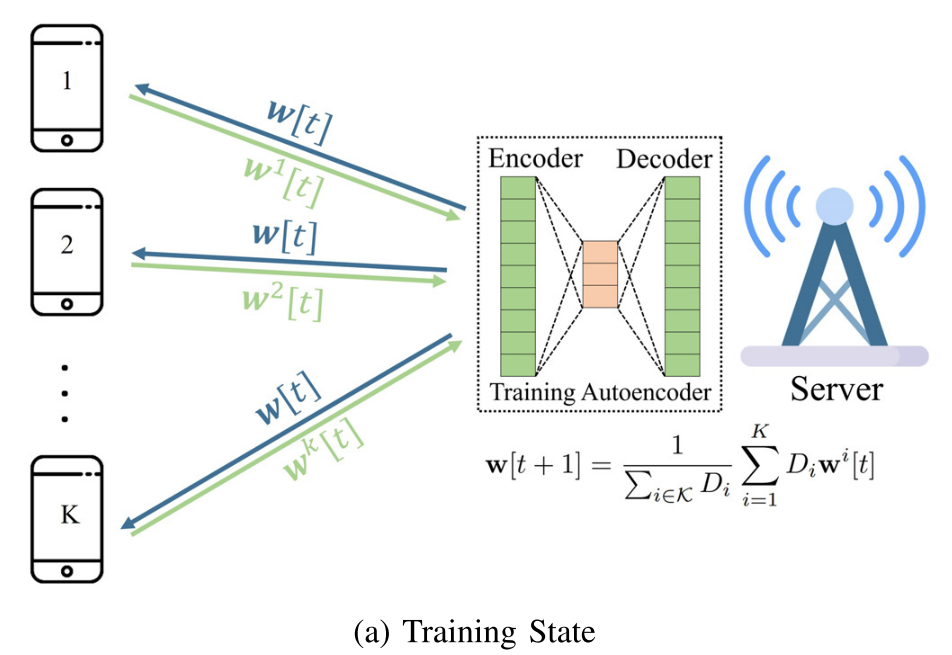
1. 在训练阶段,训练自动编码器以在服务器端对用户的模型进行编码(encode)和解码(decode)。
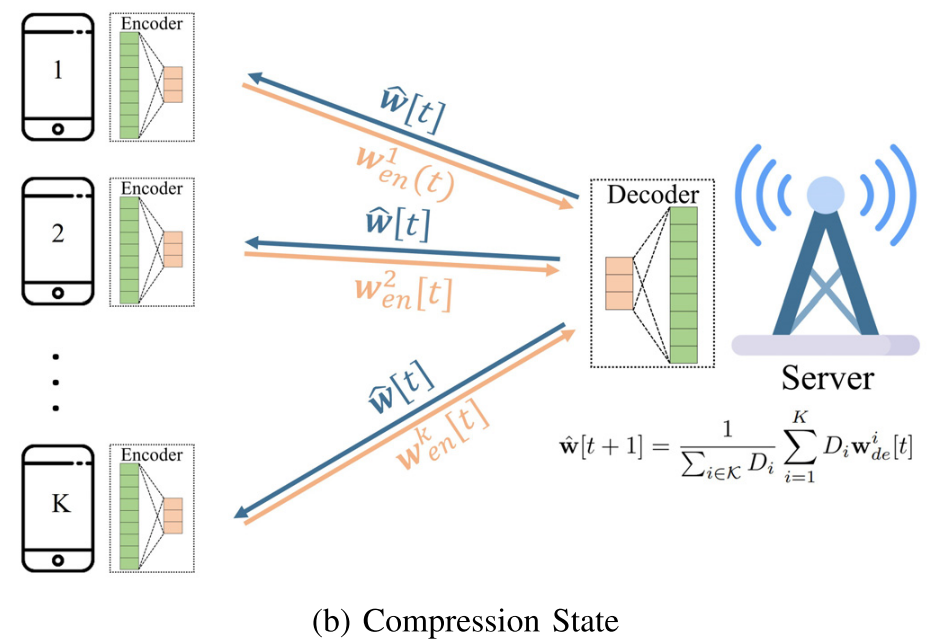
2. 在压缩阶段,将自动编码器发送给用户,用户通过自动编码器中的编码器压缩本地模型。服务器在利用解码器来解码用户压缩过的局部模型。以额外的计算成本为代价。
3. 为了保证FL的收敛,FLAC通过在训练状态和压缩状态之间切换来动态地控制自动编码器误差,以及,基于FL系统的误差容忍(error tolerance)(由学习率来确定)来调整其压缩率。
问题:在资源受限的网络上进行FL,通信问题是FL的根本瓶颈,从而限制了ML模型的复杂度和用户的参与。
直观:降低通信成本:显著方法:梯度压缩(gradient compression),目前有:①.稀疏化(sparsification)②.量化(quantization)是预先固定的方法,没有考虑模型参数、 client数据....以及训练过程中冗余信息(迭代次数.....)
一. 引言
·FL的纠错特性来自于用户使用的SGD算法是一个固有的噪声过程,SGD可以在每次迭代中补偿一些误差。
·FL的冗余信息特性是由于用户间数据的相关性,这也导致了FL的模型参数和迭代之间的相关性。

- Autoencoder Compression Convergence Federated Guaranteeautoencoder compression convergence federated guarantee convergence convergence operations dynamics platform retention guarantee场景 作用 autoencoder federated compression lstm-autoencoder semi-supervised autoencoder lncrna-disease associations autoencoder classifier