最近参加了手写ai的车道线检测项目, 后续会更新一些文章展现对相关项目邻域的总结和理解。
一 DETR的原理
DETR输出是定长的:100个检测框和类别。这种操作可能跟COCO评测的时候取top 100的框有关,从这种角度看,DETR可以被认为具有100个adaptive anchor,其中Encoder和Object Query分别对特征和Anchor进行编码,最后用Decoder+FFN得到检测框和类别。
这篇文章也从侧面说明100个Anchor完全够用。但是进一步想,100个Anchor其实也是有一些冗余输出的:很多图里面物体很少,并不能用完100个检测框吧。
当然定长的输出有利于显存对齐,训练的时候会方便一些。
二 DETR的结构
DETR的整体结构Transformer类似:Backbone得到的特征铺平,加上Position信息之后送到一堆Encoder里,得到一些candidates的特征。这100个candidates是被Decoder并行解码,以得到最后的检测框。这里如果是计算成本太高的话可以并行计算
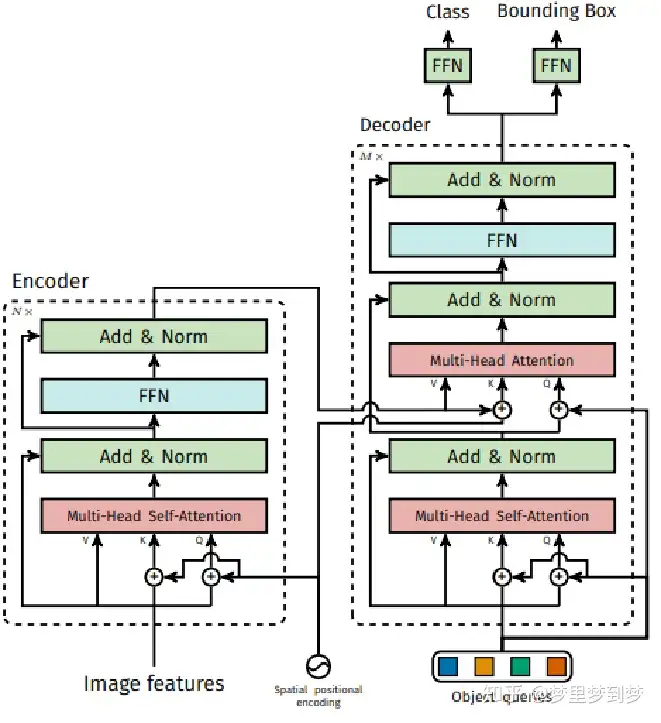
下面我们讲一下DETR中的Encoder、Decoder和Bipartite Matching。
2.1 DETR Encoder
网络一开始是使用Backbone(比如ResNet)提取一些feature,然后降维到d×HW。
Feature降维之后与Spatial Positional Encoding相加,然后被送到Encoder里。
为了体现图像在x和y维度上的信息,作者的代码里分别计算了两个维度的Positional Encoding,然后Cat到一起。
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3) pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3) pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)
FFN、LN等操作也与Transformer类似。Encoder最后得到的结果是对N个物体编码后的特征。
2.2 DETR Decoder
DETR Decoder的结构也与Transformer类似,区别在于Decode解码N个object。
每个Decoder有两个输入:一路是Object Query(或者是上一个Decoder的输出),另一路是Encoder的结果。
Object Query是一组nn.Embedding的weight(就是一组学到的参数)。另外一个与Transformer不同的地方是,DETR的Decoder也加了Positional Encoding。最后一个Decoder后面接了两个FFN,分别预测检测框及其类别。
2.3 Bipartite Matching
由于输出物体的顺序不一定与groud truth的序列相同,作者使用二元匹配将GT框与预测框进行匹配。其匹配策略如下:

最后的损失函数:
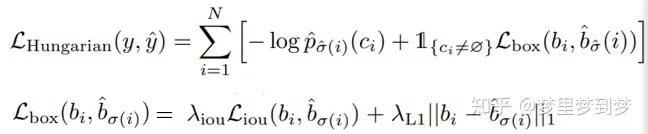
主要就是理解好其输入的query和位置编码模块,并且对decode部分熟悉就可以了。
三 总结
DETR利用transformer完成了端到端的目标检测,省去了proposal或者anchor,以及NMS。而是使用了100个object query和二分匹配算法(匈牙利匹配算法)完成了一对一的object预测。
优点:打破了传统的目标检测算法难部署,难适应不同数据集等缺点
缺点:训练时间长,收敛速度慢,需要500个epoch;对于小目标的检测性能低