目录
相较于传统目标检测,DETR是一种纯端到端的网络。它不再需要NMS(非极大值抑制,用于去除多余的预测框)和生成anchor。首先,使用一个CNN抽取图片的特征,将这个特征拉平并加入位置编码信息;其次,将拉平后的特征送入Transformer的encoder学全局特征;然后,由decoder调整object query生成100个预测框;最后,利用二分图匹配的方式将Ground Truth与预测结果进行匹配,对于匹配成功的框才会进一步计算loss(没有匹配成功的框将会被标记为背景)。
网络框架:

1. 用卷积神经网络抽特征
(1)按数据、标签取数据
class ConvertCocoPolysToMask(object):
def __init__(self, return_masks=False):
self.return_masks = return_masks
def __call__(self, image, target):
w, h = image.size#480*640
image_id = target["image_id"]
image_id = torch.tensor([image_id])#转换成tensor格式
anno = target["annotations"]#拿到标注数据
anno = [obj for obj in anno if 'iscrowd' not in obj or obj['iscrowd'] == 0]#只保留iscrowd == 0,就是单个目标没有重叠的
boxes = [obj["bbox"] for obj in anno]#bbox的格式是x y w h
# guard against no boxes via resizing
boxes = torch.as_tensor(boxes, dtype=torch.float32).reshape(-1, 4)
boxes[:, 2:] += boxes[:, :2]
boxes[:, 0::2].clamp_(min=0, max=w)
boxes[:, 1::2].clamp_(min=0, max=h)
#x y w h转换成x1y1 x2y2
classes = [obj["category_id"] for obj in anno]#当前每个框对应的类别
classes = torch.tensor(classes, dtype=torch.int64)#转换成tensor格式
if self.return_masks:#检测任务中不用msak
segmentations = [obj["segmentation"] for obj in anno]
masks = convert_coco_poly_to_mask(segmentations, h, w)
keypoints = None#该任务不涉及自带估计的内容,不执行
if anno and "keypoints" in anno[0]:
keypoints = [obj["keypoints"] for obj in anno]
keypoints = torch.as_tensor(keypoints, dtype=torch.float32)
num_keypoints = keypoints.shape[0]
if num_keypoints:
keypoints = keypoints.view(num_keypoints, -1, 3)
keep = (boxes[:, 3] > boxes[:, 1]) & (boxes[:, 2] > boxes[:, 0])#过滤掉如左上角小于右下角的(注意自己标注数据的时候可能出现的)
boxes = boxes[keep]
classes = classes[keep]
if self.return_masks:
masks = masks[keep]
if keypoints is not None:
keypoints = keypoints[keep]
target = {}#返回合适的值
target["boxes"] = boxes
target["labels"] = classes
if self.return_masks:
target["masks"] = masks
target["image_id"] = image_id
if keypoints is not None:
target["keypoints"] = keypoints
# for conversion to coco api
area = torch.tensor([obj["area"] for obj in anno])
iscrowd = torch.tensor([obj["iscrowd"] if "iscrowd" in obj else 0 for obj in anno])
target["area"] = area[keep]
target["iscrowd"] = iscrowd[keep]
target["orig_size"] = torch.as_tensor([int(h), int(w)])
target["size"] = torch.as_tensor([int(h), int(w)])
return image, target#返回做好的数据和标签
def __getitem__(self, idx):
img, target = super(CocoDetection, self).__getitem__(idx)#读入数据和标签
image_id = self.ids[idx]
target = {'image_id': image_id, 'annotations': target}#标签包括ID和标注数据
img, target = self.prepare(img, target)#图像预处理
if self._transforms is not None:
img, target = self._transforms(img, target)#数据增强115行
return img, target
(2)把数据做成序列
class PositionEmbeddingSine(nn.Module):#复现论文用正余弦编码位置
"""
This is a more standard version of the position embedding, very similar to the one
used by the Attention is all you need paper, generalized to work on images.
"""
def __init__(self, num_pos_feats=64, temperature=10000, normalize=False, scale=None):
super().__init__()
self.num_pos_feats = num_pos_feats
self.temperature = temperature
self.normalize = normalize
if scale is not None and normalize is False:
raise ValueError("normalize should be True if scale is passed")
if scale is None:
scale = 2 * math.pi
self.scale = scale
def forward(self, tensor_list: NestedTensor):
x = tensor_list.tensors
print(x.shape)#2*2048*26*25,batch,每个点的序列特征,H,W
mask = tensor_list.mask
print(mask.shape)#2*26*25每个位置是实际特征还是padding出来的,true表示实际的特征,false表示加的padding
assert mask is not None
not_mask = ~mask
y_embed = not_mask.cumsum(1, dtype=torch.float32)#行方向累加,最后一个值最大,便于做归一化。行方向列方向对应的ID转换为归一化后的结果
x_embed = not_mask.cumsum(2, dtype=torch.float32)#列方向累加
if self.normalize:
eps = 1e-6#防止分母为0
y_embed = y_embed / (y_embed[:, -1:, :] + eps) * self.scale#归一化
x_embed = x_embed / (x_embed[:, :, -1:] + eps) * self.scale#scale= 2 * math.pi,映射到角度中便于后续这正余弦
dim_t = torch.arange(self.num_pos_feats, dtype=torch.float32, device=x.device)#映射成128维向量,arange表示映射奇数/偶数维度
dim_t = self.temperature ** (2 * (dim_t // 2) / self.num_pos_feats)#执行三角函数公式
print(dim_t.shape)#128
pos_x = x_embed[:, :, :, None] / dim_t#拿到行embedding完的结果
pos_y = y_embed[:, :, :, None] / dim_t#拿到列embedding完的结果
pos_x = torch.stack((pos_x[:, :, :, 0::2].sin(), pos_x[:, :, :, 1::2].cos()), dim=4).flatten(3)#行执行三角函数公式
pos_y = torch.stack((pos_y[:, :, :, 0::2].sin(), pos_y[:, :, :, 1::2].cos()), dim=4).flatten(3)#列执行三角函数公式
pos = torch.cat((pos_y, pos_x), dim=3).permute(0, 3, 1, 2)#拼接行列结果
return pos
class Joiner(nn.Sequential):
def __init__(self, backbone, position_embedding):
super().__init__(backbone, position_embedding)
def forward(self, tensor_list: NestedTensor):
print(tensor_list.tensors.shape)
xs = self[0](tensor_list)#把输入数据经过resnet得到特征图
out: List[NestedTensor] = []
pos = []
for name, x in xs.items():
out.append(x)
# position encoding
pos.append(self[1](x).to(x.tensors.dtype))
return out, pos
(3)拉平特征
def forward(self, src, mask, query_embed, pos_embed):
# flatten NxCxHxW to HWxNxC
bs, c, h, w = src.shape
src = src.flatten(2).permute(2, 0, 1)#拉长最后一层的特征图并reshape
print(src.shape)#650,2,256----26*25=650个点,每个点是256维向量
pos_embed = pos_embed.flatten(2).permute(2, 0, 1)#拉长pos_embed并reshape
print(src.shape)#650,2,256----26*25=650个点,每个点是256维向量
query_embed = query_embed.unsqueeze(1).repeat(1, bs, 1)#decoder的时候用,如何找合适的100个向量
print(src.shape)#100,2,256
mask = mask.flatten(1)
print(src.shape)#2,650
tgt = torch.zeros_like(query_embed)#decoder的时候用,
print(src.shape)#100,2,256
memory = self.encoder(src, src_key_padding_mask=mask, pos=pos_embed)#传入序列,序列中哪些位置不需要算attention,位置编码
print(memory.shape)
hs = self.decoder(tgt, memory, memory_key_padding_mask=mask,
pos=pos_embed, query_pos=query_embed)
print(hs.transpose(1,2).shape)#6,2,100,256---decoder6次
print(memory.permute(1,2,0).view(bs,c,h,w).shape)#2,256,26,25
return hs.transpose(1, 2), memory.permute(1, 2, 0).view(bs, c, h, w)
2. 用Transformer Encoder去学全局特征
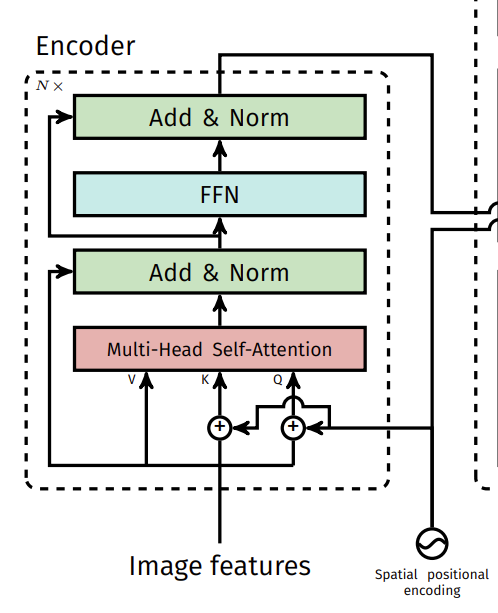
- 利用backbone做好的序列特征传入Encoder,自注意力机制在特征图上进行全局分析
def forward_post(self,
src,
src_mask: Optional[Tensor] = None,
src_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(src, pos)#只有K和Q加入了位置编码,并没有对V做,V只考虑提供了什么信息
print(q.shape)#650,2,256
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask,#传入q,k,特征图,attn_mask都是None,key_padding_mask表示序列当中哪些位置不需要计算attention,[0]表示只要特征图不要权重项
key_padding_mask=src_key_padding_mask)[0]#两个返回值,自注意力层的输出,自注意力权重,只需要第一个
print(src2.shape)#650,2,256
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
print(src2.shape)#650,2,256
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
3. 用Transformer Decoder调整object query生成100个预测框
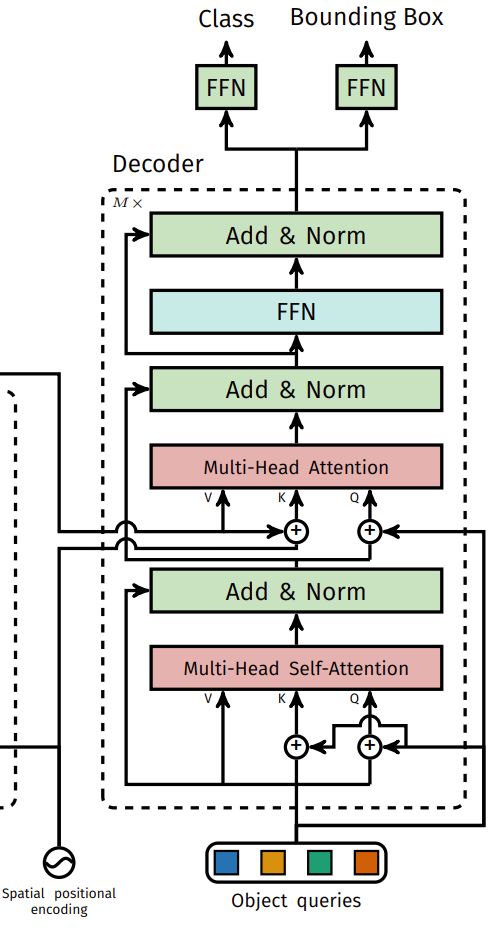
- query先自己做attention把向量做的更好,再用100个q在encoder中做好的k,v中去查图片的每个点是不是包含物体。
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos)#刚开始q为0,没进行学习,经过self-attention和attention(与encoder的)后有值
print(q.shape)#100,2,256
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]#和encoder不同,自己做attention把向量做的更好
print(tgt2.shape)#100,2,256
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
print(memory.shape)#650,2,256
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos),#decoder自己做好的query
key=self.with_pos_embed(memory, pos),#key用encoder编好的memory
value=memory, attn_mask=memory_mask,#value用encoder编好的memory
key_padding_mask=memory_key_padding_mask)[0]
print(q.shape)#100,2,256
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
print(tgt.shape)#100,2,256--100个query,每个对应256维向量
return tgt
4. 二分图匹配和损失函数
- 分类损失,回归损失,框大小的损失
class HungarianMatcher(nn.Module):
#This class computes an assignment between the targets and the predictions of the network
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1):
"""Creates the matcher
super().__init__()
self.cost_class = cost_class
self.cost_bbox = cost_bbox
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0"
@torch.no_grad()
def forward(self, outputs, targets):
""" Performs the matching
len(index_i) = len(index_j) = min(num_queries, num_target_boxes)
"""
bs, num_queries = outputs["pred_logits"].shape[:2]#batch为2,每个数据100个框
# We flatten to compute the cost matrices in a batch
out_prob = outputs["pred_logits"].flatten(0, 1).softmax(-1) #预测的分类结果[batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # 预测的回归的结果[batch_size * num_queries, 4]
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])#取标签的ID
tgt_bbox = torch.cat([v["boxes"] for v in targets])#取标签的BBOX
# Compute the classification cost. Contrary to the loss, we don't use the NLL,
# but approximate it in 1 - proba[target class].
# The 1 is a constant that doesn't change the matching, it can be ommitted.
cost_class = -out_prob[:, tgt_ids]
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
# Compute the giou cost betwen boxes
cost_giou = -generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))#计算框的大小比例是否合适
# Final cost matrix分类损失,回归损失,框大小的损失,分配权重项
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
C = C.view(bs, num_queries, -1).cpu()
sizes = [len(v["boxes"]) for v in targets]
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]
return [(torch.as_tensor(i, dtype=torch.int64), torch.as_tensor(j, dtype=torch.int64)) for i, j in indices]
def forward(self, outputs, targets):
""" This performs the loss computation.
Parameters:
outputs: dict of tensors, see the output specification of the model for the format
targets: list of dicts, such that len(targets) == batch_size.
The expected keys in each dict depends on the losses applied, see each loss' doc
"""
outputs_without_aux = {k: v for k, v in outputs.items() if k != 'aux_outputs'}
# Retrieve the matching between the outputs of the last layer and the targets
indices = self.matcher(outputs_without_aux, targets)#算索引的对应,计算哪些是实际的物体并与框一一对应,100个框除了物体的框,其余做背景
# Compute the average number of target boxes accross all nodes, for normalization purposes
num_boxes = sum(len(t["labels"]) for t in targets)
num_boxes = torch.as_tensor([num_boxes], dtype=torch.float, device=next(iter(outputs.values())).device)
if is_dist_avail_and_initialized():
torch.distributed.all_reduce(num_boxes)
num_boxes = torch.clamp(num_boxes / get_world_size(), min=1).item()
# Compute all the requested losses分类损失,回归损失,框大小的损失
losses = {}
for loss in self.losses:
losses.update(self.get_loss(loss, outputs, targets, indices, num_boxes))
# In case of auxiliary losses, we repeat this process with the output of each intermediate layer.
if 'aux_outputs' in outputs:
for i, aux_outputs in enumerate(outputs['aux_outputs']):
indices = self.matcher(aux_outputs, targets)
for loss in self.losses:
if loss == 'masks':
# Intermediate masks losses are too costly to compute, we ignore them.
continue
kwargs = {}
if loss == 'labels':
# Logging is enabled only for the last layer
kwargs = {'log': False}
l_dict = self.get_loss(loss, aux_outputs, targets, indices, num_boxes, **kwargs)
l_dict = {k + f'_{i}': v for k, v in l_dict.items()}
losses.update(l_dict)
return losses