tensorrt yolov7 yolov
ubuntu20.04 安装 cuda11.8 + cuDNN v8.9.0 (July 11th, 2023), for CUDA 11.x + TensorRT-8.6.1
根据文档:https://docs.nvidia.com/deeplearning/tensorrt/archives/tensorrt-861/install-guide/index.html TensorRT 8.6.1 支持:cuda11.8, cuDNN v8.9.0 ### 1. 安装 c ......
基于YoloV8的人体骨架提取代码编写时遇到的问题
# 1、获取骨架端点的xy轴位置 在最初进行编写的时候,我借鉴了网上的代码,其中出现最多的便是`bboxes_keypoints = results[0].keypoints.cpu().numpy().astype('uint32')`,但是实际运行时往往会报错`AttributeError: ' ......
TensorRT 模型加密杂谈
在大多数项目交付场景中,经常需要对部署模型进行加密。模型加密一方面可以防止泄密,一方面可以便于模型跟踪管理,防止混淆。 由于博主使用的部署模型多为TensorRT格式,这里以TensorRT模型为例,讲解如何对模型进行加密、解密以及推理加密模型。 ## 加密算法的选择和支持的库 [Crypto++] ......
yolov5实战
[TOC] > 本文使用NEU-DET数据集和yolov5算法对钢材表面的六种常见缺陷进行检测。 ### 1.处理数据 #### (1)读入数据和标签 展开代码 ``` python class LoadImagesAndLabels(Dataset): # for training/testing ......
Yolov3--Darknet53实战
[TOC] > Yolov3取消池化和全连接层,全部由53个卷积层组成,又名Darknet53,采用多scale,每个scale包含三种候选框,对不同的特征图进行融合后再预测(感受野大的上采样后与感受野相对较小的融合)。利用coco数据集对模型进行训练,最后返回物体所在位置以及物体的类别(回归和分类 ......
v831-c-yolov2例程解析
没错,自从把ubuntu搞坏之后无奈把之前的例程全删了,因此所有的笔记都没了,又得从新分析一遍 main函数 先从最简单的main分析 此函数主要创建一个屏幕句柄用来显示,然后调用nn_test来开始yolov2的操作,并且传入画布,显示等都在里面操作,最后跳出来后摧毁屏幕 nn_test函数 此函 ......
YOLOv5目标检测模型
# YOLOv5目标检测模型 ## 环境配置 ##### 1、安装Anaconda 打开命令行输入conda -V检验是否安装及当前conda的版本 ##### 2、conda常用的命令 1)conda常用的命令 ~~~python conda list ~~~ 2)查看当前存在哪些虚拟环境 ~~~ ......
ubuntu22.04 cuda cudnn tensorRT安装
1:查看当前安装驱动版本信息 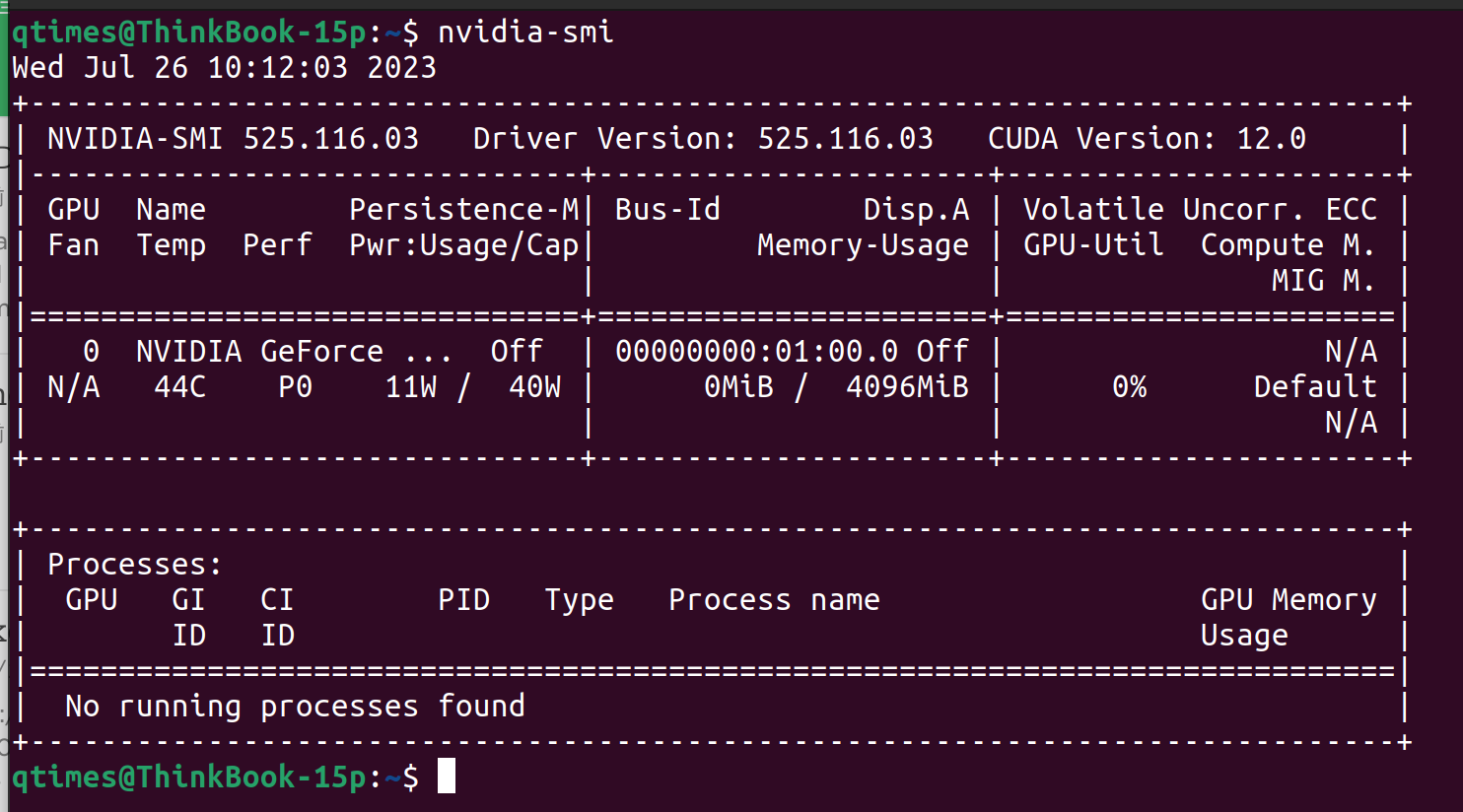 driver version: 525.116.03 cuda version: 12 ......
YOLOv6在LabVIEW中的推理部署(含源码)
# 前言 YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。如何使用python进行该模型的部署,官网已经介绍的很清楚了,但是对于如何在LabVIEW中实现该模型的部署,笔者目前还没有看到相关介绍文章,所以笔者在实现YOLOv6 ONNX 在LabVIEW中的部署推理后,决定和各 ......
YOLOV8模型训练+部署
1、YOLOV8简介 YOLOV8是YOLO系列另一个SOTA模型,该模型是相对于YOLOV5进行更新的。其主要结构如下图所示: 从图中可以看出,网络还是分为三个部分: 主干网络(backbone),特征增强网络(neck),检测头(head) 三个部分。 主干网络: 依然使用CSP的思想,改进之处 ......
CPU环境下运行基于yolov5的行人检测代码(pedestrain detection based on yolov5 in CPU)
最近在捣腾基于 yolov5 的行人检测代码,在 github 上下载一个案例之后因为没用 GPU 运行一直碰壁,出现了许多 bug,现在整理了下 error 和解决方法,成功调试出了基于 yolov5 的行人检测代码,分享给大家~ 1. 运行环境:window10,CPU,Visual Studi ......
LLM + TensorRT 采坑记录
TensorRT的使用,尝试对LLM进行加速。本文为采坑记录 环境:ubuntu20.04, cuda 12.2, pytorch 2.0.1, tensorrt 8.6.1, torch_tensorrt 1.4.0, transformer 0.6.0 设备有限,仅打算尝试[opt-1.3b]( ......
ubuntu 22.04离线安装cuda 11.7.1、cudnn 8.9.3.28、nccl 2.18.3、tensorrt 8.6.1
最近在使用飞桨OCR,有几个特殊的符号需要进行识别,手上只有两台机器,一台1080TI单卡(windows 11),一台1080Ti双卡(linux 22.04),习惯性追新到飞桨最高支持的cuda11.7,其实1080Ti到cuda10就够用了,后面的新版本差没有明显的性能提升。 windows上 ......
yolov5环境配置
基本配置: 操作系统:windows10IDE:Pycharmpython版本:anaconda Pyhon3.8pytorch版本:torch 1.10.0cuda版本:11.3显卡:RTX 2060 super ①安装pytorch-gpu版本 下载离线安装包,地址:https://downlo ......
yolov5 目标检测代码
import torch import cv2 import time import os box_color = (0, 255, 0) def get_milsecond(): t = time.time() return (int(round(t * 1000))) if __name__ = ......
机器学习 - Torch-TensorRT 推理加速
# 机器学习 - Torch-TensorRT 推理加速 Torch-TensorRT 作为 TorchScript 的扩展。 它优化并执行兼容的子图,让 PyTorch 执行剩余的图。 PyTorch 全面而灵活的功能集与 Torch-TensorRT 一起使用,解析模型并将优化应用于图的 Ten ......
yolov5的训练策略
yolov5——训练策略 前言 1. 训练预热——Warmup 1.1 what是Warmup 1.2 why用Warmup 1.3 常见Warmup类型 1.4 yolov5中的Warmup 2. 自动调整锚定框——Autoanchor 2.1 what是anchor 2.2 why用anchor ......
YOLOv5中的Focus层
一、背景介绍 Focus层是在YOLOv5中被提出来的。感觉像是一种特殊的下采样的方式。 1.下采样 下采样就是一种缩小图像的手法,用来降低特征的维度并保留有效信息,一定程度上避免过拟合,都是以牺牲部分信息为代价,换取数据量的减少。下采样就是池化操作。但是池化的目的不仅如此,还需要考虑旋转、平移、伸 ......
YOLOv5/YOLOV4中的SPP/SPPF
目录 一、SPP的应用的背景 二、SPP结构分析 三、SPPF结构分析 四、YOLOv5中SPP/SPPF结构源码解析(内含注释分析) 一、SPP的应用的背景 在卷积神经网络中我们经常看到固定输入的设计,但是如果我们输入的不能是固定尺寸的该怎么办呢? 通常来说,我们有以下几种方法: (1)对输入进行 ......
yolov5中的图片自适应缩放
自适应图片缩放-针对不同的目标检测算法而言,我们通常需要执行图片缩放操作,即将原始的输入图片缩放到一个固定的尺寸,再将其送入检测网络中。YOLO 系列算法中常用的尺寸包括416 * 416,608 * 608 等尺寸。 原始的缩放方法存在着一些问题,因为在实际的使用中的很多图片的长宽比不同,所以在进 ......
yolov5的自适应锚框讲解
现在网路上关于yolov5的自适应锚框策略都是一笔带过,今天专门来说一下这个 像之前的 YOLOv3、YOLOv4,对于不同的数据集,都会计算先验框 anchor。然后在网络训练时,网络会在 anchor 的基础上进行预测,然后输出预测框,再和标签框进行对比,最后就进行梯度地反向传播。 在 YOLO ......
TensorRT源码编译
[toc] # 1.参考资料 tensorrt编译 https://zhuanlan.zhihu.com/p/346307138 tensorrt相关指南 https://zhuanlan.zhihu.com/p/382728131 使用 TensorRT 加速深度学习推理 https://deve ......
yolov5中的s,m,l,x表示什么意思
在YOLOv5中,S、M、L、X是用来表示不同的检测器尺寸或大小的标签。它们指的是YOLO检测器的不同变体,其主要区别在于其基础网络架构和输入图像的分辨率。 以下是它们的具体含义: 1. YOLOv5s(Small):这是YOLOv5中的最小尺寸变体。它具有相对较小的模型尺寸和输入图像分辨率,适用于 ......
Yolov8
论文:还没发布 ultralytics官方测试的精度,与v5,v6比较 从官方给的精度看v8比v6在相同型号的模型下,v8比v6精度更高高,参数更少,计算量更少,例如S型号 整体框架 yolov8主要改进之处: 网络结构: 骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 ......
yolov5-训练好的模型部署的几种方式-ONNX
ONNX,即 Open Neural Network Exchange ,是微软和 Facebook 发布的一个深度学习开发工具生态系统,旨在让 AI 开发人员能够随着项目发展而选择正确的工具。 ONNX 所针对的是深度学习开发生态中最关键的问题之一,在任意一个框架上训练的神经网络模型,无法直接在另 ......
yolov5实战之模型剪枝
续[yolov5实战之二维码检测](https://www.cnblogs.com/haoliuhust/p/15362819.html) [toc] # 前沿 在上一篇yolov5的博客中,我们用yolov5训练了一个二维码检测器,可以用来检测图像中是否有二维码,后续可以接一个二维码解码器,就可以 ......
如何使用YOLOv8训练自己的模型和进行预测
# 如何使用YOLOv8训练自己的模型和进行预测 ## 准备文件夹 删除重复的照片。然后以图片采集的日期新建一个文件夹,如“2023.6.19”,并在其中新建一个名为VOCdevkit的文件夹,VOCdevkit里面创建一个名为JPEGImages的文件夹存放需要打标签的图片文件;再创建一个名为An ......
Yolov5代码解析(输入端、BackBone、Neck、输出端))
【深度学习】总目录 输入端:数据增强、锚框计算等。 backbone:进行特征提取。常用的骨干网络有VGG,ResNet,DenseNet,MobileNet,EfficientNet,CSPDarknet 53,Swin Transformer等。(其中yolov5s采用CSPDarknet 53 ......
yolov7
论文:《YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors》2022.7 CVPR 整体框架 在本文复现的yolo7版本 下图是yolov7的网络结构图(来自一位b站up ......
opencv与tensorrt安装
opencv安装参考: https://blog.csdn.net/wxyczhyza/article/details/128968849 tensorrt安装: sudo tar -xvf TensorRT-8.5.1.7.Linux.x86_64-gnu.cuda-11.8.cudnn8.6.t ......